En Breve (TL;DR)
La arquitectura Data Lakehouse unifica datos estructurados y documentos complejos como PDF en un único entorno cloud eficiente y económico.
BigQuery y Document AI permiten consultar archivos brutos vía SQL, transformando procesos manuales en pipelines automatizados e inteligentes.
Esta estrategia pone en valor los Dark Data financieros, ofreciendo a los CTO una gestión unificada para análisis predictivos y operativos en tiempo real.
El diablo está en los detalles. 👇 Sigue leyendo para descubrir los pasos críticos y los consejos prácticos para no equivocarte.
En el panorama financiero actual, y en particular en el sector hipotecario, el verdadero valor no reside solo en las bases de datos estructuradas, sino en una mina de oro a menudo inutilizada: los documentos no estructurados. Nóminas, tasaciones inmobiliarias, escrituras notariales y documentos de identidad constituyen lo que a menudo se define como Dark Data. El desafío para los CTO y los Data Architect en 2026 ya no es solo archivar estos archivos, sino hacerlos consultables en tiempo real junto con los datos transaccionales.
En este artículo técnico, exploraremos cómo diseñar e implementar una arquitectura data lakehouse google cloud capaz de derribar los silos entre el data lake (donde residen los PDF) y el data warehouse (donde residen los datos CRM). Utilizaremos la potencia de BigQuery, la inteligencia de Document AI y las capacidades predictivas de Vertex AI para transformar un proceso de instrucción manual en un pipeline automatizado y seguro.

El Paradigma Data Lakehouse en Fintech
Tradicionalmente, los bancos mantenían dos stacks separados: un Data Lake (ej. Google Cloud Storage) para los archivos brutos y un Data Warehouse (ej. bases de datos SQL legacy o primeros MPP) para la Business Intelligence. Este enfoque conllevaba duplicación de datos, latencia elevada y desalineación de la información.
El Data Lakehouse en Google Cloud Platform (GCP) resuelve este problema permitiendo tratar los archivos almacenados en el almacenamiento de objetos como si fueran tablas de una base de datos relacional, manteniendo sin embargo los costes bajos del almacenamiento y el rendimiento elevado del warehouse.
Componentes Clave de la Arquitectura
- Google Cloud Storage (GCS): El nivel de almacenamiento físico para los documentos (PDF, JPG, TIFF).
- BigQuery (BQ): El corazón del Lakehouse. Gestiona tanto los datos estructurados (CRM) como los metadatos de los archivos no estructurados mediante Object Tables.
- Document AI: El servicio de procesamiento inteligente de documentos (IDP) para extraer entidades clave.
- Vertex AI: Para el entrenamiento de modelos de credit scoring basados en los datos unificados.
Fase 1: Diseño de la Arquitectura e Ingesta
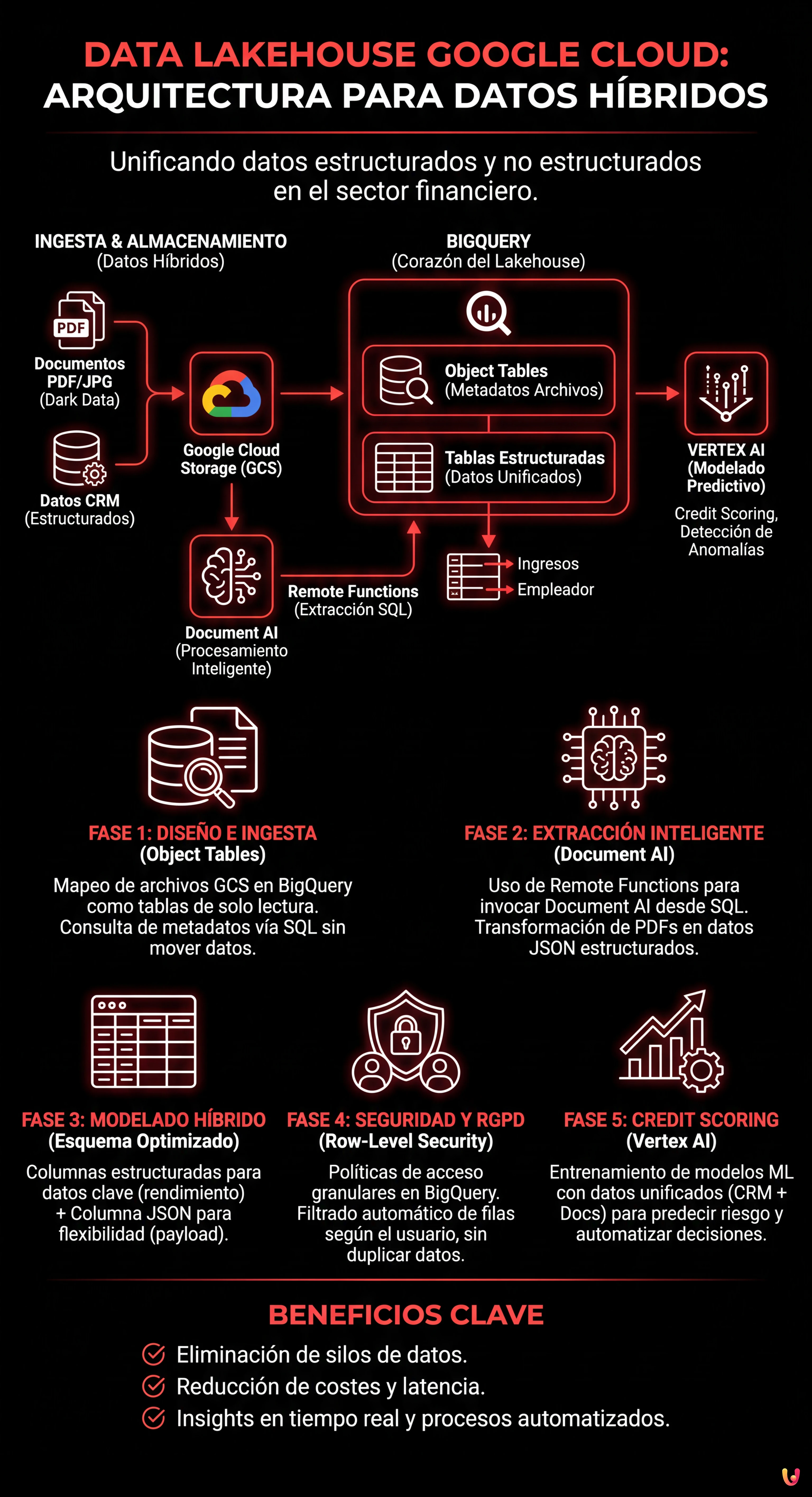
El primer paso para construir un data lakehouse google cloud eficaz es estructurar correctamente el nivel de ingesta. No estamos simplemente cargando archivos; estamos preparando el terreno para el análisis.
Configuración de las Object Tables en BigQuery
A partir de las actualizaciones recientes de GCP, BigQuery permite crear Object Tables. Estas son tablas de solo lectura que mapean los archivos presentes en un bucket GCS. Esto nos permite ver los PDF de las nóminas directamente dentro de BigQuery sin moverlos.
CREATE OR REPLACE EXTERNAL TABLE `fintech_lakehouse.raw_documents`
WITH CONNECTION `us.my-connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://mutui-docs-bucket/*.pdf']
);Con esta única instrucción SQL, hemos hecho accesible nuestro archivo documental vía SQL. Podemos consultar los metadatos (fecha de creación, tamaño, nombre del archivo) como si fueran columnas estructuradas.
Fase 2: Extracción Inteligente con Document AI y Remote Functions

Tener los archivos listados en BigQuery no es suficiente. Debemos leer su contenido. Aquí entra en juego la integración entre BigQuery y Document AI mediante las Remote Functions (Funciones Remotas).
En lugar de construir complejos pipelines ETL con Dataflow o scripts Python externos, podemos invocar el modelo de extracción directamente desde una consulta SQL. Imaginemos que tenemos que extraer los “Ingresos Netos” y el “Empleador” de las nóminas.
1. Creación del Procesador Document AI
En la consola GCP, configuramos un procesador Lending Document Splitter & Parser (específico para el sector hipotecario) o un procesador Custom Extractor entrenado con las nóminas específicas.
2. Implementación de la Remote Function
Creamos una Cloud Function (Gen 2) que actúa como puente. Esta función recibe la URI del archivo desde BigQuery, llama a la API de Document AI y devuelve un objeto JSON con las entidades extraídas.
3. Extracción vía SQL
Ahora podemos enriquecer nuestros datos brutos transformándolos en información estructurada:
CREATE OR REPLACE TABLE `fintech_lakehouse.extracted_income_data` AS
SELECT
uri,
remote_functions.extract_entities(uri) AS json_data
FROM
`fintech_lakehouse.raw_documents`
WHERE
content_type = 'application/pdf';El resultado es una tabla que contiene el enlace al documento original y una columna JSON con los datos extraídos. Este es el verdadero poder del data lakehouse google cloud: datos no estructurados convertidos en estructurados sobre la marcha.
Fase 3: Modelado de Datos y Optimización del Esquema
Una vez extraídos los datos, ¿cómo debemos almacenarlos? En el contexto de las hipotecas, la flexibilidad es fundamental, pero el rendimiento de las consultas es prioritario.
Enfoque Híbrido: Columnas Estructuradas + JSON
Desaconsejamos aplanar completamente cada campo extraído en una columna dedicada, ya que los formatos documentales cambian. El mejor enfoque es:
- Columnas Core (Estructuradas): ID Expediente, NIF/DNI, Ingresos Mensuales, Fecha Contratación. Estas columnas deben estar tipadas (INT64, STRING, DATE) para permitir joins rápidos con las tablas del CRM y optimizar los costes de almacenamiento (formato BigQuery Capacitor).
- Columna Payload (JSON): Todo el resto de la extracción (detalles menores, notas al margen) permanece en una columna de tipo
JSON. BigQuery soporta nativamente el acceso a los campos JSON con una sintaxis eficiente.
Ejemplo de consulta analítica unificada:
SELECT
crm.customer_id,
crm.risk_score_preliminare,
docs.reddito_mensile,
SAFE_CAST(docs.json_payload.dettagli_extra.bonus_produzione AS FLOAT64) as bonus
FROM
`fintech_lakehouse.crm_customers` crm
JOIN
`fintech_lakehouse.extracted_income_data` docs
ON
crm.tax_code = docs.codice_fiscale
WHERE
docs.reddito_mensile > 2000;Fase 4: Seguridad y Cumplimiento del RGPD (Row-Level Security)
Tratando datos sensibles como ingresos y tasaciones, la seguridad no es opcional. El RGPD impone que el acceso a los datos personales esté limitado al personal estrictamente necesario.
En un data lakehouse google cloud, no es necesario crear vistas separadas para cada grupo de usuarios. Utilizamos la Row-Level Security (RLS) de BigQuery.
Implementación de las Políticas de Acceso
Supongamos que tenemos dos grupos de usuarios: Analistas de Riesgo (acceso completo) y Agentes Comerciales (acceso limitado solo a sus propios expedientes).
CREATE ROW ACCESS POLICY commercial_filter
ON `fintech_lakehouse.extracted_income_data`
GRANT TO ('group:agenti-commerciali@banca.it')
FILTER USING (agente_id = SESSION_USER());Con esta política, cuando un agente ejecuta un SELECT *, BigQuery filtrará automáticamente los resultados, mostrando solo las filas donde el agente_id corresponde al usuario logueado. Los datos sensibles de los otros clientes permanecen invisibles, garantizando el cumplimiento normativo sin duplicar los datos.
Fase 5: Credit Scoring Predictivo con Vertex AI
La última milla de nuestro Lakehouse es la activación del dato. Ahora que hemos unido los datos de comportamiento (historial de pagos del CRM) con los datos de ingresos reales (extraídos de las nóminas), podemos entrenar modelos de Machine Learning superiores.
Utilizando Vertex AI integrado con BigQuery, podemos crear un modelo de regresión logística o una red neuronal para predecir la probabilidad de impago (PD).
- Feature Engineering: Creamos una vista en BigQuery que une las tablas CRM y Documentales.
- Training: Usamos
CREATE MODELdirectamente en SQL (BigQuery ML) o exportamos el dataset a Vertex AI para AutoML. - Prediction: El modelo entrenado puede ser invocado en batch cada noche para recalcular la puntuación de riesgo de todos los expedientes abiertos, señalando anomalías entre los ingresos declarados y los extraídos de los documentos.
Conclusiones

Implementar un data lakehouse google cloud en el sector hipotecario transforma radicalmente la operatividad. No se trata solo de tecnología, sino de velocidad de negocio: pasar de días a minutos para la preaprobación de una hipoteca.
La arquitectura presentada, basada en la estrecha integración entre BigQuery, GCS y Document AI, ofrece tres ventajas competitivas inmediatas:
- Unificación: Una única fuente de verdad para datos estructurados y no estructurados.
- Automatización: Reducción de la intervención humana en la extracción de datos (Data Entry).
- Cumplimiento: Control granular de los accesos nativo en la base de datos.
Para las instituciones financieras que miran hacia 2026 y más allá, esta convergencia entre gestión documental y análisis de datos representa el estándar de facto para seguir siendo competitivos en un mercado cada vez más guiado por los algoritmos.
Preguntas frecuentes

Un Data Lakehouse en Google Cloud es una arquitectura híbrida que combina la flexibilidad de almacenamiento económico de los Data Lakes con el rendimiento de análisis de los Data Warehouses. En el sector financiero, este enfoque permite eliminar los silos entre datos estructurados y documentos no estructurados, como los PDF, permitiendo consultas SQL unificadas. Las ventajas principales incluyen la reducción de la duplicación de datos, la disminución de los costes de almacenamiento y la capacidad de obtener insights en tiempo real para procesos como la aprobación de hipotecas.
El análisis de los PDF en BigQuery se realiza mediante el uso de las Object Tables, que mapean los archivos presentes en Google Cloud Storage como tablas de solo lectura. Para extraer los datos contenidos en los documentos, se integran las Remote Functions que conectan BigQuery a los servicios de Document AI. Esto permite invocar modelos de extracción inteligente directamente mediante consultas SQL, transformando información no estructurada, como los ingresos netos de una nómina, en datos estructurados listos para el análisis.
La seguridad de los datos sensibles y el cumplimiento del RGPD se gestionan a través de la Row-Level Security (RLS) nativa de BigQuery. En lugar de crear copias múltiples de los datos para diferentes equipos, la RLS permite definir políticas de acceso granulares que filtran las filas visibles en base al usuario conectado. Por ejemplo, un analista de riesgos puede ver todos los datos, mientras que un agente comercial visualizará solo los expedientes de sus propios clientes, garantizando la privacidad sin duplicaciones.
Vertex AI potencia el credit scoring utilizando los datos unificados del Lakehouse para entrenar modelos de Machine Learning avanzados. Uniendo el historial de pagos presente en el CRM con los datos de ingresos reales extraídos de los documentos mediante Document AI, es posible crear modelos predictivos más precisos. Estos algoritmos pueden calcular la probabilidad de impago y detectar anomalías entre los ingresos declarados y los efectivos, automatizando y haciendo más segura la evaluación del riesgo.
Los pilares de esta arquitectura incluyen Google Cloud Storage para el almacenamiento físico de los archivos brutos y BigQuery como motor central para el análisis de datos estructurados y metadatos. A estos se añaden Document AI para el procesamiento inteligente de documentos (IDP) y la extracción de entidades, y Vertex AI para la aplicación de modelos predictivos sobre los datos consolidados. Esta combinación transforma un simple archivo en una plataforma analítica activa y automatizada.
Fuentes y Profundización

- Wikipedia: Definición y características de la arquitectura Data Lakehouse
- Wikipedia: Concepto de Datos Oscuros (Dark Data) y su valor potencial
- Banco de España: Marco regulatorio sobre aspectos tecnológicos y computación en la nube
- Comisión Europea: Reglamento de Resiliencia Operativa Digital (DORA) para el sector financiero

¿Te ha resultado útil este artículo? ¿Hay otro tema que te gustaría que tratara?
¡Escríbelo en los comentarios aquí abajo! Me inspiro directamente en vuestras sugerencias.