
Es una experiencia universal en la era moderna: escribimos una pregunta compleja, pulsamos «Enter» y, durante un instante que puede durar desde unos milisegundos hasta varios segundos, el cursor parpadea en el vacío. Ese parpadeo rítmico, aparentemente inocuo, es la única señal visible de una tormenta eléctrica digital de proporciones inimaginables. En ese breve lapso, conocido técnicamente como latencia de inferencia, los Grandes Modelos de Lenguaje (LLM) —la entidad principal que gobierna la inteligencia artificial generativa actual— no están simplemente «buscando» una respuesta en una base de datos, como lo haría un motor de búsqueda tradicional. Están soñando, calculando y construyendo una realidad palabra por palabra.
Para el usuario promedio, este retraso es una pausa; para el ingeniero de machine learning, es un abismo donde convergen la física de los semiconductores, la estadística avanzada y la arquitectura de software más compleja jamás diseñada. Hoy, 28 de febrero de 2026, descorremos el velo de esa caja negra para entender qué ocurre exactamente en las entrañas de silicio mientras esperamos que la máquina nos hable.
La traducción del mundo: De palabras a vectores
El primer paso que ocurre en el instante en que enviamos nuestro prompt es una destrucción total del lenguaje tal como lo conocemos. La IA no entiende de gramática, ironía o poesía en el sentido humano. Para que una red neuronal pueda procesar nuestra solicitud, el texto debe convertirse en matemáticas puras.
Este proceso se denomina tokenización. El sistema fragmenta nuestra frase en unidades más pequeñas llamadas tokens (que pueden ser palabras, partes de palabras o incluso caracteres individuales). Pero la magia real ocurre inmediatamente después, en una fase conocida como embedding o vectorización. Cada token es convertido en una lista de números, un vector que representa su posición en un espacio multidimensional.
Imaginemos un mapa galáctico con miles de dimensiones. En este espacio, la palabra «Rey» está matemáticamente cerca de «Reina» y de «Trono», pero lejos de «Microondas». Cuando el cursor parpadea por primera vez, el modelo está ubicando nuestros conceptos en este vasto mapa semántico, traduciendo la intención humana a coordenadas numéricas que las redes neuronales puedan digerir. Es un proceso de abstracción vertiginoso donde el significado se convierte en geometría.
El pase hacia adelante: Navegando el cerebro de silicio
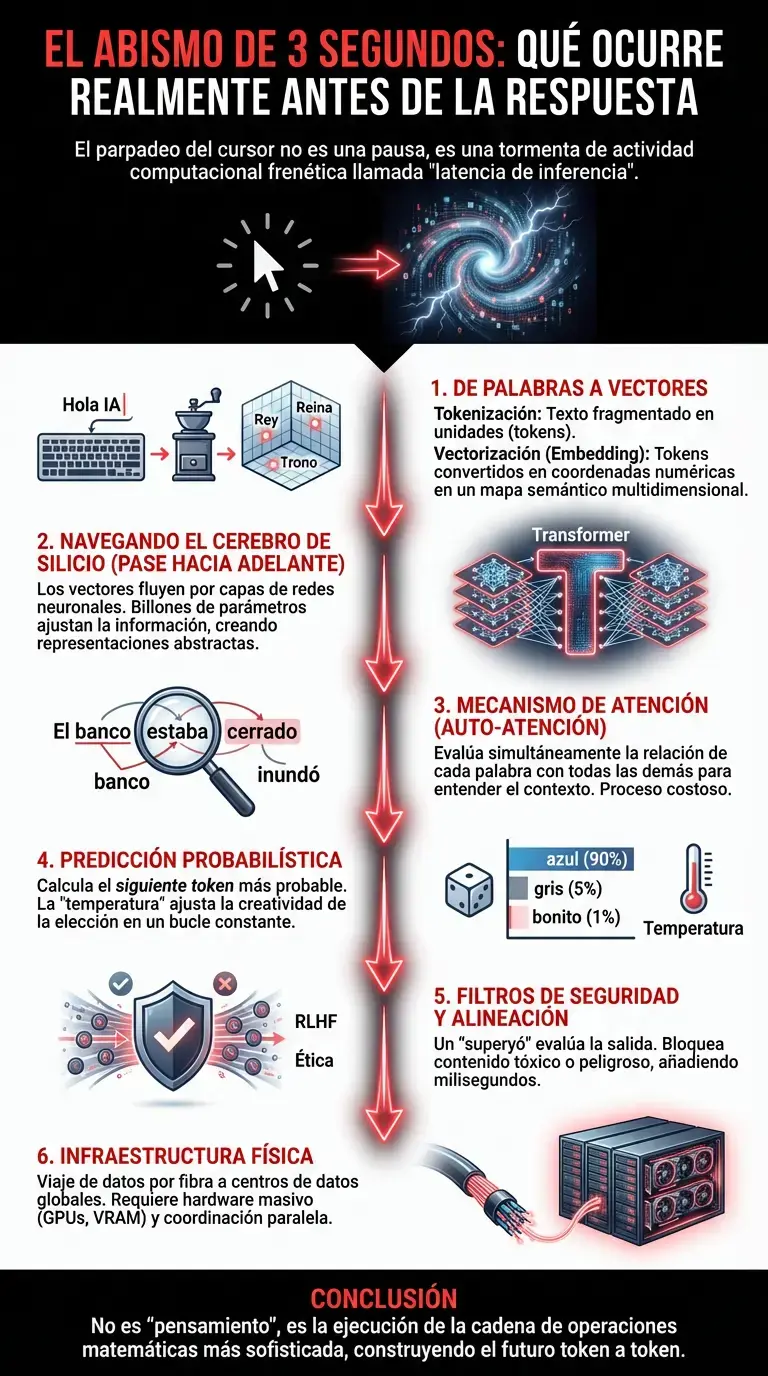
Una vez que la entrada ha sido vectorizada, comienza el verdadero viaje a través de la arquitectura del modelo, comúnmente un Transformer (la «T» en ChatGPT). Aquí es donde el término deep learning cobra todo su sentido. La información no viaja de forma lineal simple; se somete a lo que llamamos un «forward pass» o pase hacia adelante a través de docenas, a veces cientos, de capas de neuronas artificiales.
En este abismo de los tres segundos, los vectores de entrada fluyen a través de estas capas, multiplicándose por matrices gigantescas de parámetros. Un modelo de vanguardia en 2026 puede tener billones de parámetros. Cada parámetro es un pequeño ajuste, un «peso» numérico aprendido durante el entrenamiento, que decide cuánta importancia dar a cada fragmento de información.
Es crucial entender que no hay una «respuesta» pregrabada esperando ser recuperada. La automatización del pensamiento aquí es constructiva. La señal eléctrica (digital) activa ciertas neuronas y desactiva otras, transformando los vectores originales en representaciones cada vez más abstractas y complejas. En las primeras capas, el modelo puede estar identificando sintaxis básica; en las capas medias, contexto semántico; y en las capas profundas, intenciones pragmáticas y razonamiento lógico.
El mecanismo de atención: La concentración selectiva

Dentro de este flujo masivo de datos, ocurre el fenómeno técnico más revolucionario de la última década: el mecanismo de auto-atención (Self-Attention). Mientras el cursor sigue parpadeando, el modelo está releyendo su propia entrada constantemente, evaluando la relación de cada palabra con todas las demás palabras de la frase simultáneamente.
Si escribimos «El banco estaba cerrado porque se inundó», la IA debe decidir si «banco» se refiere a una entidad financiera o a un asiento en el parque. El mecanismo de atención calcula probabilidades basándose en el contexto («cerrado», «inundó»). Asigna un «peso de atención» más alto a las palabras que clarifican el significado.
Este cálculo es computacionalmente costoso. Requiere que el modelo mantenga en su «memoria de trabajo» (la ventana de contexto) todas las relaciones posibles entre los tokens. En los modelos más avanzados de 2026, esta ventana es inmensa, permitiendo a la inteligencia artificial recordar detalles de libros enteros. Sin embargo, procesar esa atención consume una fracción crítica de esos segundos de espera, realizando miles de millones de operaciones de punto flotante por segundo (FLOPS) en los clústeres de GPUs.
La predicción probabilística: Una tirada de dados sofisticada
Llegamos al núcleo del misterio. Tras procesar la entrada a través de todas las capas y aplicar los mecanismos de atención, el modelo llega a la capa final de salida. Aquí es donde muchos se sorprenden: la IA no decide qué frase va a decir. Solo decide cuál es el siguiente token más probable.
El sistema genera una distribución de probabilidad sobre todo su vocabulario (que puede contener cientos de miles de tokens). Por ejemplo, si la frase es «El cielo es…», el modelo asignará un 90% de probabilidad a «azul», un 5% a «gris», un 1% a «bonito», y un 0.0001% a «patata».
Aquí intervienen los algoritmos de decodificación. Dependiendo de la configuración de «temperatura» (un parámetro que controla la creatividad o aleatoriedad), el modelo elige el siguiente token. Si la temperatura es baja, será determinista y elegirá «azul». Si es alta, podría arriesgarse con «gris» o «inmenso». Este proceso de selección ocurre en microsegundos, pero debe repetirse para cada palabra generada. El parpadeo inicial del cursor suele ser el tiempo necesario para calcular el primer token; el resto fluye a medida que el bucle de retroalimentación se activa.
Los filtros de seguridad y la alineación
Existe una capa adicional, a menudo invisible y responsable de una parte significativa de la latencia, que actúa como el «superyó» de la máquina. Antes de que el primer token aparezca en nuestra pantalla, la salida potencial pasa por filtros de seguridad y alineación.
Estos sistemas, entrenados a menudo mediante aprendizaje por refuerzo con retroalimentación humana (RLHF), evalúan si la respuesta generada cumple con las directrices éticas. ¿Es la respuesta tóxica? ¿Es peligrosa? ¿Es una alucinación flagrante? Si el modelo detecta que la ruta probabilística principal conduce a contenido prohibido o dañino, debe recalcular, buscar una ruta alternativa o activar una respuesta de rechazo preprogramada.
Este escrutinio interno es una batalla silenciosa entre la capacidad bruta del modelo para generar cualquier cosa y las restricciones impuestas por sus creadores para garantizar una IA segura y útil. Todo esto sucede mientras nosotros, impacientes, miramos el cursor.
La infraestructura física: El viaje de la luz
Finalmente, no podemos ignorar la realidad física. Cuando interactuamos con una IA generativa, nuestra solicitud viaja a través de fibra óptica hasta un centro de datos que puede estar en otro continente. Allí, la solicitud se pone en cola. A pesar de la potencia de los chips de 2026, la inferencia de modelos masivos requiere una cantidad de memoria VRAM y ancho de banda de memoria colosal.
El «abismo» también es un problema de logística de hardware. Cargar los parámetros del modelo en la memoria activa de los chips, coordinar el procesamiento paralelo entre múltiples tarjetas gráficas y ensamblar la respuesta para enviarla de vuelta a través de la red añade milisegundos preciosos al contador. La automatización de esta infraestructura es una maravilla de la ingeniería moderna, gestionando millones de peticiones simultáneas sin colapsar.
En Breve (TL;DR)
El parpadeo del cursor oculta una compleja latencia de inferencia donde la IA construye respuestas mediante cálculos matemáticos avanzados.
El lenguaje humano es transformado en vectores geométricos y matemáticas puras para que las redes neuronales interpreten la intención.
Mediante el mecanismo de auto-atención, el modelo evalúa relaciones entre palabras para construir respuestas lógicas en tiempo real.
Conclusión

El abismo de los tres segundos no es un tiempo muerto; es un periodo de actividad frenética y complejidad asombrosa. Mientras el cursor parpadea, una arquitectura monumental de redes neuronales deconstruye nuestro lenguaje, navega por espacios multidimensionales, sopesa billones de conexiones, calcula probabilidades estadísticas y filtra éticamente los resultados, todo ello ejecutado sobre una infraestructura de hardware que consume la energía de una pequeña ciudad.
La próxima vez que se encuentre ante ese parpadeo rítmico, recuerde que no está esperando a que la máquina «piense» en el sentido humano. Está presenciando, en tiempo real, la ejecución de la cadena de operaciones matemáticas más sofisticada que la humanidad ha logrado orquestar. El silencio digital no es vacío; es el sonido del cómputo puro construyendo el futuro, token a token.
Preguntas frecuentes

Ese breve lapso, conocido técnicamente como latencia de inferencia, es un periodo de actividad computacional frenética. No se trata de una búsqueda en una base de datos, sino de la construcción de una respuesta desde cero. Durante esos segundos, el modelo convierte el lenguaje humano en matemáticas, procesa la información a través de billones de parámetros en redes neuronales y calcula estadísticamente cada palabra que va a generar.
La inteligencia artificial no comprende la gramática o la ironía como los humanos, sino que transforma el texto en números mediante un proceso llamado tokenización. Posteriormente, utiliza la vectorización para convertir esos fragmentos en coordenadas dentro de un mapa multidimensional. De esta forma, el significado se traduce en geometría, permitiendo al modelo identificar relaciones semánticas entre conceptos basándose en su cercanía matemática.
Es el componente técnico que permite al modelo evaluar la relación de cada palabra con todas las demás de la frase simultáneamente. Gracias a la auto-atención, el sistema puede discernir el contexto y desambiguar significados, decidiendo por ejemplo si el término banco se refiere a una institución financiera o a un asiento. Este cálculo consume gran parte de los recursos durante el parpadeo del cursor.
El modelo funciona mediante predicción probabilística, generando una distribución estadística sobre todo su vocabulario para determinar cuál es el siguiente token más probable. Dependiendo de la configuración de temperatura, que controla la creatividad, el sistema elige la siguiente pieza del texto en un bucle constante. No planifica la frase entera, sino que la construye paso a paso basándose en cálculos matemáticos.
Antes de que el texto aparezca en pantalla, la salida potencial atraviesa una capa de alineación y seguridad que actúa como un control ético. Estos filtros, entrenados a menudo con retroalimentación humana, verifican que la respuesta no sea tóxica, peligrosa o falsa. Si el modelo detecta una ruta problemática, debe recalcular y buscar una alternativa segura, lo cual añade milisegundos adicionales al tiempo de respuesta.
¿Todavía tienes dudas sobre El abismo de 3 segundos: qué ocurre realmente antes de la respuesta?
Escribe aquí tu pregunta específica para encontrar al instante la respuesta oficial de Google.
Fuentes y Profundización



¿Te ha resultado útil este artículo? ¿Hay otro tema que te gustaría que tratara?
¡Escríbelo en los comentarios aquí abajo! Me inspiro directamente en vuestras sugerencias.