In Breve (TL;DR)
La valutazione del rischio evolve in un processo ingegneristico che supera i modelli lineari per ottimizzare il portafoglio crediti.
L’architettura multivariata analizza stabilità settoriale e reddito residuo reale, andando oltre il semplice calcolo del rapporto rata su reddito.
Algoritmi predittivi e logiche fuzzy permettono di valutare accuratamente la solvibilità anche nei profili complessi scartati dai sistemi tradizionali.
Il diavolo è nei dettagli. 👇 Continua a leggere per scoprire i passaggi critici e i consigli pratici per non sbagliare.
Nel panorama fintech attuale, la valutazione del rischio di credito ha superato da tempo i modelli lineari basati su fogli di calcolo statici. Per chi si occupa di progettare sistemi di erogazione o preventivatori evoluti, il credit scoring mutui non è più una semplice checklist, ma un problema ingegneristico complesso che richiede l’integrazione di modelli multivariati, analisi comportamentale e capacità predittiva. L’obiettivo di questa analisi tecnica è dissezionare l’architettura di un moderno motore di valutazione, spostando il focus dal “cosa” viene valutato al “come” l’algoritmo deve processare le informazioni per ridurre i falsi negativi e ottimizzare il portafoglio crediti.
La sfida principale per gli istituti di credito e le piattaforme di mediazione non è solo evitare il default, ma identificare la solvibilità in profili non standard che i sistemi legacy scarterebbero a priori. Secondo le direttive EBA (European Banking Authority) sulla concessione e monitoraggio dei prestiti, l’approccio deve essere prospettico e granulare. In questo contesto, l’ingegnerizzazione dell’algoritmo diventa il vero vantaggio competitivo, trasformando i dati grezzi in una probabilità di default (PD) accurata e dinamica.

Oltre il Rapporto Rata/Reddito: Architettura Multivariata
Il pilastro tradizionale del credit scoring mutui è sempre stato il rapporto rata/reddito (DTI – Debt to Income), solitamente fissato con una soglia rigida (es. 33%). Tuttavia, un approccio ingegneristico moderno deve trattare il DTI non come un cancello binario (passa/non passa), ma come una variabile ponderata all’interno di un sistema complesso. La costruzione di un modello robusto richiede l’integrazione di tre macro-dimensioni analitiche.
1. Analisi della Stabilità Lavorativa e Settoriale
Non basta più distinguere tra tempo indeterminato e determinato. Un algoritmo avanzato deve ingerire dati relativi al codice ATECO del datore di lavoro e incrociarli con i trend macroeconomici del settore. Ad esempio, un contratto a tempo indeterminato in un settore in forte contrazione (es. editoria cartacea tradizionale) potrebbe avere uno score di stabilità inferiore rispetto a una partita IVA con tre anni di storico in un settore in espansione (es. cybersecurity). L’algoritmo deve calcolare un indice di volatilità del reddito, penalizzando non la tipologia contrattuale in sé, ma la varianza storica dei flussi di cassa.
2. Il Calcolo del Reddito Residuo (Subsistence Level)
Un errore comune nei preventivatori online è ignorare il valore assoluto del reddito residuo. Una rata di 3.000€ su un reddito di 10.000€ (30%) è sostenibile; una rata di 450€ su un reddito di 1.500€ (30%) lo è molto meno, specialmente in aree metropolitane ad alto costo della vita. L’ingegnerizzazione del modello deve includere una variabile di sussistenza geografica, che sottrae al reddito netto le spese stimate per nucleo familiare basate sui dati ISTAT locali, prima di calcolare la capacità di rimborso. Questo riduce drasticamente il rischio di insolvenza tecnica post-erogazione.
3. Scoring dell’Asset Immobiliare
Il valore dell’immobile non è statico. Un sistema evoluto integra API immobiliari per valutare non solo il Loan-to-Value (LTV) attuale, ma la liquidabilità futura dell’asset. L’algoritmo deve penalizzare l’LTV in zone con tempi medi di vendita superiori ai 12 mesi o con trend demografici negativi, proteggendo la banca in caso di escussione della garanzia.
Logiche Fuzzy e Alberi Decisionali per i Casi Limite
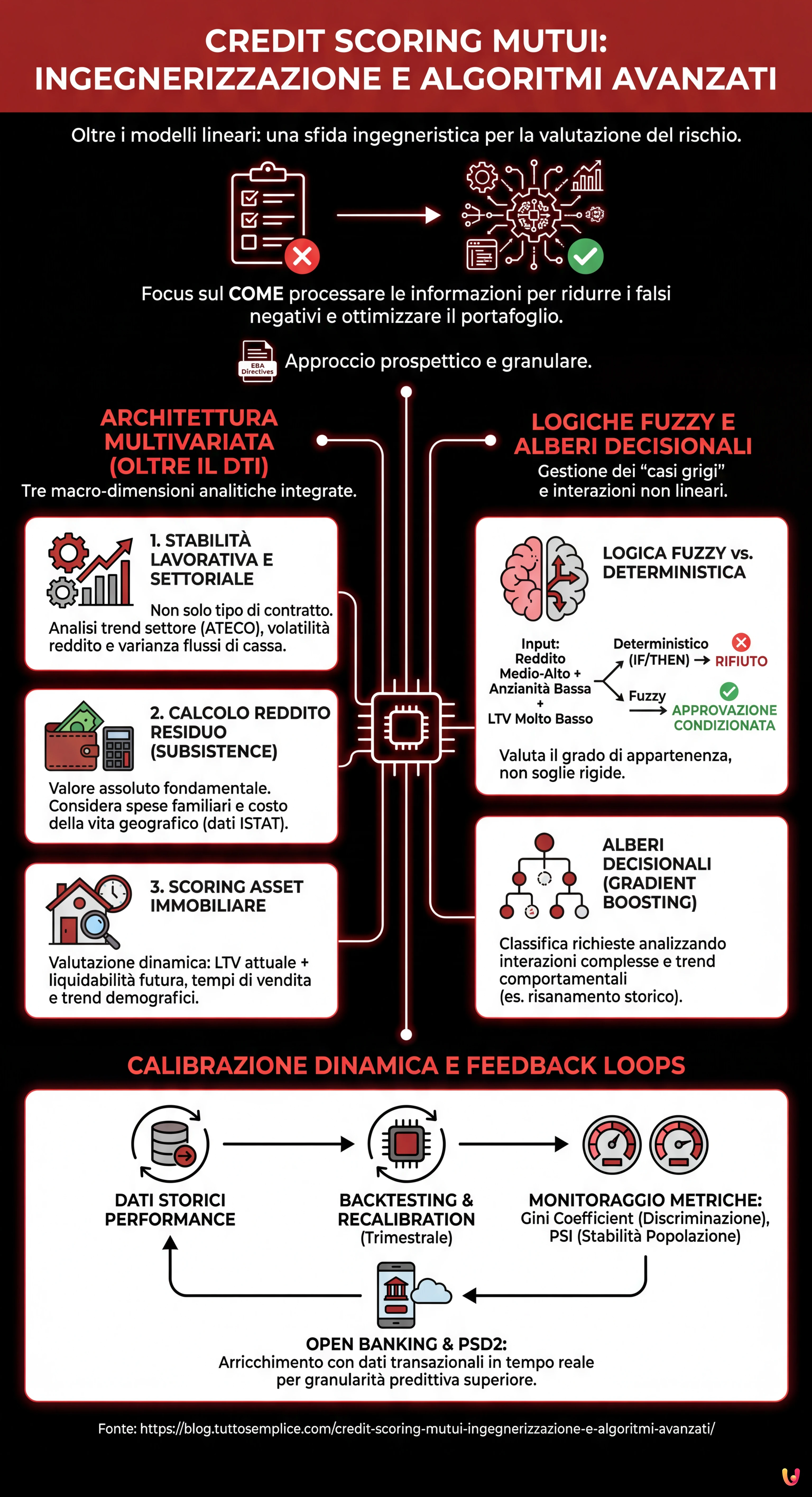
La vera potenza di un sistema di credit scoring mutui ingegnerizzato risiede nella gestione dei “casi grigi”. I sistemi deterministici (IF/THEN) falliscono quando un richiedente ha un ottimo reddito ma una storia creditizia breve, oppure un LTV basso ma un rapporto rata/reddito al limite. Qui entra in gioco la logica Fuzzy e gli alberi decisionali (Decision Trees).
Invece di utilizzare soglie rigide (Crisp Logic), un sistema Fuzzy valuta il grado di appartenenza a un insieme. Ad esempio:
- Input: Reddito “Medio-Alto” AND Anzianità Lavorativa “Bassa” AND LTV “Molto Basso”.
- Output: Invece di un rifiuto automatico per l’anzianità, il sistema genera un output di “Approvazione Condizionata” o richiede un garante specifico.
L’utilizzo di algoritmi di Gradient Boosting o Random Forest permette di classificare la richiesta mutuo analizzando le interazioni non lineari tra le variabili. Se un utente ha avuto un piccolo ritardo nei pagamenti 4 anni fa (dato negativo) ma da allora ha incrementato il risparmio del 20% annuo (dato positivo), un albero decisionale ben calibrato può riconoscere il trend di risanamento (comportamento virtuoso) che un sistema lineare ignorerebbe, focalizzandosi solo sulla segnalazione in centrale rischi.
Calibrazione Dinamica e Feedback Loops


Nessun algoritmo di scoring nasce perfetto. L’aspetto ingegneristico più critico è la progettazione del ciclo di feedback (Feedback Loop). Il sistema deve essere collegato ai dati storici di performance dei mutui erogati. Se l’algoritmo ha previsto una bassa probabilità di default per un cluster di clienti che, invece, ha mostrato un alto tasso di ritardi nei pagamenti dopo il 24° mese, il modello deve auto-correggersi.
Questo processo, noto come Backtesting e Recalibration, deve avvenire su base trimestrale. È fondamentale monitorare due metriche:
- Gini Coefficient: Per misurare la capacità discriminante del modello (quanto bene separa i buoni pagatori dai cattivi).
- Population Stability Index (PSI): Per verificare se la popolazione attuale di richiedenti è cambiata significativamente rispetto a quella su cui il modello è stato addestrato (es. improvviso aumento di richieste da lavoratori in smart working remoto).
Inoltre, con l’avvento della PSD2 e dell’Open Banking, l’algoritmo può essere arricchito con dati transazionali in tempo reale. Analizzare le abitudini di spesa (es. gioco d’azzardo online vs investimenti ricorrenti) offre un livello di granularità predittiva superiore a qualsiasi busta paga, permettendo di affinare il punteggio di affidabilità prima ancora di arrivare al rogito.
Conclusioni

L’ingegnerizzazione del credit scoring mutui rappresenta la frontiera tra la burocrazia bancaria tradizionale e la gestione finanziaria moderna basata sui dati. Costruire algoritmi che integrano variabili macroeconomiche, logiche fuzzy per la gestione delle incertezze e sistemi di auto-apprendimento non è solo un esercizio tecnico, ma una necessità strategica. Questo approccio permette di servire nicchie di mercato solvibili ma trascurate, riducendo al contempo l’esposizione al rischio sistemico. Per gli sviluppatori e i risk manager, la sfida futura non sarà più raccogliere i dati, ma disegnare l’architettura logica in grado di interpretarli con la stessa sfumatura di giudizio di un analista umano esperto, ma con la velocità e la scalabilità di una macchina.
Domande frequenti

A differenza dei sistemi tradizionali basati su fogli di calcolo statici, i moderni algoritmi utilizzano modelli multivariati che integrano analisi comportamentale e capacità predittiva. Questi sistemi non si limitano a verificare il reddito, ma incrociano dati come la stabilità del settore lavorativo, il reddito residuo reale e la liquidabilità futura dell immobile. L obiettivo è calcolare una probabilità di default dinamica e accurata, riducendo i falsi negativi.
Il rapporto rata reddito è una metrica percentuale classica, spesso fissata al 33 per cento, che funge da soglia rigida. Il reddito residuo, invece, è un valore assoluto che indica quanto denaro rimane al richiedente dopo aver pagato la rata e le spese di sussistenza stimate per la sua area geografica. I modelli evoluti privilegiano il reddito residuo per evitare l insolvenza tecnica, specialmente nelle città con alto costo della vita.
Grazie alla direttiva PSD2 e all Open Banking, gli algoritmi possono accedere ai dati transazionali in tempo reale, analizzando le abitudini di spesa effettive del richiedente. Questo permette di distinguere comportamenti rischiosi, come il gioco d azzardo, da comportamenti virtuosi come gli investimenti ricorrenti, offrendo una granularità predittiva superiore alla semplice analisi della busta paga.
Sono tecniche avanzate utilizzate per gestire i cosiddetti casi grigi che i sistemi binari scarterebbero. La logica Fuzzy valuta il grado di appartenenza a un insieme piuttosto che usare soglie rigide, mentre gli alberi decisionali come il Random Forest analizzano le interazioni non lineari tra variabili. Questo consente di approvare profili complessi, ad esempio chi ha poca anzianità lavorativa ma un ottimo trend di risparmio.
I nuovi motori di valutazione non guardano solo alla tipologia di contratto, ma analizzano il codice ATECO del datore di lavoro incrociandolo con i trend macroeconomici. Un lavoratore in un settore in espansione potrebbe avere uno score di stabilità superiore rispetto a chi lavora in un ambito in forte crisi, poiché l algoritmo calcola la volatilità storica dei flussi di cassa e il rischio prospettico di perdita del reddito.
Fonti e Approfondimenti

- EBA – Linee guida sulla concessione e monitoraggio dei prestiti
- Banca d’Italia – Validazione dei sistemi interni di misurazione del rischio di credito
- ISTAT – Statistiche sulle condizioni economiche e spese delle famiglie
- Wikipedia – Credit score
- BIS – Quadro normativo di Basilea sul rischio di credito

Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.