
Siamo nel 2026, e mentre l’intelligenza artificiale generativa ha riscritto le regole dell’interazione uomo-macchina, le leggi fondamentali della fisica e della logica rimangono immutate. Per chi, come me, ha iniziato la propria carriera con un saldatore in mano e lo schema di un circuito integrato (IC) sul tavolo, l’attuale panorama del Cloud Computing non appare come un mondo alieno, ma come un’evoluzione su scala macroscopica di problemi che abbiamo già risolto su scala microscopica. Al centro di tutto c’è l’architettura sistemi distribuiti: un concetto che oggi applichiamo a cluster globali, ma che nasce dalle interconnessioni tra transistor su un wafer di silicio.
In questo saggio tecnico, esploreremo come la mentalità sistemica necessaria per progettare hardware affidabile sia la chiave di volta per costruire software resiliente. Analizzeremo come i vincoli fisici del silicio trovino i loro perfetti analoghi nelle sfide immateriali del SaaS moderno.
1. Il Problema del Fan-out: Dai Logic Gates al Load Balancing
Nell’ingegneria elettronica, il Fan-out definisce il numero massimo di ingressi logici che un’uscita può pilotare in modo affidabile. Se un gate logico tenta di inviare un segnale a troppi altri gate, la corrente si divide eccessivamente, il segnale si degrada e la commutazione (0 a 1 o viceversa) diventa lenta o indefinita. È un limite fisico di capacità di pilotaggio.
L’Analogo nel Software: Il Collo di Bottiglia del Database
Nell’architettura sistemi distribuiti, il concetto di Fan-out si manifesta brutalmente quando un singolo servizio (es. un database master o un servizio di autenticazione) viene bombardato da troppe richieste concorrenti dai microservizi client. Proprio come un transistor non può fornire corrente infinita, un database non ha connessioni TCP o cicli CPU infiniti.
La soluzione hardware è l’inserimento di buffer per rigenerare il segnale e aumentare la capacità di pilotaggio. Nel SaaS, applichiamo lo stesso principio attraverso:
- Connection Pooling: Che agisce come un buffer di corrente, mantenendo le connessioni attive e riutilizzabili.
- Read Replicas: Che parallelizzano il carico di lettura, simile all’aggiunta di stadi di amplificazione in parallelo.
- Message Brokers (Kafka/RabbitMQ): Che disaccoppiano il produttore dal consumatore, gestendo i picchi di carico (backpressure) esattamente come un condensatore di disaccoppiamento stabilizza la tensione durante i picchi di assorbimento.
2. Propagazione del Segnale: Clock Skew e Teorema CAP
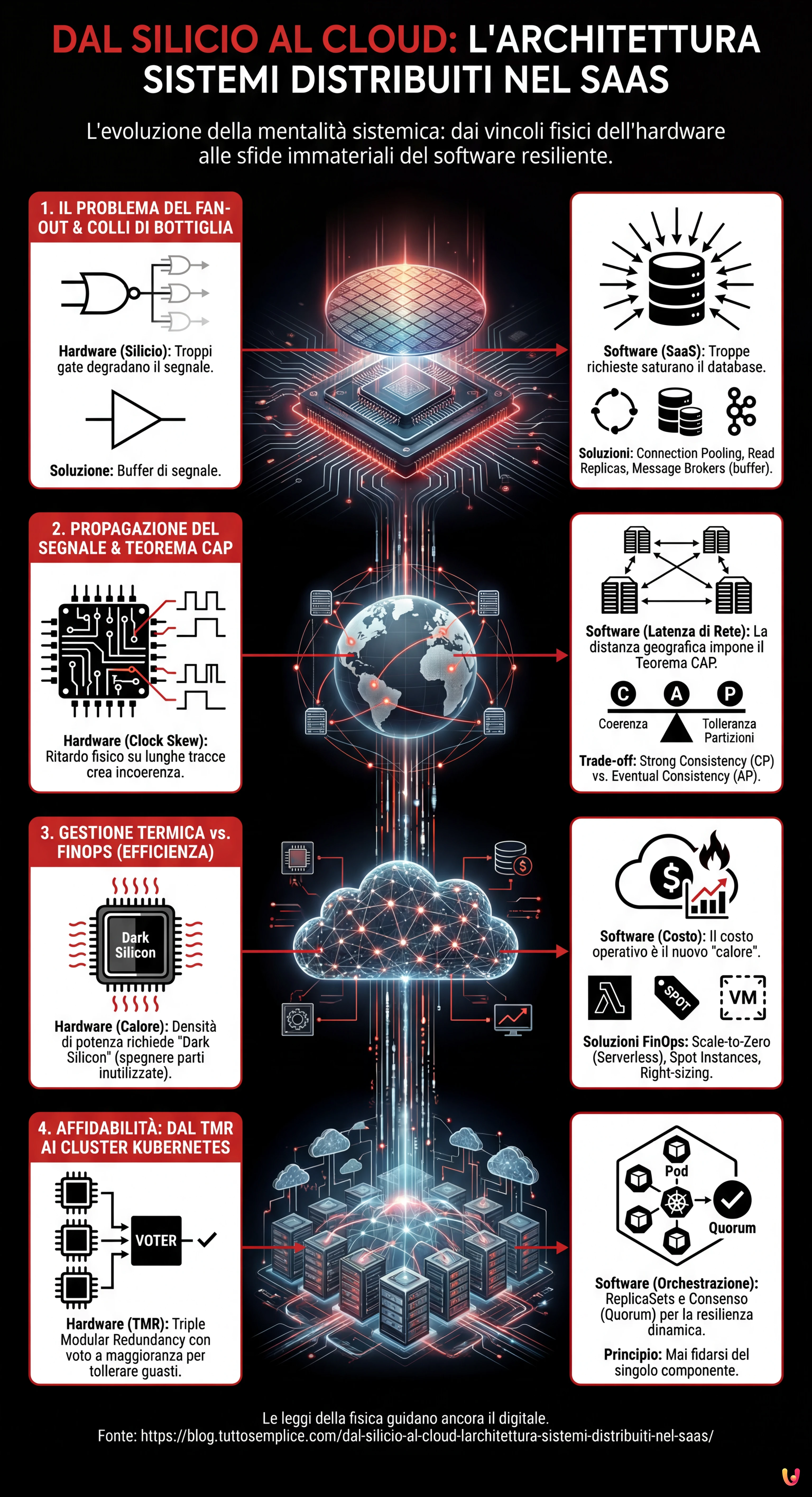
Sui circuiti ad alta frequenza, la velocità della luce (o meglio, la velocità di propagazione del segnale nel rame/oro) è un vincolo tangibile. Se una traccia sul PCB è più lunga di un’altra, il segnale arriva in ritardo, causando problemi di sincronizzazione noti come Clock Skew. Il sistema diventa incoerente perché diverse parti del chip vedono la “realtà” in momenti diversi.
La Tirannia della Distanza nel Cloud
Nel cloud, la latenza di rete è il nuovo ritardo di propagazione. Quando progettiamo un’architettura sistemi distribuiti geo-ridondata, non possiamo ignorare che la luce impiega tempo per viaggiare da Francoforte alla Virginia del Nord. Questo ritardo fisico è la radice del Teorema CAP (Consistency, Availability, Partition tolerance).
Un ingegnere elettronico sa che non può avere un segnale perfettamente sincrono su un chip enorme senza rallentare il clock (sacrificando le performance per la coerenza). Allo stesso modo, un architetto software deve scegliere tra:
- Strong Consistency (CP): Aspettare che tutti i nodi siano allineati (come un clock globale lento), accettando latenza elevata.
- Eventual Consistency (AP): Permettere ai nodi di divergere temporaneamente per mantenere alta la disponibilità e bassa la latenza, gestendo i conflitti a posteriori (simile a circuiti asincroni o self-timed).
3. Gestione Termica vs. FinOps: L’Efficienza come Vincolo

La densità di potenza è il nemico numero uno nei moderni processori. Se non si dissipa il calore, il chip va in thermal throttling (rallenta) o si brucia. La progettazione VLSI (Very Large Scale Integration) moderna ruota attorno al concetto di “Dark Silicon”: non possiamo accendere tutti i transistor contemporaneamente perché il chip fonderebbe. Dobbiamo accendere solo ciò che serve, quando serve.
Il Costo è il Calore del Cloud
Nel modello SaaS, il “calore” è il costo operativo. Un’architettura inefficiente non fonde i server (ci pensa il provider cloud), ma brucia il budget aziendale. Il FinOps è la moderna gestione termica.
Come un ingegnere hardware usa il Clock Gating per spegnere le parti del chip non utilizzate, un Cloud Architect deve implementare:
- Scale-to-Zero: Utilizzando tecnologie Serverless (come AWS Lambda o Google Cloud Run) per spegnere completamente le risorse quando non c’è traffico.
- Spot Instances: Sfruttare capacità in eccesso a basso costo, accettando il rischio di interruzione, simile all’uso di componenti con tolleranze più ampie in circuiti non critici.
- Right-sizing: Adattare le risorse al carico reale, evitando l’over-provisioning che nel mondo hardware equivarrebbe a usare un dissipatore da 1kg per un chip da 5W.
4. Affidabilità: Dal TMR ai Cluster Kubernetes
Nei sistemi avionici o spaziali, dove la riparazione è impossibile e le radiazioni possono invertire casualmente un bit (Single Event Upset), si utilizza la Triple Modular Redundancy (TMR). Tre circuiti identici eseguono lo stesso calcolo e un circuito di voto (voter) decide l’output basandosi sulla maggioranza. Se uno fallisce, il sistema continua a funzionare.
L’Orchestrazione della Resilienza
Questo è l’essenza esatta di un cluster Kubernetes o di un database distribuito con consenso Raft/Paxos. In un’architettura sistemi distribuiti moderna:
- ReplicaSets: Mantengono multiple copie (Pod) dello stesso servizio. Se un nodo cade (hardware failure), il Control Plane (il “voter”) se ne accorge e riprogramma il pod altrove.
- Quorum nei Database: Per confermare una scrittura in un cluster (es. Cassandra o etcd), richiediamo che la maggioranza dei nodi (N/2 + 1) confermi l’operazione. Questo è matematicamente identico alla logica di voto del TMR hardware.
La differenza sostanziale è che nell’hardware la ridondanza è statica (cablata), mentre nel software è dinamica e riconfigurabile. Tuttavia, il principio di base rimane: mai fidarsi del singolo componente.
Conclusioni: L’Approccio Sistemico Unificato
Passare dal silicio al cloud non significa cambiare mestiere, ma cambiare scala. La progettazione di un’architettura sistemi distribuiti efficace richiede la stessa disciplina necessaria per il tape-out di un microprocessore:
- Comprendere i vincoli fisici (banda, latenza, costo/calore).
- Progettare per il fallimento (il componente si romperà, il pacchetto andrà perso).
- Disaccoppiare i sistemi per evitare la propagazione degli errori.
Nel 2026, gli strumenti sono diventati incredibilmente astratti. Scriviamo YAML che descrivono infrastrutture effimere. Ma sotto quei livelli di astrazione, ci sono ancora elettroni che corrono, clock che ticchettano e buffer che si riempiono. Mantenere la consapevolezza di questa realtà fisica è ciò che distingue un buon sviluppatore da un vero Architetto di Sistemi.
Domande frequenti

L’architettura cloud è considerata un’evoluzione su scala macroscopica delle sfide microscopiche tipiche dei circuiti integrati. Problemi fisici come la gestione del calore e la propagazione del segnale nel silicio trovano una diretta corrispondenza nella gestione dei costi e nella latenza di rete del software, richiedendo una mentalità sistemica simile per garantire resilienza ed efficienza operativa.
Il Fan-out nel software si manifesta quando un singolo servizio, come un database master, riceve un numero eccessivo di richieste concorrenti, analogamente a un gate logico che pilota troppi ingressi. Per mitigare questo collo di bottiglia, si adottano soluzioni come il connection pooling, le repliche di lettura e i message broker, che fungono da buffer per stabilizzare il carico e prevenire il degrado delle prestazioni.
La latenza di rete, paragonabile al ritardo di propagazione del segnale nei circuiti elettronici, impedisce la sincronizzazione istantanea tra nodi geograficamente distanti. Questo vincolo fisico obbliga gli architetti software a scegliere tra Strong Consistency, accettando latenze maggiori per attendere l’allineamento dei nodi, o Eventual Consistency, che privilegia la disponibilità tollerando disallineamenti temporanei dei dati.
Nel modello SaaS, il costo operativo rappresenta l’equivalente del calore generato nei processori: entrambi sono fattori limitanti che devono essere controllati. Le strategie FinOps come lo Scale-to-Zero e il Right-sizing rispecchiano tecniche hardware come il Clock Gating, spegnendo o ridimensionando le risorse inutilizzate per ottimizzare l’efficienza e impedire che il budget venga consumato inutilmente.
I cluster Kubernetes applicano in modo dinamico i principi della Triple Modular Redundancy utilizzata nei sistemi critici hardware. Attraverso l’uso di ReplicaSets e algoritmi di consenso per i database distribuiti, il sistema monitora costantemente lo stato dei servizi e sostituisce i nodi falliti basandosi su meccanismi di voto e maggioranza, assicurando la continuità operativa senza singoli punti di fallimento.
Hai ancora dubbi su Dal Silicio al Cloud: L’Architettura Sistemi Distribuiti nel SaaS?
Digita qui la tua domanda specifica per trovare subito la risposta ufficiale di Google.
Fonti e Approfondimenti

- La definizione ufficiale di Cloud Computing del NIST (National Institute of Standards and Technology)
- Approfondimento sul Teorema CAP (Consistency, Availability, Partition tolerance)
- Definizione tecnica di Fan-out nell’elettronica digitale
- Il concetto di Dark Silicon e i vincoli di potenza nei processori moderni


")
Hai trovato utile questo articolo? C’è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.