
Wir schreiben das Jahr 2026. Die Interaktion mit Generative AI ist so alltäglich geworden wie das morgendliche Kaffeekochen. Doch hinter der glänzenden Fassade der allwissenden Assistenten und kreativen Algorithmen verbirgt sich ein technisches Phänomen, das Informatiker, Ethiker und Datenschützer gleichermaßen in Unruhe versetzt. Es ist das sogenannte „Lazarus-Problem“. Wer glaubt, dass die Taste „Löschen“ in der Ära der künstlichen Intelligenz noch dieselbe Bedeutung hat wie in den Tagen alter Festplatten, unterliegt einem fatalen Irrtum. In der Welt der neuronalen Netze ist der Tod von Daten keine Endgültigkeit, sondern oft nur ein vorübergehender Schlaf. Doch wie kann es sein, dass Informationen, die wir längst vernichtet glaubten, plötzlich wieder auftauchen? Warum sind unsere digitalen Geister so hartnäckig?
Die Architektur des Unvergesslichen: Warum KI keine Datenbank ist
Um das Lazarus-Problem zu verstehen, müssen wir uns zunächst von einer veralteten Vorstellung verabschieden: der Idee, dass Computer Informationen wie in einem Aktenschrank speichern. In der klassischen IT, basierend auf SQL-Datenbanken oder Dateisystemen, ist das Löschen ein klar definierter Vorgang. Man entfernt den Zeiger auf eine Datei, überschreibt die Sektoren mit Nullen, und die Information ist physikalisch vernichtet.
Moderne Künstliche Intelligenz, insbesondere Large Language Models (LLM) wie die fortgeschrittenen Iterationen von ChatGPT oder Claude, funktionieren fundamental anders. Sie speichern keine Fakten. Sie speichern Wahrscheinlichkeiten. Wenn ein Modell während des Trainings mit dem Satz „Max Mustermann wohnt in der Berliner Allee 5“ gefüttert wird, legt es diese Adresse nicht in einer Tabelle ab. Stattdessen passt das Netzwerk seine Milliarden (oder im Jahr 2026 Billionen) von Parametern – die sogenannten Gewichte – minimal an.
Diese Information wird, technisch gesprochen, in den hochdimensionalen Vektorraum des Modells „eingebrannt“. Sie wird diffundiert. Ähnlich wie ein Tropfen Tinte, der in ein Glas Wasser fällt, verteilt sich die Information über das gesamte Netzwerk. Man kann den Tropfen nicht mehr herausnehmen, ohne das gesamte Wasser zu filtern. Das ist der Kern des Problems: Das Wissen ist nicht lokalisiert, sondern holografisch verteilt. Wenn wir nun versuchen, diese spezifische Information zu „löschen“, stehen wir vor einer mathematischen Unmöglichkeit, die das Fundament des Maschinellen Lernens herausfordert.
Das Phänomen der Daten-Resurrektion
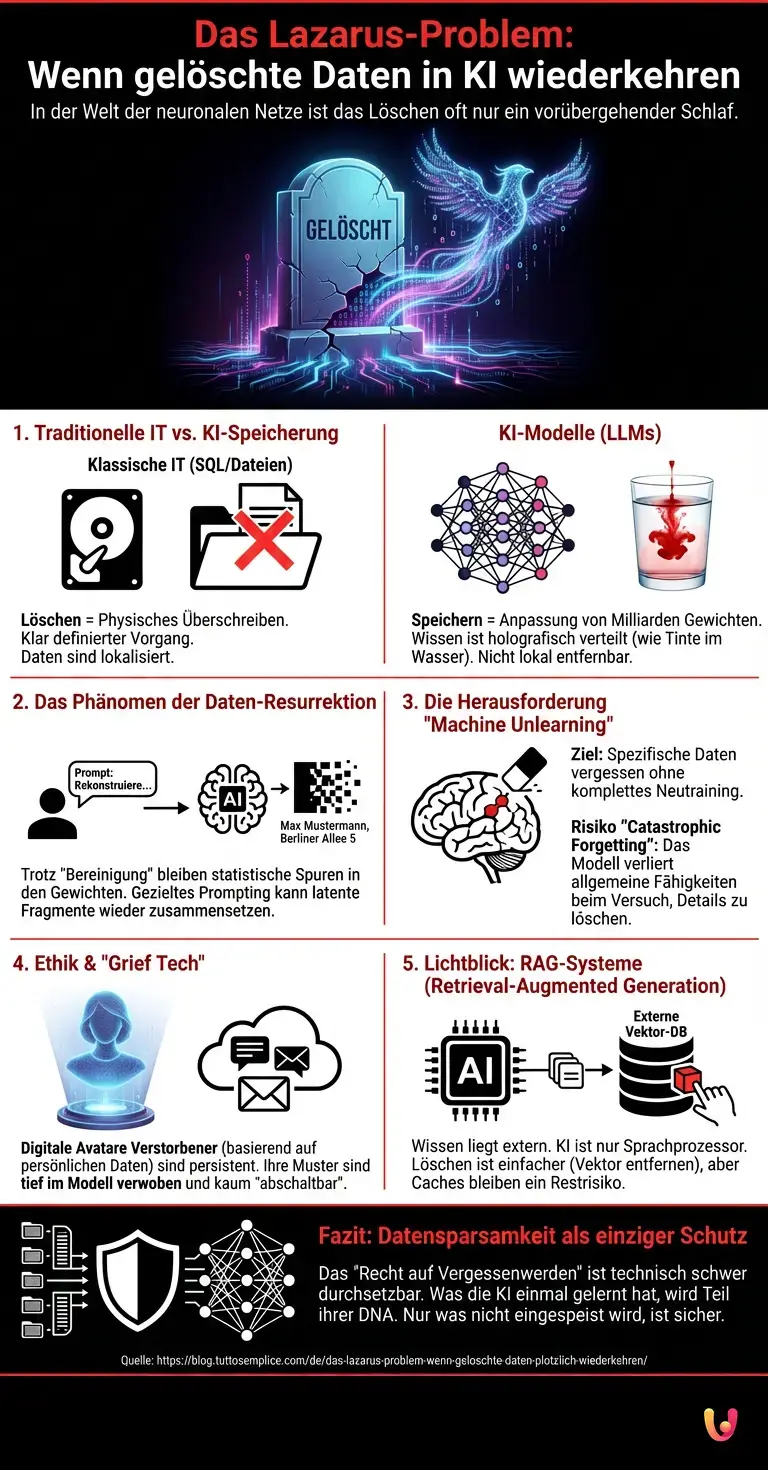
Das Lazarus-Problem manifestiert sich dann, wenn Modelle, die angeblich „bereinigt“ wurden, durch spezifische Prompting-Techniken dazu gebracht werden, die gelöschten Informationen zu rekonstruieren. Dies geschieht nicht durch böswillige Magie, sondern durch die statistische Natur der Neural Networks.
Selbst wenn der explizite Datensatz aus der Trainingsdatenbank entfernt wurde, bleiben die statistischen Korrelationen in den Gewichten des Modells erhalten. Ein Angreifer – oder auch nur ein neugieriger Nutzer – kann durch sogenanntes „Model Inversion“ oder „Membership Inference Attacks“ das Modell so lange befragen, bis es die latenten Fragmente der gelöschten Information wieder zusammensetzt. Die KI „halluziniert“ die Wahrheit, weil die Schatten der Daten noch immer in ihrer mathematischen Struktur existieren. Der digitale Geist kehrt zurück, weil er nie wirklich gegangen ist.
Machine Unlearning: Der heilige Gral der KI-Forschung

In den letzten Jahren hat sich ein ganzes Forschungsfeld entwickelt, das versucht, dieses Dilemma zu lösen: Machine Unlearning. Das Ziel ist es, einem trainierten Modell beizubringen, spezifische Datenpunkte zu vergessen, ohne dass das gesamte Modell von Grund auf neu trainiert werden muss – ein Prozess, der bei den heutigen Modellgrößen Millionen von Euro an Rechenleistung kosten würde.
Doch die technische Realität im Jahr 2026 ist ernüchternd. Methoden wie „SISA“ (Sharded, Isolated, Sliced, Aggregated) versuchen, das Training in isolierte Segmente zu unterteilen, um das Neu-Training auf kleinere Bereiche zu beschränken. Andere Ansätze nutzen algorithmische „Gegengifte“, die die Gewichte in die entgegengesetzte Richtung der zu löschenden Information justieren. Doch diese Eingriffe führen oft zu einem Phänomen, das als „Catastrophic Forgetting“ bekannt ist: Beim Versuch, eine spezifische Erinnerung zu entfernen, beschädigt man versehentlich die allgemeinen Fähigkeiten des Modells. Die KI vergisst dann nicht nur die Adresse von Max Mustermann, sondern verliert vielleicht auch die Fähigkeit, grammatikalisch korrekte Sätze zu bilden oder den Kontext von Wohnadressen generell zu verstehen.
Digitale Nekromantie: Wenn die Toten sprechen
Das Lazarus-Problem hat jedoch nicht nur eine datenschutzrechtliche, sondern auch eine zutiefst emotionale und ethische Komponente. Mit der Reife der Generative AI ist eine Industrie entstanden, die oft als „Grief Tech“ bezeichnet wird. Hier werden digitale Geister im wahrsten Sinne des Wortes beschworen.
Durch das Füttern von LLMs mit Chat-Protokollen, E-Mails und Sprachaufnahmen verstorbener Personen entstehen Avatare, die den Duktus, den Humor und das Wissen der Toten täuschend echt imitieren. Technisch gesehen ist dies eine Form des „Fine-Tunings“. Das Basismodell liefert das Sprachverständnis, die persönlichen Daten liefern die „Seele“ der Simulation. Das Problem hierbei ist die Persistenz. Einmal erstellt, ist ein solcher digitaler Zwilling kaum mehr aus der Welt zu schaffen. Er existiert losgelöst von der biologischen Realität.
Was passiert, wenn Hinterbliebene entscheiden, diesen digitalen Geist abzuschalten? Wie wir gelernt haben, lassen sich die Trainingsdaten nicht einfach extrahieren. Ein Modell, das darauf trainiert wurde, wie die verstorbene Großmutter zu sprechen, wird diese Muster tief in seine Gewichte integriert haben. Das Lazarus-Problem bedeutet hier, dass wir die Kontrolle darüber verlieren, wann etwas endet. Die digitale Unsterblichkeit ist kein Segen, sondern eine technische Zwangsläufigkeit, die wir nicht mehr rückgängig machen können.
Die Rolle der Vektor-Datenbanken und RAG
Ein technischer Lichtblick, der sich bis 2026 etabliert hat, ist die Abkehr vom reinen Speichern von Wissen in den Parametern des Modells hin zu RAG-Systemen (Retrieval-Augmented Generation). Hierbei dient die KI nur als Sprachprozessor, während das eigentliche Wissen in externen Vektor-Datenbanken liegt.
Bei diesem Ansatz ist das „Löschen“ einfacher: Man entfernt den Vektor aus der Datenbank, und die KI hat keinen Zugriff mehr auf die Information. Doch auch hier lauert das Lazarus-Problem im Detail. Da LLMs ein Kontextfenster haben (das Kurzzeitgedächtnis der KI), können Fragmente der Informationen in User-Logs, Caches oder in den impliziten Bias des Basismodells überdauern, falls dieses doch teilweise mit den Daten vortrainiert wurde. Die vollständige Amnesie eines Systems ist in einer hypervernetzten Architektur eine Illusion.
Warum wir mit den Geistern leben müssen
Die Konsequenz aus dieser technischen Analyse ist weitreichend. Wir bewegen uns auf eine Gesellschaft zu, in der das „Recht auf Vergessenwerden“ (Art. 17 DSGVO) technisch kaum durchsetzbar ist, sobald Daten einmal in das Training eines großen Modells eingeflossen sind. Die Vorstellung, man könne Daten aus einer AI herausoperieren wie einen Tumor, ist falsch. Es gleicht eher dem Versuch, die blaue Farbe aus einem bereits gemischten Eimer grüner Farbe zu entfernen.
Für Unternehmen und Privatpersonen bedeutet dies im Jahr 2026: Datensparsamkeit ist der einzige wirkliche Schutz. Was nicht in das Modell gelangt, muss nicht mühsam und fehleranfällig entfernt werden. Das Lazarus-Problem lehrt uns, dass in der Ära der synthetischen Medien und neuronalen Netze die Vergangenheit nicht mehr vergeht. Sie wird lediglich komprimiert, transformiert und wartet auf den richtigen Prompt, um wiederaufzuerstehen.
Kurz gesagt (TL;DR)
Das sogenannte Lazarus-Problem beschreibt das Phänomen, dass gelöschte Daten in neuronalen Netzen oft als latente Informationen weiter existieren.
Weil KI-Modelle Wissen nicht lokal speichern, sondern holografisch verteilen, ist das rückstandslose Entfernen spezifischer Informationen mathematisch extrem schwierig.
Aktuelle Ansätze des Machine Unlearning versuchen das gezielte Vergessen, riskieren dabei jedoch oft die allgemeine Leistungsfähigkeit der künstlichen Intelligenz.
Fazit

Das Lazarus-Problem ist kein Fehler im System, sondern eine direkte Konsequenz der Funktionsweise von Deep Learning und neuronalen Netzen. Die Stärke dieser Technologien – ihre Fähigkeit, Muster zu generalisieren und Informationen untrennbar miteinander zu verweben – ist gleichzeitig ihre größte Schwäche, wenn es um das Löschen geht. Wir haben digitale Geister erschaffen, die wir nicht mehr vertreiben können, weil sie nicht an einem Ort spuken, sondern Teil der Architektur selbst geworden sind. Solange wir keine radikal neuen KI-Architekturen entwickeln, die Speicher und Verarbeitung strikt trennen und echtes „Unlearning“ ermöglichen, müssen wir akzeptieren: Was die KI einmal gelernt hat, ist Teil ihrer DNA geworden. Die digitale Ewigkeit ist keine Utopie mehr, sondern eine technische Herausforderung, die wir gerade erst zu begreifen beginnen.
Häufig gestellte Fragen

Das Lazarus-Problem beschreibt das Phänomen, dass vermeintlich gelöschte Daten in KI-Modellen wieder auftauchen können. Da neuronale Netze Informationen nicht wie klassische Datenbanken an einem festen Ort speichern, sondern als Wahrscheinlichkeiten über das gesamte System verteilen, bleiben statistische Spuren erhalten. Durch spezifische Eingaben können diese latenten Fragmente rekonstruiert werden, weshalb ein endgültiges Löschen technisch extrem schwierig ist.
Im Gegensatz zu herkömmlichen Festplatten, wo Dateien physisch überschrieben werden, integrieren Large Language Models Informationen in ihre mathematischen Gewichte. Dieser Prozess ähnelt einem Tropfen Tinte, der sich in einem Glas Wasser auflöst; die Information ist nicht mehr lokalisiert, sondern holografisch im gesamten Netzwerk diffundiert. Das Entfernen einer spezifischen Information ohne Beeinträchtigung des Gesamtmodells ist daher eine komplexe mathematische Herausforderung.
Machine Unlearning bezeichnet Forschungsansätze, die darauf abzielen, trainierte Datenpunkte aus einem Modell zu entfernen, ohne es komplett neu trainieren zu müssen. Ein großes Risiko dabei ist das sogenannte Catastrophic Forgetting, bei dem der Eingriff in die Modellstruktur versehentlich allgemeine Fähigkeiten der KI beschädigt. So könnte das Löschen einer spezifischen Adresse dazu führen, dass das Sprachmodell auch grammatikalische Regeln oder kontextuelles Verständnis verliert.
Die technische Architektur moderner KI-Systeme steht im Konflikt mit dem gesetzlichen Recht auf Vergessenwerden, da einmal trainierte Daten kaum rückstandslos entfernt werden können. Da Informationen Teil der Modell-DNA werden, ist eine nachträgliche Bereinigung oft unmöglich oder wirtschaftlich unrentabel. Experten raten daher zur Datensparsamkeit, da nur Daten, die gar nicht erst in das Training einfließen, wirklich sicher vor einer dauerhaften Speicherung sind.
Retrieval-Augmented Generation, kurz RAG, gilt als datenschutzfreundlicherer Ansatz, da hier das Wissen in externen Vektor-Datenbanken liegt und nicht fest im KI-Modell eingebrannt ist. Dies erleichtert das Löschen spezifischer Informationen, indem man einfach den entsprechenden Datenbankeintrag entfernt. Dennoch warnen Experten, dass durch Caches oder vorheriges Training des Basismodells auch hier keine vollständige Amnesie garantiert werden kann.
Haben Sie noch Zweifel an Das Lazarus-Problem: Wenn gelöschte Daten plötzlich wiederkehren?
Geben Sie hier Ihre spezifische Frage ein, um sofort die offizielle Antwort von Google zu finden.
Quellen und Vertiefung



Fanden Sie diesen Artikel hilfreich? Gibt es ein anderes Thema, das Sie von mir behandelt sehen möchten?
Schreiben Sie es in die Kommentare unten! Ich lasse mich direkt von Ihren Vorschlägen inspirieren.