
Der Cursor blinkt. Ein stetiges, rhythmisches Pochen auf dem strahlend weißen Bildschirm. Sie sitzen vor Ihrem Computer, die Finger ruhen auf der Tastatur, und Sie formulieren im Kopf die perfekte Eingabeaufforderung. In diesem scheinbar stillen Moment, kurz bevor Sie die Eingabetaste drücken, wirkt das System vollkommen ruhig. Doch diese Stille ist eine meisterhafte Illusion. Wenn wir Plattformen wie ChatGPT oder andere moderne Sprachmodelle nutzen, stellen wir uns oft vor, dass die Maschine auf der anderen Seite “wartet” oder “schläft”, ähnlich wie ein Mensch, der auf eine Frage wartet. Die Realität der modernen Künstlichen Intelligenz ist jedoch weitaus komplexer. Das sogenannte Standby-Mysterium verbirgt eine hochgradig synchronisierte Symphonie aus Hardware-Allokation, Speichermanagement und Netzwerkprotokollen. Was passiert also wirklich im Hintergrund, in jener flüchtigen Sekunde, bevor der Befehl zur Ausführung erteilt wird? Um diese Neugier zu stillen, müssen wir tief in die Architektur von Generative AI eintauchen.
Die Illusion des schlafenden Gehirns: VRAM und statische Bereitschaft
Um zu verstehen, was im Standby-Modus passiert, müssen wir uns zunächst von der anthropomorphen Vorstellung verabschieden, dass eine KI ein ruhendes Gehirn besitzt. Ein LLM (Large Language Model) ist im Kern eine gigantische mathematische Funktion, bestehend aus Milliarden von Parametern – Gewichten und Verzerrungen (Weights and Biases), die in Matrizen organisiert sind. Wenn das System “wartet”, schläft es nicht; es befindet sich in einem Zustand extremer statischer Spannung.
Diese Parameter sind nicht auf einer langsamen Festplatte gespeichert, während Sie tippen. Sie sind vollständig in den VRAM (Video Random Access Memory) von massiven GPU-Clustern (Graphics Processing Units) geladen. Ein Modell mit 70 Milliarden Parametern benötigt beispielsweise etwa 140 Gigabyte an extrem schnellem Speicher, nur um existent und abrufbereit zu sein. In der Sekunde, bevor Sie ‘Enter’ drücken, verbrauchen diese Serverfarmen bereits beträchtliche Mengen an Energie, um den Speicher aufzufrischen und die Datenströme aufrechtzuerhalten. Die Neural Networks sind wie ein gespannter Bogen: Die Energie ist bereits investiert, die Struktur ist in Position, es fehlt lediglich der Auslöser.
Der unsichtbare Handschlag: WebSockets und Load Balancing
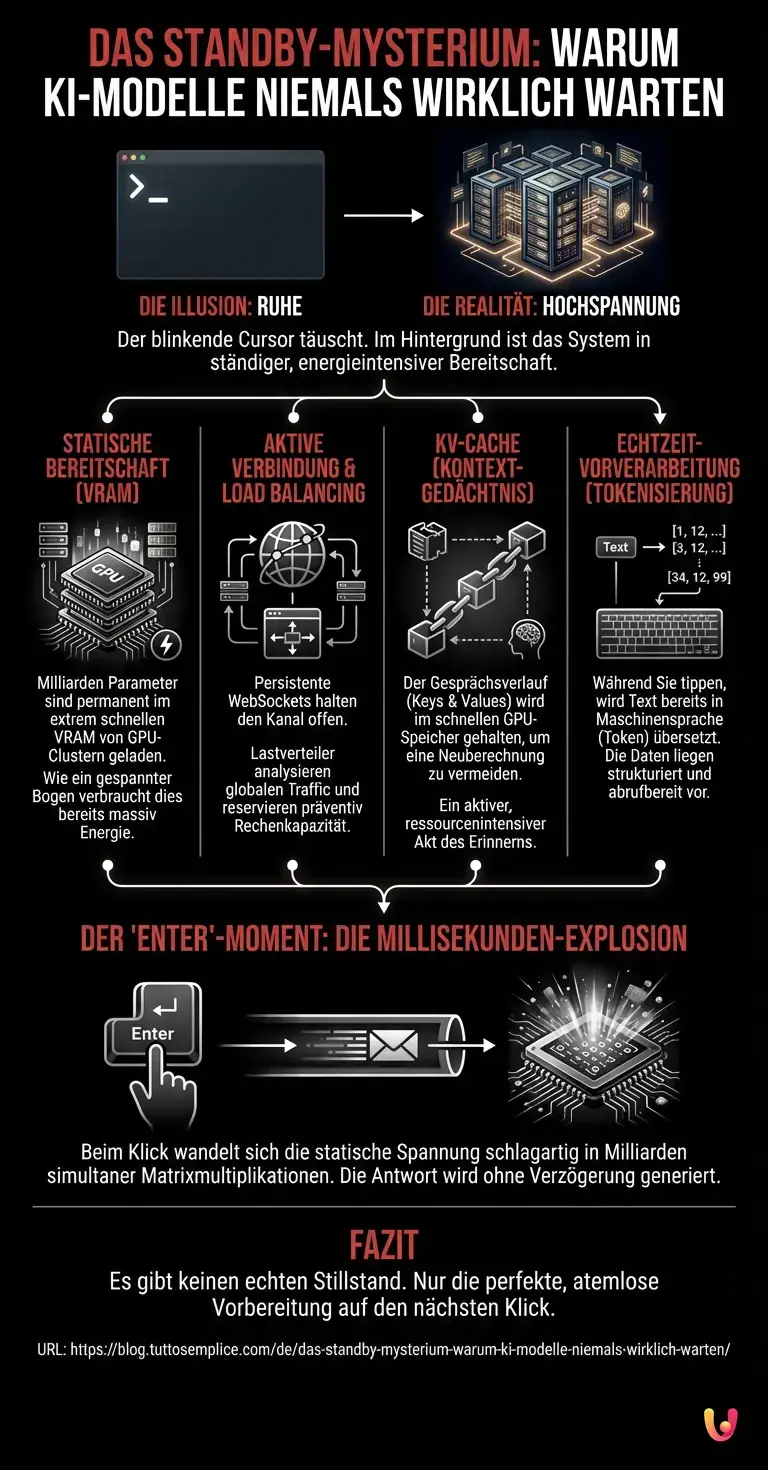
Während Sie noch tippen, ist Ihr Browser keineswegs isoliert. Die Verbindung zwischen Ihrem Endgerät und den Servern des Anbieters ist hochaktiv. Moderne KI-Interfaces nutzen persistente Verbindungen wie WebSockets oder Server-Sent Events (SSE). Das bedeutet, dass kein neuer Kommunikationskanal aufgebaut werden muss, wenn Sie den Befehl absenden. Der Kanal steht bereits weit offen.
Im Hintergrund analysieren Load Balancer (Lastverteiler) kontinuierlich den globalen Traffic. In der Sekunde vor Ihrem Klick weiß das System bereits, über welchen Knotenpunkt Ihre Anfrage geleitet wird. Es misst Latenzen, prüft die Auslastung der GPU-Racks in Rechenzentren von Virginia bis Frankfurt und reserviert präventiv Rechenkapazitäten. Dieser Prozess, oft als Predictive Scaling bezeichnet, nutzt selbst wieder Maschinelles Lernen, um vorherzusagen, wie viele Nutzer in den nächsten Millisekunden auf ‘Enter’ drücken werden. Die Infrastruktur atmet im Rhythmus der globalen Tastenschläge.
Das Geheimnis des KV-Cache: Warum die Maschine sich erinnert

Der faszinierendste technische Aspekt des Standby-Mysteriums offenbart sich, wenn Sie sich bereits in einer laufenden Konversation befinden. Warum weiß das Modell sofort, was Sie drei Fragen zuvor gesagt haben, ohne die gesamte Historie bei jedem Klick komplett neu berechnen zu müssen? Die Antwort liegt im sogenannten Key-Value Cache (KV-Cache).
Die Transformer-Architektur, die das Rückgrat von AI-Modellen bildet, nutzt einen Aufmerksamkeitsmechanismus (Attention Mechanism). Um zu verhindern, dass das System bei jeder neuen Eingabe exponentiell mehr Rechenleistung benötigt, speichert es die mathematischen Repräsentationen (Keys und Values) aller bisherigen Token der aktuellen Konversation direkt im Hochgeschwindigkeitsspeicher der GPU. Während Sie also überlegen und der Cursor blinkt, hält die Grafikkarte aktiv den Kontext Ihrer Unterhaltung im Speicher. Dieser KV-Cache ist flüchtig und extrem wertvoll. Das System muss in Echtzeit entscheiden, ob es diesen Speicherplatz für Sie reserviert hält oder ihn einem anderen Nutzer zuweist, falls Sie zu lange zögern. Das “Warten” der Maschine ist also ein aktiver, ressourcenintensiver Akt des Erinnerns.
Tokenisierung am Rande des Netzwerks
Ein weiterer Prozess, der oft unbemerkt bleibt, ist die Vorbereitung Ihrer Eingabe. Sprachmodelle verstehen keine Buchstaben oder Wörter; sie verstehen nur Zahlen, sogenannte Token. Während Sie tippen, beginnen einige moderne Architekturen bereits auf der Client-Seite (in Ihrem Browser) oder an den Edge-Servern (den Ihnen am nächsten gelegenen Servern) mit der Tokenisierung.
Mittels Algorithmen wie Byte Pair Encoding (BPE) wird Ihr Text in semantische Fragmente zerlegt und in numerische IDs übersetzt. Wenn Sie das Wort “Künstliche” tippen, wird es vielleicht in die Token “Künst” und “liche” gespalten. Diese Vorverarbeitung stellt sicher, dass in der exakten Millisekunde Ihres Klicks keine Zeit mit linguistischer Formatierung verschwendet wird. Der Text ist bereits in die Maschinensprache übersetzt und liegt als strukturierter Tensor bereit, um in das neuronale Netz eingespeist zu werden.
Die Anatomie der Millisekunde: Der Funke entzündet sich
Was passiert nun exakt in dem Moment, in dem der mechanische Schalter Ihrer Tastatur den Kontakt schließt und das ‘Enter’-Signal an das Betriebssystem sendet? Der Übergang vom Standby zur Inferenz (der eigentlichen Berechnung) ist eine Meisterleistung der Informatik.
Das vorbereitete Token-Array schießt durch den bereits offenen WebSocket-Kanal. Der Load Balancer, der Ihre Sitzung bereits einem spezifischen GPU-Cluster zugewiesen hat, leitet das Datenpaket ohne Verzögerung weiter. Der Tensor trifft auf die erste Schicht des neuronalen Netzes. In diesem Bruchteil einer Sekunde wandelt sich der statische Zustand des VRAMs in eine gewaltige dynamische Rechenoperation. Milliarden von Matrixmultiplikationen werden simultan ausgeführt. Die GPUs ziehen schlagartig mehr Strom, die Lüfter der Server-Racks drehen hoch. Das System berechnet Wahrscheinlichkeiten, greift auf den bereitgehaltenen KV-Cache zu und generiert das erste Token der Antwort.
All dies geschieht in einem Zeitfenster, das kürzer ist als ein menschlicher Wimpernschlag. Die scheinbare Ruhe vor dem Sturm war in Wirklichkeit eine hochgradig optimierte Startrampe, die nur auf das finale Signal wartete.
Kurz gesagt (TL;DR)
KI-Modelle ruhen niemals wirklich, da Milliarden von Parametern permanent im schnellen VRAM-Speicher abrufbereit gehalten werden und dabei stetig Energie verbrauchen.
Bereits während der Texteingabe analysieren intelligente Load Balancer den globalen Datenverkehr, um vorausschauend die optimalen Rechenkapazitäten für die bevorstehende Anfrage zu reservieren.
Gleichzeitig speichert der ressourcenintensive Key-Value-Cache den Kontext laufender Unterhaltungen aktiv im Hochgeschwindigkeitsspeicher, wodurch das vermeintliche Warten zu einem extrem anspruchsvollen Erinnerungsprozess wird.
Fazit

Das Standby-Mysterium entpuppt sich bei genauerer Betrachtung als eine der beeindruckendsten Ingenieursleistungen unserer Zeit. Wenn der Cursor blinkt und Sie vor der Eingabe zögern, ruht die Maschine nicht. Sie hält Milliarden von Parametern im Hochgeschwindigkeitsspeicher, hält Netzwerkprotokolle offen, jongliert mit dem KV-Cache Ihrer bisherigen Konversation und bereitet Ihre getippten Worte in Echtzeit für die mathematische Verarbeitung vor. Die Stille auf Ihrem Bildschirm ist lediglich die Benutzeroberfläche einer gigantischen, globalen Infrastruktur, die unter maximaler Spannung steht. In der Welt der modernen Sprachmodelle gibt es keinen echten Stillstand – es gibt nur die perfekte, atemlose Vorbereitung auf den nächsten Klick.
Häufig gestellte Fragen

Ein Sprachmodell schläft niemals wirklich, sondern befindet sich in einem Zustand extremer statischer Spannung. Milliarden von Parametern werden kontinuierlich im extrem schnellen VRAM von riesigen GPU Clustern bereitgehalten, was bereits beträchtliche Energie erfordert. Die gesamte Infrastruktur wartet mit offenen Netzwerkverbindungen nur auf den Auslöser, um ohne Verzögerung mit der eigentlichen Berechnung beginnen zu können.
Um sofort antworten zu können, müssen die gigantischen mathematischen Modelle vollständig in den Arbeitsspeicher der Grafikkarten geladen sein. Dieser Vorgang erfordert eine ständige Auffrischung des Speichers und die kontinuierliche Aufrechterhaltung der globalen Datenströme. Die Serverfarmen investieren also bereits massiv Energie in die Bereitstellung der Infrastruktur, lange bevor ein Nutzer den finalen Befehl zur Ausführung erteilt.
Moderne Sprachmodelle nutzen den sogenannten Key Value Cache, um den Kontext einer laufenden Konversation im Hochgeschwindigkeitsspeicher der Grafikkarte zu sichern. Dadurch muss das System nicht bei jeder neuen Eingabe die gesamte Historie neu berechnen. Dieses aktive Erinnern ist sehr ressourcenintensiv und der Speicherplatz wird dynamisch zugewiesen, solange der Nutzer aktiv bleibt.
Noch während der Nutzer tippt, beginnen Algorithmen im Hintergrund damit, den Text in semantische Fragmente zu zerlegen und in numerische Werte zu übersetzen. Diese sogenannte Tokenisierung findet oft schon direkt im Browser oder auf nahegelegenen Servern statt. Sobald die Eingabetaste gedrückt wird, liegt der Text bereits als strukturierter Datensatz vor und kann sofort verarbeitet werden.
Load Balancer analysieren kontinuierlich den weltweiten Datenverkehr und weisen Nutzeranfragen präventiv den passenden Rechenzentren zu. Sie messen Latenzen und prüfen die Auslastung der Server, um durch maschinelles Lernen vorherzusagen, wann und wo Rechenkapazitäten benötigt werden. So stellen sie sicher, dass die Datenpakete über bereits offene Kanäle blitzschnell an die richtige Grafikkarte weitergeleitet werden.
Haben Sie noch Zweifel an Das Standby-Mysterium: Warum KI-Modelle niemals wirklich warten?
Geben Sie hier Ihre spezifische Frage ein, um sofort die offizielle Antwort von Google zu finden.
Quellen und Vertiefung

- Grundlagen und Funktionsweise von Large Language Models (LLMs)
- Die Transformer-Architektur und der Aufmerksamkeitsmechanismus (Attention)
- Hardware-Infrastruktur: KI-Beschleuniger und GPU-Nutzung in Rechenzentren
- Technische Details zum WebSocket-Protokoll für persistente Verbindungen
- Forschung und Standards zu Künstlicher Intelligenz (National Institute of Standards and Technology, USA)



Fanden Sie diesen Artikel hilfreich? Gibt es ein anderes Thema, das Sie von mir behandelt sehen möchten?
Schreiben Sie es in die Kommentare unten! Ich lasse mich direkt von Ihren Vorschlägen inspirieren.