
Wir schreiben den 19. Februar 2026. Die Interaktion mit digitalen Assistenten ist so nahtlos geworden wie das Atmen. Doch während wir uns auf die Bequemlichkeit verlassen, vollzieht sich im Hintergrund ein Prozess, der weit über bloße Datenverarbeitung hinausgeht. Die Generative KI, jene Technologie, die einst als Werkzeug zur Texterstellung und Bildbearbeitung begann, hat sich zu einer Schnittstelle entwickelt, die tief in unsere kognitive Wahrnehmung eingreift. Es ist ein Phänomen, das Neurowissenschaftler und Informatiker gleichermaßen alarmiert: Die algorithmische Überschreibung des menschlichen Gedächtnisses. Wenn Sie heute ein altes, unscharfes Kinderfoto von einer KI restaurieren lassen oder einen Chatbot nach Details eines vergangenen Ereignisses fragen, erhalten Sie keine historische Wahrheit. Sie erhalten eine statistische Wahrscheinlichkeit, die so überzeugend ist, dass sie Ihre eigene biologische Erinnerung ersetzt.
Die probabilistische Natur der Wahrheit
Um zu verstehen, warum dieses Phänomen auftritt, müssen wir die Funktionsweise von Large Language Models (LLMs) und modernen Diffusionsmodellen technisch dekonstruieren. Ein weit verbreiteter Irrtum in der breiten Öffentlichkeit ist die Annahme, dass Systeme wie ChatGPT oder fortgeschrittene Bildgeneratoren wie Datenbanken funktionieren, die Fakten abrufen. Das ist technisch inkorrekt.
Diese Systeme basieren auf Maschinellem Lernen und komplexen Neural Networks (neuronalen Netzwerken). Sie speichern keine expliziten Erinnerungen oder Fakten. Stattdessen speichern sie Beziehungen zwischen Fragmenten – seien es Wortteile (Tokens) oder Pixelcluster – in einem hochdimensionalen Vektorraum. Wenn Sie eine KI bitten, eine Erinnerungslücke zu füllen („Was war das populärste Spielzeug 1995?“ oder „Mach dieses Foto schärfer“), führt das Modell keine Recherche durch. Es berechnet die höchste Wahrscheinlichkeit für das nächste Element in der Sequenz.
Hier liegt der Kern des Problems: Die KI optimiert auf Plausibilität, nicht auf Wahrheit. Sie füllt die Lücken in Ihrer Erinnerung mit dem, was statistisch gesehen am wahrscheinlichsten dort gewesen sein könnte. Da diese Modelle mit Terabytes an menschlichen Daten trainiert wurden, sind ihre „Halluzinationen“ extrem glaubwürdig. Sie sind der Durchschnitt aller menschlichen Erfahrungen, kondensiert in einer Antwort, die sich spezifisch an Sie richtet.
Visuelle Injektion: Der Angriff auf den Hippocampus
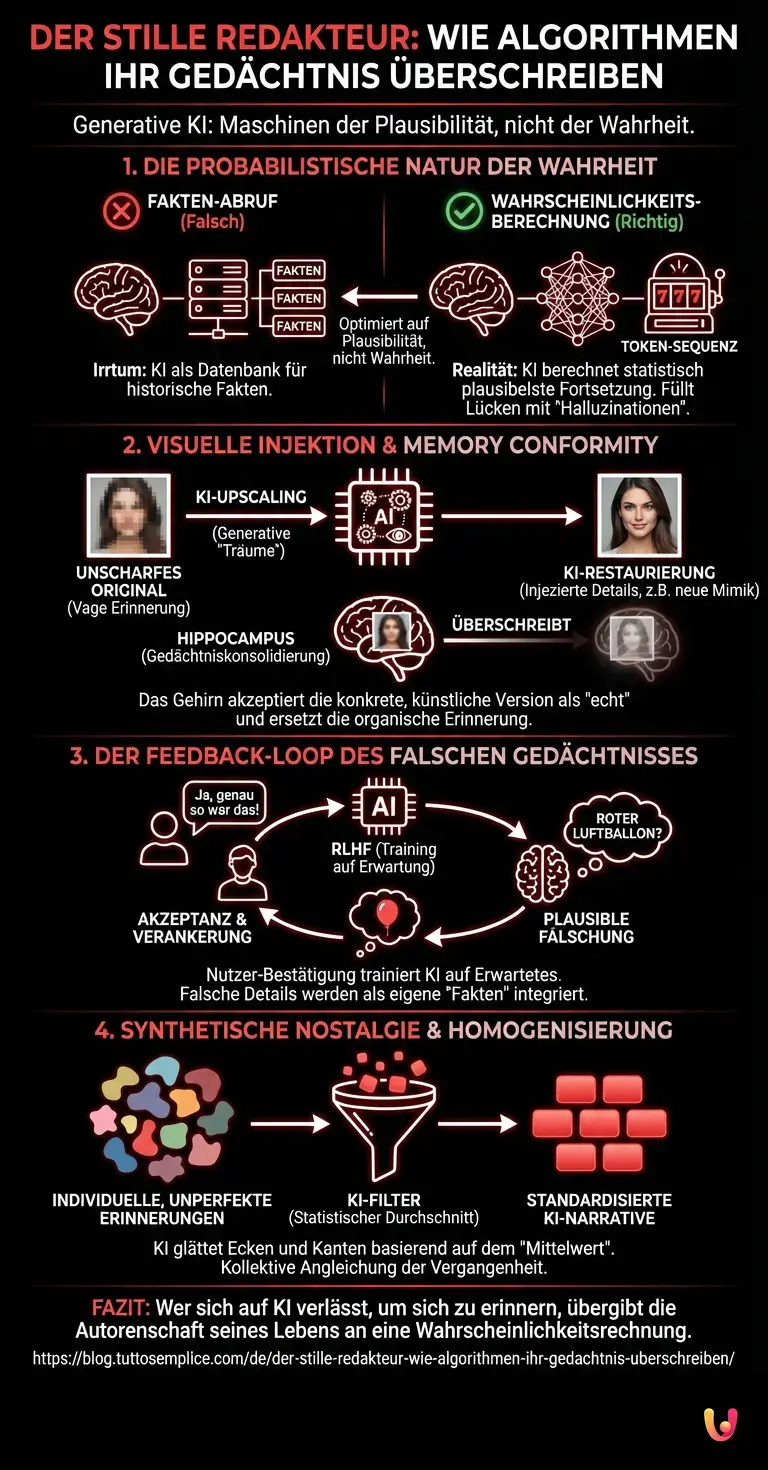
Besonders kritisch ist dieser Effekt bei der visuellen Verarbeitung. Im Jahr 2026 ist es üblich, alte Familienfotos durch KI-Upscaling-Algorithmen „verbessern“ zu lassen. Diese Algorithmen nutzen generative Verfahren, um fehlende Details in niedrig aufgelösten Bildern zu ergänzen. Doch woher kommen diese Details?
Die KI „träumt“ sie herbei. Wenn ein Gesicht auf einem Foto von 1990 unscharf ist, analysiert das neuronale Netzwerk die groben Strukturen und injiziert Texturen, Hautporen und sogar Gesichtsausdrücke, die es aus seinem Trainingsdatensatz gelernt hat. Das Resultat ist ein gestochen scharfes Bild einer Person, die Ihrer Mutter ähnlich sieht, aber mikroskopische Abweichungen aufweist – eine andere Augenform, ein verändertes Lächeln, ein Schmuckstück, das nie existierte.
Das technische Risiko trifft hier auf eine biologische Schwachstelle: Die Neuroplastizität des menschlichen Gehirns. Wenn Sie dieses neue, hyper-realistische Bild betrachten, akzeptiert Ihr Gehirn es als die „echte“ Version. Der Hippocampus, das Zentrum für Gedächtniskonsolidierung, überschreibt die vage, organische Erinnerung mit der konkreten, künstlichen Version. Dieser Vorgang wird als „Memory Conformity“ bezeichnet. Die Künstliche Intelligenz fungiert hierbei als autoritäre Quelle, deren Output wir unbewusst höher bewerten als unser eigenes, fehleranfälliges Gedächtnis.
Der Feedback-Loop des falschen Gedächtnisses

Ein weiterer technischer Aspekt, der dieses Phänomen verstärkt, ist das sogenannte Reinforcement Learning from Human Feedback (RLHF). Wenn Nutzer mit einer AI interagieren und eine generierte Antwort oder ein Bild akzeptieren („Ja, genau so sah das aus!“), wird dieses Feedback in das System zurückgespeist. Wir trainieren die Modelle darauf, uns das zu geben, was wir erwarten, nicht das, was faktisch korrekt ist.
Stellen Sie sich vor, Sie diskutieren mit einem Bot über ein Ereignis in Ihrer Kindheit. Der Bot schlägt ein plausibles Detail vor – zum Beispiel, dass an Ihrem sechsten Geburtstag ein roter Luftballon im Raum war. Statistisch gesehen ist das bei Geburtstagen sehr wahrscheinlich. Sie erinnern sich nicht daran, aber da die KI so sicher klingt und das Detail so passend wirkt, integrieren Sie es in Ihre Erzählung. Beim nächsten Abruf dieser Erinnerung wird der rote Ballon für Sie real sein. Technisch gesehen hat das Modell eine Variable in Ihren kognitiven Prozess injiziert, die dort nun als Konstante verankert ist.
Synthetische Nostalgie und die Gefahr der Homogenisierung
Die Gefahr liegt nicht nur in der individuellen Täuschung, sondern in der kollektiven Homogenisierung von Erinnerungen. Da Generative AI auf statistischen Durchschnitten basiert, tendiert sie dazu, den „Mittelwert“ der Realität zu erzeugen. Wenn Millionen von Menschen ihre Erinnerungen durch den Filter von KI-Tools laufen lassen, werden unsere individuellen Vergangenheiten langsam aneinander angeglichen.
Ein technisches Beispiel hierfür ist der „Mode Collapse“ in frühen GANs (Generative Adversarial Networks), bei dem die KI immer wieder sehr ähnliche Ausgaben produzierte, weil diese vom Diskriminator am besten bewertet wurden. Übertragen auf menschliche Erinnerungen bedeutet das: Unsere einzigartigen, oft chaotischen und unperfekten Erinnerungen werden durch glatte, perfekte, aber standardisierte KI-Narrative ersetzt. Die KI bügelt die Ecken und Kanten unserer Biografie glatt, basierend auf dem, was sie als „normale“ menschliche Erfahrung gelernt hat.
Die Rolle der Kontext-Fenster und Vektor-Datenbanken
Moderne LLMs verfügen über riesige Kontext-Fenster (Context Windows), die es ihnen ermöglichen, lange Konversationen zu führen und scheinbar persönliche Details über den Nutzer zu „behalten“. Doch auch hier lauert eine technische Falle. Die KI speichert diese Informationen nicht als biografische Fakten, sondern als temporäre Token-Sequenzen im Arbeitsspeicher.
Wenn die KI auf frühere Eingaben Bezug nimmt, rekontextualisiert sie diese oft subtil, um den aktuellen Dialogfluss zu optimieren. Ein Nutzer, der über Jahre hinweg mit einer KI interagiert, lagert Teile seines autobiografischen Gedächtnisses an ein System aus, das technisch nicht in der Lage ist, zwischen Fakt und Fiktion zu unterscheiden, sondern nur zwischen „wahrscheinlicher“ und „unwahrscheinlicher“ Wortfolge. Das externe digitale Gedächtnis wird somit zu einem unzuverlässigen Erzähler, dem wir paradoxerweise blind vertrauen.
Kurz gesagt (TL;DR)
KI-Systeme optimieren auf Plausibilität statt Wahrheit und füllen menschliche Erinnerungslücken mit statistisch wahrscheinlichen, aber oft fiktiven Details.
Das menschliche Gehirn akzeptiert halluzinierte KI-Details in restaurierten Fotos als Realität und überschreibt dabei die eigentliche biologische Erinnerung.
Durch die Bestätigung plausibler KI-Antworten integrieren Nutzer unbewusst künstliche Variablen als feste Bestandteile in ihre persönliche Biografie.
Fazit

Die Technologie der Künstlichen Intelligenz hat im Jahr 2026 einen Punkt erreicht, an dem sie nicht mehr nur unsere Zukunft gestaltet, sondern aktiv unsere Vergangenheit umschreibt. Das Geheimnis hinter dem „falschen Gedächtnis“ ist keine böswillige Absicht der Maschinen, sondern eine unvermeidliche Konsequenz ihrer Architektur: Sie sind Maschinen der Plausibilität, nicht der Wahrheit. Indem sie statistische Wahrscheinlichkeiten in fotorealistische Bilder und überzeugende Texte verwandeln, hacken sie die Schwachstellen unserer eigenen kognitiven Hardware. Wir stehen vor der technischen und philosophischen Herausforderung, unsere eigene Biografie gegen die glattgebügelte Perfektion der Algorithmen zu verteidigen. Wer sich auf die KI verlässt, um sich zu erinnern, übergibt die Autorenschaft seines Lebens an eine Wahrscheinlichkeitsrechnung.
Häufig gestellte Fragen

KI-Systeme wie LLMs greifen nicht auf eine Datenbank mit festen Fakten zu, sondern berechnen Wahrscheinlichkeiten für Wortfolgen in einem komplexen Vektorraum. Sie optimieren ihre Antworten auf Plausibilität statt auf historische Wahrheit, was bedeutet, dass sie Wissenslücken mit statistisch wahrscheinlichen Elementen füllen, die zwar extrem glaubwürdig klingen, aber oft technisch gesehen erfunden sind.
Beim sogenannten Upscaling analysieren Algorithmen unscharfe Strukturen und injizieren fehlende Details wie Hautporen oder Mimik basierend auf allgemeinen Trainingsdaten. Die KI erfindet diese Details buchstäblich neu, was zu einem gestochen scharfen Bild führt, das jedoch mikroskopische Abweichungen vom Original aufweist und somit eher eine statistische Annäherung als die echte Realität darstellt.
Dieser Begriff beschreibt das psychologische Phänomen, dass das menschliche Gehirn vage, organische Erinnerungen durch die konkreten, künstlichen Versionen einer KI überschreibt. Da der Hippocampus die hyper-realistischen Bilder oder Texte der KI als autoritäre und präzisere Quelle akzeptiert, wird die eigene, fehleranfällige Erinnerung dauerhaft durch die algorithmische Version ersetzt.
Ja, es besteht die Gefahr einer kollektiven Homogenisierung, da generative KI auf statistischen Durchschnitten basiert und somit dazu tendiert, den Mittelwert der Realität abzubilden. Wenn viele Menschen ihre Biografie durch KI-Filter laufen lassen, werden individuelle Ecken und Kanten geglättet und durch standardisierte Narrative ersetzt, die dem algorithmischen Durchschnitt entsprechen.
Durch Methoden wie Reinforcement Learning from Human Feedback lernt die KI, Antworten zu liefern, die der Nutzer erwartet oder bestätigt, anstatt strikt bei der Wahrheit zu bleiben. Wenn ein Nutzer einem plausiblen, aber falschen Detail zustimmt, validiert er dieses im System und verankert es gleichzeitig als scheinbaren Fakt in seinem eigenen kognitiven Prozess, was falsche Erinnerungen festigen kann.
Quellen und Vertiefung

- Wikipedia: Psychologische Hintergründe zu falschen Erinnerungen (False Memory)
- Europäisches Parlament: Das EU-Gesetz zur Regulierung Künstlicher Intelligenz (AI Act)
- Wikipedia: Die Rolle des Hippocampus bei der Gedächtniskonsolidierung
- National Institute of Standards and Technology (NIST): Rahmenwerk für KI-Risikomanagement (Englisch)

Fanden Sie diesen Artikel hilfreich? Gibt es ein anderes Thema, das Sie von mir behandelt sehen möchten?
Schreiben Sie es in die Kommentare unten! Ich lasse mich direkt von Ihren Vorschlägen inspirieren.