En Breve (TL;DR)
El paradigma Data Lakehouse moderniza el credit scoring unificando la gestión de datos estructurados y no estructurados en una única infraestructura escalable.
La extracción de valor de fuentes heterogéneas como documentos y logs se realiza mediante pipelines NLP avanzadas que transforman información bruta en características predictivas.
La arquitectura por capas integrada con Feature Store garantiza la gobernanza del dato y la alineación entre el entrenamiento de los modelos y la inferencia en tiempo real.
El diablo está en los detalles. 👇 Sigue leyendo para descubrir los pasos críticos y los consejos prácticos para no equivocarte.
En el panorama fintech de 2026, la capacidad de evaluar el riesgo crediticio ya no depende únicamente del historial de pagos o del saldo de la cuenta corriente. La frontera moderna es el data lakehouse credit scoring, un enfoque arquitectónico que supera la dicotomía entre Data Warehouse (excelentes para datos estructurados) y Data Lake (necesarios para datos no estructurados). Esta guía técnica explora cómo diseñar una infraestructura capaz de ingerir, procesar y servir datos heterogéneos para alimentar modelos de Machine Learning de nueva generación.

La Evolución del Credit Scoring: Más Allá de los Datos Tabulares
Tradicionalmente, el credit scoring se basaba en modelos de regresión logística alimentados por datos rígidamente estructurados procedentes de los Core Banking Systems. Sin embargo, este enfoque ignora una mina de oro de información: los datos no estructurados. Correos electrónicos de soporte, logs de chats, documentos PDF de balances e incluso metadatos de navegación ofrecen señales predictivas cruciales sobre la estabilidad financiera de un cliente o su propensión al abandono (churn).
El paradigma del Data Lakehouse emerge como la solución definitiva. Uniendo la flexibilidad del almacenamiento de bajo coste (como Amazon S3 o Google Cloud Storage) con las capacidades transaccionales y de gestión de metadatos típicas de los Warehouse (mediante tecnologías como Delta Lake, Apache Iceberg o Apache Hudi), es posible crear una Single Source of Truth para el credit scoring avanzado.
Arquitectura de Referencia para el Credit Scoring 2.0
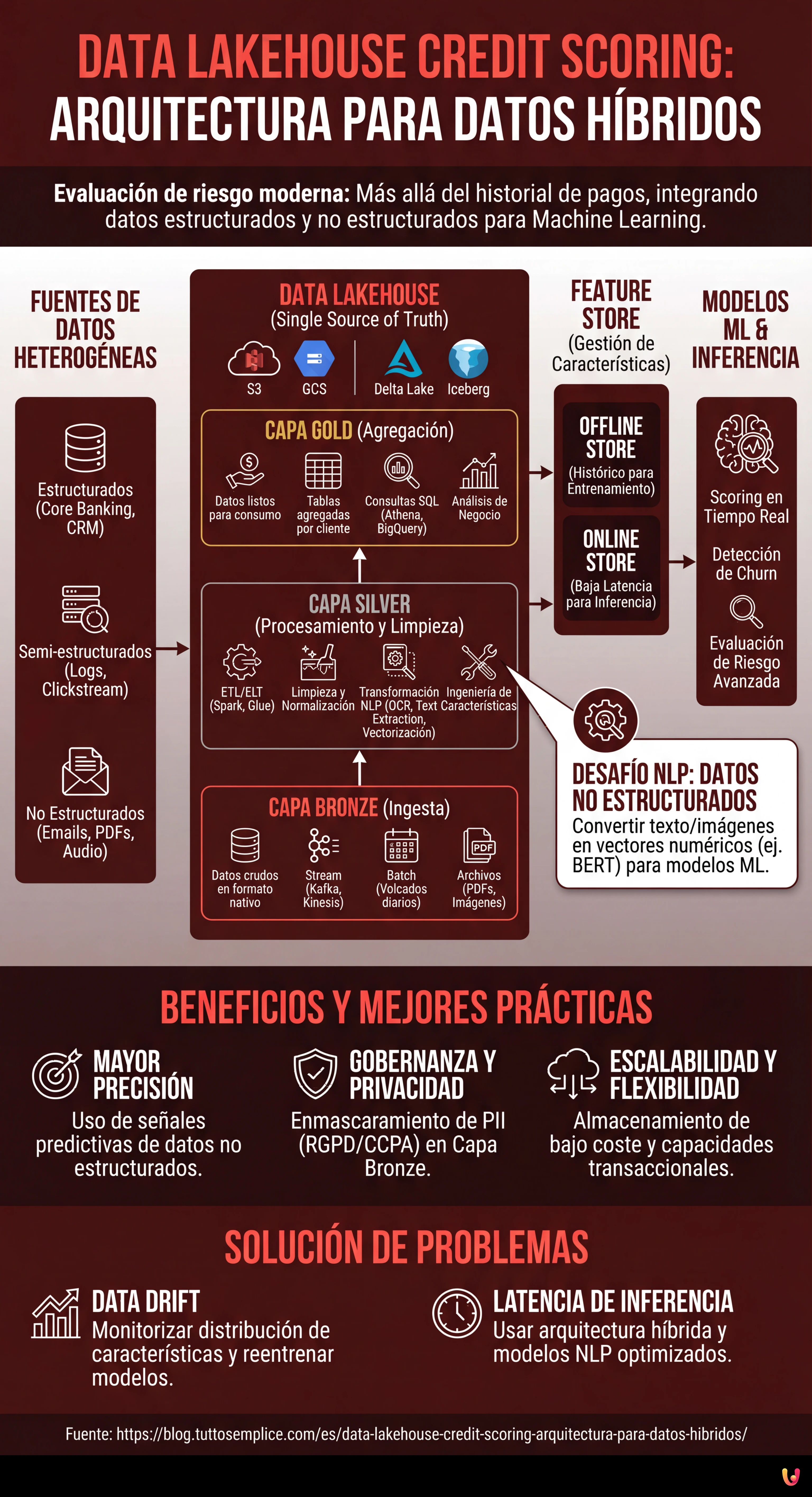
Para construir un sistema eficaz, debemos delinear una arquitectura por capas que garantice escalabilidad y gobernanza. Estos son los componentes fundamentales:
1. Capa de Ingesta (Bronze Layer)
Los datos aterrizan en el Lakehouse en su formato nativo. En un escenario de credit scoring, tendremos:
- Stream en tiempo real: Transacciones TPV, clickstream de la app móvil (vía Apache Kafka o Amazon Kinesis).
- Batch: Volcados diarios del CRM, informes de agencias de crédito externas.
- No Estructurados: PDF de nóminas, correos electrónicos, grabaciones de call center.
2. Capa de Procesamiento y Limpieza (Silver Layer)
Aquí ocurre la magia del ETL/ELT. Utilizando motores distribuidos como Apache Spark o servicios gestionados como AWS Glue, los datos se limpian, deduplican y normalizan. Es en esta fase donde los datos no estructurados se transforman en características (features) utilizables.
3. Capa de Agregación (Gold Layer)
Los datos están listos para el consumo de negocio y para el análisis, organizados en tablas agregadas por cliente, listas para ser consultadas vía SQL (ej. Athena, BigQuery o Databricks SQL).
Integración de Datos No Estructurados: El Desafío NLP

La verdadera innovación en el data lakehouse credit scoring reside en la extracción de características de texto e imágenes. No podemos insertar un PDF en un modelo XGBoost, por lo que debemos procesarlo en la Silver Layer.
Supongamos que queremos analizar los correos electrónicos intercambiados con el servicio de atención al cliente para detectar señales de estrés financiero. El proceso prevé:
- OCR y Text Extraction: Uso de librerías como Tesseract o servicios cloud (AWS Textract) para convertir PDF/Imágenes en texto.
- NLP Pipeline: Aplicación de modelos Transformer (ej. BERT ajustado para el dominio financiero) para extraer entidades (NER) o analizar el sentimiento.
- Feature Vectorization: Conversión del resultado en vectores numéricos o puntuaciones categóricas (ej. “Sentiment_Score_Last_30_Days”).
El Papel Crucial del Feature Store
Uno de los problemas más comunes en MLOps es el training-serving skew: las características calculadas durante el entrenamiento del modelo difieren de las calculadas en tiempo real durante la inferencia (cuando el cliente solicita un préstamo desde la app). Para resolver este problema, la arquitectura Lakehouse debe integrar un Feature Store (como Feast, Hopsworks o SageMaker Feature Store).
El Feature Store gestiona dos vistas:
- Offline Store: Basado en el Data Lakehouse, contiene el histórico profundo para el entrenamiento de los modelos.
- Online Store: Una base de datos de baja latencia (ej. Redis o DynamoDB) que sirve el último valor conocido de las características para la inferencia en tiempo real.
Ejemplo Práctico: Pipeline ETL con PySpark
A continuación, un ejemplo conceptual de cómo un trabajo Spark podría unir datos transaccionales estructurados con puntuaciones de sentimiento derivadas de datos no estructurados dentro de una arquitectura Delta Lake.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, current_timestamp
# Inicialización de Spark con soporte Delta Lake
spark = SparkSession.builder
.appName("CreditScoringETL")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
# 1. Carga de Datos Estructurados (Transacciones)
df_transactions = spark.read.format("delta").load("s3://datalake/silver/transactions")
# Ingeniería de características: Gasto medio últimos 30 días
feat_avg_spend = df_transactions.groupBy("customer_id")
.agg(avg("amount").alias("avg_monthly_spend"))
# 2. Carga de Datos No Estructurados Procesados (Logs Chat/Email)
# Asumimos que una pipeline NLP anterior ha guardado los puntajes de sentimiento
df_sentiment = spark.read.format("delta").load("s3://datalake/silver/customer_sentiment")
# Ingeniería de características: Sentimiento medio
feat_sentiment = df_sentiment.groupBy("customer_id")
.agg(avg("sentiment_score").alias("avg_sentiment_risk"))
# 3. Join para crear el Conjunto de Características Unificado
final_features = feat_avg_spend.join(feat_sentiment, "customer_id", "left_outer")
.fillna({"avg_sentiment_risk": 0.5}) # Gestión de nulos
# 4. Escritura en el Feature Store (Capa Offline)
final_features.write.format("delta")
.mode("overwrite")
.save("s3://datalake/gold/credit_scoring_features")
print("Pipeline completada: Feature Store actualizado.")
Solución de Problemas y Buenas Prácticas
Al implementar un sistema de data lakehouse credit scoring, es común encontrar obstáculos específicos. He aquí cómo mitigarlos:
Gestión de la Privacidad (RGPD/CCPA)
Los datos no estructurados contienen a menudo PII (Información de Identificación Personal) sensible. Es imperativo implementar técnicas de enmascaramiento o tokenización en la Bronze Layer, antes de que los datos sean accesibles para los Data Scientists. Herramientas como Presidio de Microsoft pueden automatizar la anonimización del texto.
Deriva de Datos (Data Drift)
El comportamiento de los clientes cambia. Un modelo entrenado con datos de 2024 podría no ser válido en 2026. Monitorizar la distribución estadística de las características en el Feature Store es esencial para activar el reentrenamiento automático de los modelos.
Latencia en la Inferencia
Si el cálculo de las características no estructuradas (ej. análisis de un PDF cargado al momento) es demasiado lento, la experiencia de usuario se resiente. En estos casos, se recomienda una arquitectura híbrida: precalcular todo lo posible en batch (histórico) y utilizar modelos NLP ligeros y optimizados (ej. DistilBERT sobre ONNX) para el procesamiento en tiempo real.
Conclusiones

Adoptar un enfoque de Data Lakehouse para el credit scoring no es solo una actualización tecnológica, sino una ventaja competitiva estratégica. Centralizando datos estructurados y no estructurados y garantizando su coherencia mediante un Feature Store, las instituciones financieras pueden construir perfiles de riesgo holísticos, reduciendo los impagos y personalizando la oferta para el cliente. La clave del éxito reside en la calidad de la pipeline de ingeniería de datos: un modelo de IA es tan válido como los datos que lo alimentan.
Preguntas frecuentes

El Data Lakehouse Credit Scoring es un modelo arquitectónico híbrido que supera los límites de los Data Warehouse tradicionales uniendo la gestión de los datos estructurados con la flexibilidad de los Data Lakes. Este enfoque permite a las fintech aprovechar fuentes no estructuradas, como correos electrónicos y documentos, para calcular el riesgo crediticio con mayor precisión, reduciendo la dependencia exclusiva de los historiales de pago.
Los datos no estructurados, como PDF o logs de chat, se procesan en la Silver Layer mediante pipelines de NLP y OCR. Estas tecnologías convierten el texto y las imágenes en vectores numéricos o puntuaciones de sentimiento, transformando información cualitativa en características cuantitativas que los modelos predictivos pueden analizar para evaluar la fiabilidad del cliente.
El Feature Store actúa como un sistema central para garantizar la coherencia de los datos entre la fase de entrenamiento y la de inferencia. Elimina el desajuste conocido como «training-serving skew» manteniendo dos vistas sincronizadas: un Offline Store para el histórico profundo y un Online Store de baja latencia para proporcionar datos actualizados en tiempo real durante las solicitudes de crédito.
La infraestructura se organiza en tres estadios principales: la Bronze Layer para la ingesta de datos brutos, la Silver Layer para la limpieza y el enriquecimiento mediante algoritmos de procesamiento, y la Gold Layer donde los datos están agregados y listos para el uso empresarial. Esta estructura por capas asegura escalabilidad, gobernanza y calidad del dato a lo largo de todo el ciclo de vida.
La protección de la información personal se realiza implementando técnicas de enmascaramiento y tokenización directamente en el nivel de ingesta, la Bronze Layer. Utilizando herramientas específicas para la anonimización automática, es posible analizar los comportamientos y las tendencias a partir de los datos no estructurados sin exponer las identidades de los clientes ni violar normativas como el RGPD.

¿Te ha resultado útil este artículo? ¿Hay otro tema que te gustaría que tratara?
¡Escríbelo en los comentarios aquí abajo! Me inspiro directamente en vuestras sugerencias.