
L’addestramento dei modelli linguistici di grandi dimensioni ha subito una trasformazione radicale con l’introduzione di Vitruvian-1. Nel panorama dell’Informatica del 2026, non è più sufficiente affidarsi esclusivamente al feedback umano (RLHF) per l’ottimizzazione delle policy. Per garantire un’accuratezza assoluta nelle risposte tecniche, ingegneristiche e matematiche, l’industria si è spostata verso l’uso di verificatori deterministici. Questa guida tecnica esplora in dettaglio l’architettura di validazione, spiegando come i test unitari e le verifiche matematiche vengano integrati direttamente nel loop di Reinforcement Learning (RL) per eliminare le allucinazioni e massimizzare l’affidabilità del codice generato.
Introduzione al Reinforcement Learning Deterministico
Nel contesto di Vitruvian-1, per valutare le metriche: come interpretare verificato e non verificato cambia radicalmente l’approccio al Reinforcement Learning. L’uso di test unitari e verificatori matematici garantisce che le risposte tecniche siano esatte, superando i limiti delle tradizionali ricompense probabilistiche.
Il Reinforcement Learning tradizionale applicato agli LLM si è storicamente basato su Reward Models addestrati su preferenze umane. Tuttavia, quando si tratta di domini esatti come la programmazione o la matematica avanzata, la preferenza umana è lenta, costosa e soggetta a errori. Vitruvian-1 introduce un paradigma basato su RLAIF (Reinforcement Learning from AI/Algorithmic Feedback), dove l’ambiente di RL è costituito da compilatori, interpreti e risolutori simbolici (come SymPy o Lean). In questo ecosistema, il modello riceve una ricompensa positiva solo se il codice compila, viene eseguito senza errori e supera una suite rigorosa di test unitari nascosti.
Prerequisiti e Strumenti di Valutazione
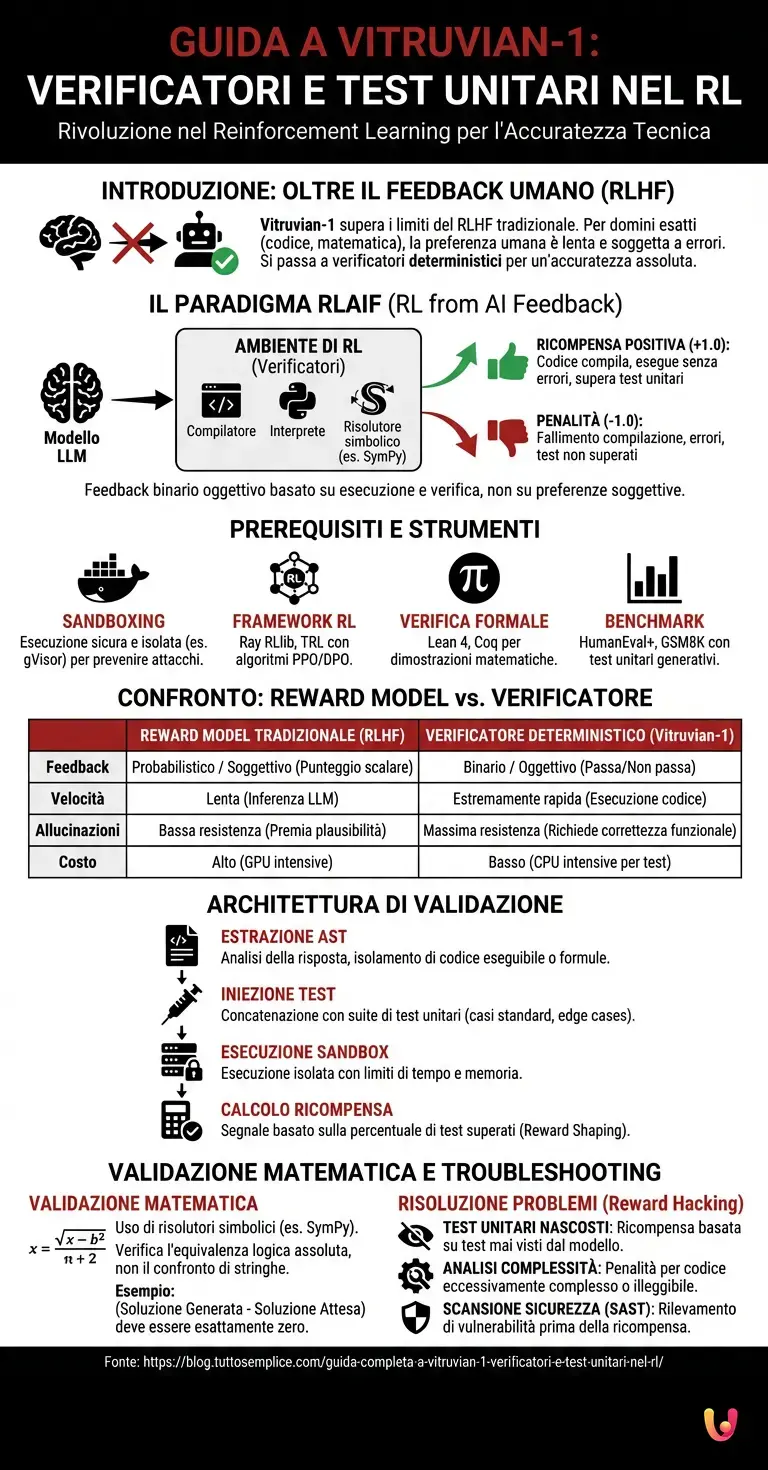
Prima di approfondire come valutare le metriche: come interpretare verificato in ambienti complessi, è necessario padroneggiare strumenti specifici. I prerequisiti includono framework di Reinforcement Learning, sandbox di esecuzione del codice e librerie di verifica formale per la matematica avanzata.
Per implementare o comprendere appieno la pipeline di addestramento di un modello come Vitruvian-1, gli ingegneri del machine learning devono avere familiarità con un set di strumenti altamente specializzati. Secondo la documentazione ufficiale dei moderni framework di RL, l’infrastruttura richiede:
- Ambienti di Sandboxing: Container Docker isolati (es. gVisor) per eseguire il codice generato dall’IA in totale sicurezza, prevenendo attacchi di esecuzione di codice in modalità kernel.
- Framework RL: Librerie come Ray RLlib o TRL (Transformer Reinforcement Learning) configurate per algoritmi PPO (Proximal Policy Optimization) o DPO (Direct Preference Optimization).
- Motori di Verifica Formale: Strumenti come Lean 4 o Coq per la dimostrazione automatica di teoremi matematici generati dal modello.
- Suite di Benchmark: Dataset standardizzati come HumanEval+ e GSM8K, estesi con test unitari generativi.
Il Ruolo dei Verificatori Deterministici nel Training

I verificatori deterministici sono algoritmi che restituiscono un feedback binario oggettivo. Per valutare le metriche: come interpretare verificato significa analizzare se il codice generato passa i test unitari o se la dimostrazione matematica rispetta gli assiomi, eliminando le allucinazioni del modello.
A differenza dei modelli di ricompensa basati su reti neurali, che restituiscono un punteggio scalare continuo (es. 0.85 per una “buona” risposta), i verificatori deterministici operano su logica booleana o su metriche di copertura del codice. Se Vitruvian-1 genera una funzione per ordinare un array, il verificatore non valuta lo stile del codice, ma la sua correttezza funzionale attraverso casi limite (edge cases). Questo approccio previene il fenomeno del sycophancy, dove il modello cerca di compiacere l’utente umano fornendo risposte plausibili ma tecnicamente errate.
| Caratteristica | Reward Model Tradizionale (RLHF) | Verificatore Deterministico (Vitruvian-1) |
|---|---|---|
| Natura del Feedback | Probabilistico / Soggettivo | Binario / Oggettivo |
| Velocità di Inferenza | Lenta (richiede inferenza di un LLM) | Estremamente rapida (esecuzione di codice) |
| Resistenza alle Allucinazioni | Bassa (può premiare codice che “sembra” corretto) | Massima (il codice deve funzionare realmente) |
| Costo Computazionale | Alto (GPU intensive) | Basso (CPU intensive per i test) |
Architettura di Vitruvian-1 per i Test Unitari
L’architettura di Vitruvian-1 integra un compilatore interno durante la fase di RL. Quando andiamo a valutare le metriche: come interpretare verificato si traduce nell’esecuzione in tempo reale di test unitari isolati, fornendo una ricompensa positiva solo se l’output è funzionalmente corretto.
Il processo di addestramento di Vitruvian-1 segue una pipeline rigorosa e automatizzata. Quando il modello genera una soluzione tecnica, questa non viene inviata direttamente all’aggiornamento della policy. Al contrario, attraversa le seguenti fasi:
- Estrazione dell’AST (Abstract Syntax Tree): Il sistema analizza la risposta del modello, estraendo solo i blocchi di codice eseguibile o le formule matematiche, ignorando il testo discorsivo.
- Iniezione dei Test: Il codice estratto viene concatenato con una suite di test unitari (spesso generati dinamicamente tramite mutational testing) che coprono casi standard, array vuoti, input negativi e limiti di memoria.
- Esecuzione in Sandbox: Il pacchetto completo viene eseguito in un ambiente isolato con limiti rigorosi di tempo (timeout) e memoria (OOM limits).
- Calcolo della Ricompensa (Reward Shaping): Il segnale di ricompensa viene calcolato in base alla percentuale di test superati. Un fallimento di compilazione restituisce una penalità severa (-1.0), mentre il superamento di tutti i test fornisce la ricompensa massima (+1.0).
Esempi Pratici di Validazione Matematica
Analizzando casi d’uso reali, per valutare le metriche: come interpretare verificato richiede l’uso di risolutori simbolici. Se Vitruvian-1 genera un’equazione, il verificatore matematico la confronta con la soluzione attesa, assegnando il punteggio massimo solo in caso di equivalenza logica assoluta.
Prendiamo in esame un problema di calcolo differenziale. Se il prompt richiede di calcolare la derivata di una funzione complessa, Vitruvian-1 genera i passaggi e il risultato finale. In base ai dati di settore sulle architetture di validazione, il sistema utilizza librerie come SymPy in Python per verificare l’output. Il verificatore non esegue un semplice confronto di stringhe (che fallirebbe se il modello scrivesse “x+1” invece di “1+x”), ma costruisce un albero matematico. Sottraendo la soluzione generata da Vitruvian-1 alla soluzione di riferimento (Ground Truth) e semplificando l’espressione, il verificatore controlla se il risultato è esattamente zero. Solo in questo caso il flag “verificato” viene attivato, innescando un aggiornamento positivo dei pesi del modello tramite l’algoritmo PPO.
Risoluzione dei Problemi Comuni e Falsi Positivi
Durante il training, possono emergere anomalie nei benchmark. Per valutare le metriche: come interpretare verificato in modo corretto, bisogna gestire i falsi positivi, come codice che passa i test unitari ma presenta vulnerabilità di sicurezza o inefficienze computazionali nascoste.
Uno dei problemi più noti nel Reinforcement Learning applicato al codice è il Reward Hacking. Il modello potrebbe imparare a superare i test unitari in modi imprevisti, ad esempio hardcodando le risposte se i casi di test sono prevedibili, o scrivendo codice che consuma risorse eccessive pur restituendo l’output corretto. Per mitigare questi problemi, il team di sviluppo di Vitruvian-1 implementa diverse strategie di troubleshooting:
- Test Unitari Nascosti (Holdout Tests): Il modello viene addestrato su un set di test visibili, ma la ricompensa finale dipende da test che il modello non ha mai visto durante la generazione.
- Analisi della Complessità Ciclomatica: Oltre alla correttezza funzionale, il verificatore penalizza il codice eccessivamente complesso o illeggibile, promuovendo soluzioni eleganti e pythonic.
- Scansione di Sicurezza Statica (SAST): Prima di assegnare la ricompensa, il codice passa attraverso analizzatori statici che cercano vulnerabilità comuni (es. SQL injection o buffer overflow). Se viene rilevata una vulnerabilità, il flag “verificato” viene revocato.
In Breve (TL;DR)
Vitruvian-1 rivoluziona l’addestramento dei modelli linguistici superando il tradizionale feedback umano per abbracciare un approccio basato su rigorosi verificatori deterministici.
Questo innovativo sistema integra test unitari e risolutori matematici nel Reinforcement Learning, fornendo ricompense positive solo per output perfettamente funzionanti.
Grazie a questa architettura avanzata si eliminano le allucinazioni del codice, massimizzando la totale affidabilità tecnica delle soluzioni proposte dalla intelligenza artificiale.
Conclusioni

In sintesi, per valutare le metriche: come interpretare verificato rappresenta il futuro dell’addestramento dei modelli linguistici. L’approccio di Vitruvian-1, basato su test unitari e rigore matematico, stabilisce un nuovo standard per l’affidabilità e l’accuratezza delle intelligenze artificiali in ambito tecnico.
L’integrazione di verificatori deterministici nel loop di Reinforcement Learning segna il passaggio definitivo dalle IA probabilistiche alle IA ingegneristiche. Vitruvian-1 dimostra che, fornendo ai modelli un ambiente in cui possono testare, fallire e correggere il proprio codice in modo autonomo prima di fornire la risposta finale, è possibile raggiungere livelli di performance sui benchmark tecnici (come HumanEval e SWE-bench) precedentemente inimmaginabili. Comprendere e padroneggiare queste metriche di verifica è oggi la competenza fondamentale per chiunque lavori nello sviluppo e nell’ottimizzazione dei Foundation Models di nuova generazione.
Domande frequenti

Vitruvian-1 trasforma la fase di addestramento delle intelligenze artificiali integrando verificatori deterministici e test unitari nel ciclo di Reinforcement Learning. Questo approccio elimina le allucinazioni e garantisce la massima affidabilità per la generazione di codice informatico e soluzioni matematiche complesse.
Il feedback umano risulta spesso lento e soggettivo quando si valutano domini esatti come la programmazione. I verificatori deterministici offrono invece un riscontro binario e oggettivo basato sulla reale esecuzione del codice. Questo sistema previene risposte solo apparentemente corrette e assicura che il risultato finale funzioni davvero senza errori.
Il sistema utilizza risolutori simbolici avanzati per confrontare la soluzione generata con quella di riferimento. Invece di fare un banale confronto testuale, il verificatore costruisce un albero matematico e controlla la totale equivalenza logica tra le due espressioni. Il modello riceve una ricompensa positiva solamente se il risultato della sottrazione tra le due formule equivale a zero.
Per evitare che il modello impari a ingannare il sistema superando i test in modi imprevisti, gli sviluppatori utilizzano test unitari nascosti e analisi della complessità del codice. Inoltre, prima di assegnare la ricompensa finale, il codice viene sottoposto a scansioni di sicurezza statiche per bloccare eventuali inefficienze o vulnerabilità informatiche.
Gli ingegneri devono padroneggiare ambienti di esecuzione isolati per testare il codice in totale sicurezza. Sono necessari framework di Reinforcement Learning per ottimizzare le policy e motori di verifica formale per dimostrare i teoremi matematici. A questi si aggiungono dataset standardizzati arricchiti con test unitari generativi per valutare le prestazioni complessive.
Hai ancora dubbi su Guida Completa a Vitruvian-1: Verificatori e Test Unitari nel RL?
Digita qui la tua domanda specifica per trovare subito la risposta ufficiale di Google.
Fonti e Approfondimenti

- Apprendimento per rinforzo basato sul feedback umano (RLHF) e RLAIF – Wikipedia
- Framework per la valutazione e la gestione del rischio dell’Intelligenza Artificiale (AI RMF) – NIST (Governo USA)
- Proximal Policy Optimization (PPO): Algoritmi di Reinforcement Learning – Wikipedia
- Lean Proof Assistant: Strumenti per la dimostrazione di teoremi e verifica formale – Wikipedia
- Fondamenti di Apprendimento per Rinforzo (Reinforcement Learning) – Wikipedia



Hai trovato utile questo articolo? C’è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.