In Breve (TL;DR)
La migrazione dei sistemi legacy nel settore bancario richiede strategie evolute per decodificare stratificazioni logiche complesse e spesso prive di documentazione.
L’impiego avanzato del Prompt Engineering e degli LLM permette di trasformare il reverse engineering in un’estrazione precisa delle regole di business.
Metodologie come Chain-of-Thought assicurano la parità funzionale decompilando la semantica degli algoritmi critici invece di tradurne semplicemente la sintassi.
Il diavolo è nei dettagli. 👇 Continua a leggere per scoprire i passaggi critici e i consigli pratici per non sbagliare.
Siamo nel 2026 e la modernizzazione delle infrastrutture IT non è più un’opzione, ma un imperativo di sopravvivenza, specialmente nel settore bancario e assicurativo. La migrazione sistemi legacy verso il cloud rappresenta una delle sfide più complesse per i CIO e i Software Architect. Non si tratta semplicemente di spostare codice da un mainframe a un container Kubernetes; la vera sfida risiede nella comprensione profonda di decenni di stratificazioni logiche, spesso non documentate.
In questo deep dive tecnico, esploreremo come l’utilizzo avanzato dei Large Language Models (LLM) e del Prompt Engineering possa trasformare il processo di reverse engineering. Non parleremo di semplice generazione di codice (come ‘traduci questo COBOL in Python’), ma di un approccio metodico all’estrazione della logica di business (Business Rules Extraction) e alla garanzia della parità funzionale tramite test automatizzati.

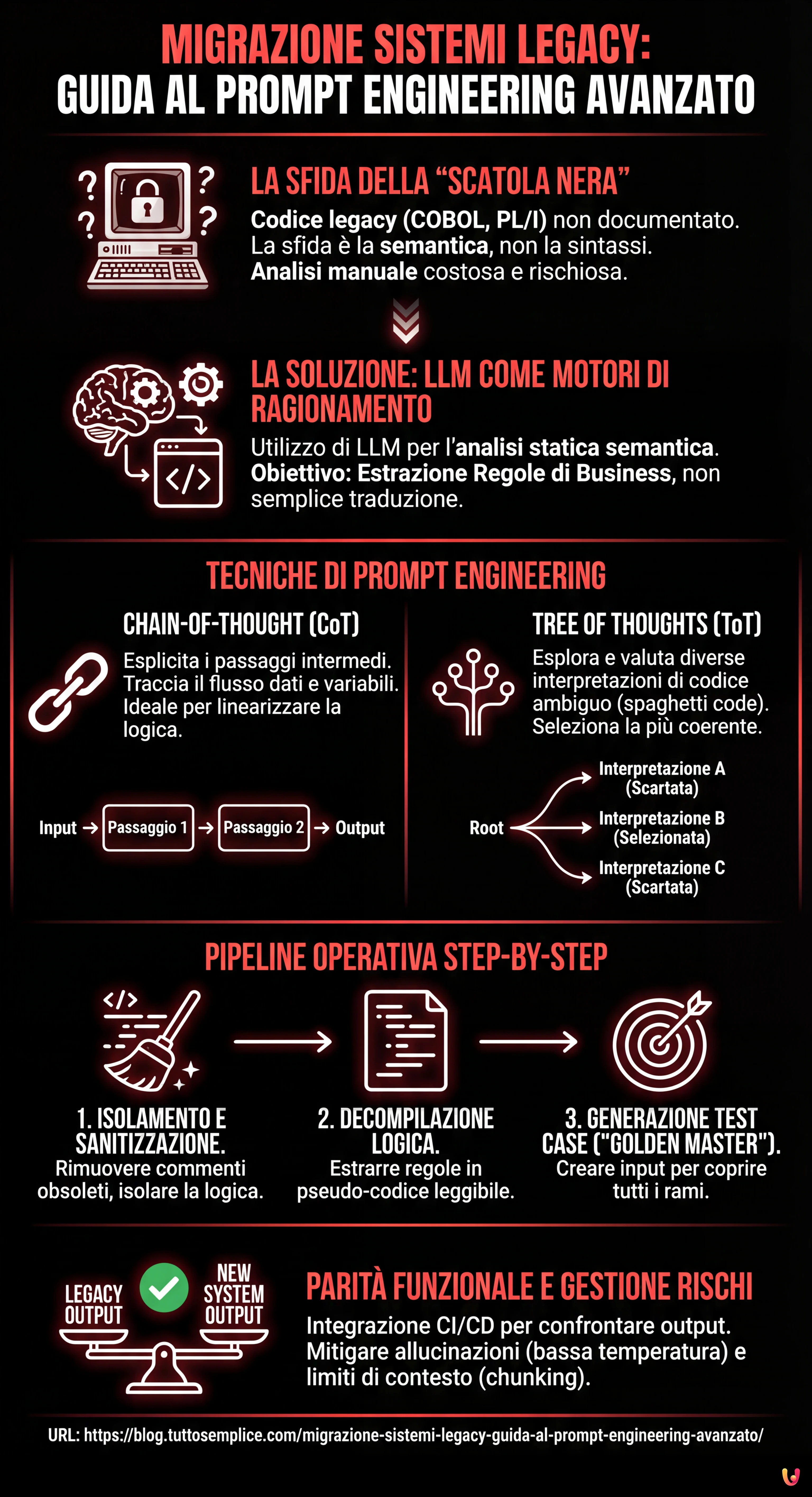
Il Problema della Scatola Nera nei Sistemi Bancari
Molti sistemi mission-critical operano su codebase scritte in COBOL, PL/I o Fortran negli anni ’80 o ’90. Il problema principale nella migrazione sistemi legacy non è la sintassi, ma la semantica. Spesso, la documentazione è assente o disallineata rispetto al codice in produzione. Gli sviluppatori originali sono andati in pensione e il codice stesso è diventato l’unica fonte di verità.
L’approccio tradizionale prevede l’analisi manuale, costosa e soggetta a errori umani. L’approccio moderno, potenziato dall’IA, utilizza gli LLM come motori di ragionamento per eseguire una analisi statica semantica. L’obiettivo è decompilare l’algoritmo, non solo tradurlo.
Prerequisiti e Strumenti
Per seguire questa guida, è necessario disporre di:
- Accesso a LLM con finestre di contesto ampie (es. GPT-4o, Claude 3.5 Sonnet o modelli open source come Llama 4 ottimizzati per il codice).
- Accesso in lettura alla codebase legacy (snippet COBOL/JCL).
- Un ambiente di orchestrazione (Python/LangChain) per automatizzare le pipeline di prompt.
Tecniche di Prompt Engineering per l’Analisi del Codice

Per estrarre regole di business complesse, come il calcolo di un piano di ammortamento alla francese con eccezioni specifiche per valuta, non basta un prompt zero-shot. Dobbiamo guidare il modello attraverso processi cognitivi strutturati.
1. Chain-of-Thought (CoT) per la Linearizzazione della Logica
La tecnica Chain-of-Thought spinge il modello a esplicitare i passaggi intermedi del ragionamento. Nella migrazione sistemi legacy, questo è cruciale per tracciare il flusso dei dati attraverso variabili globali oscure.
Esempio di Prompt CoT:
SYSTEM: Sei un Senior Mainframe Analyst specializzato in COBOL e logica bancaria. USER: Analizza il seguente paragrafo COBOL 'CALC-RATA'. Non tradurlo ancora. Usa un approccio Chain-of-Thought per: 1. Identificare tutte le variabili di input e output. 2. Tracciare come la variabile 'WS-INT-RATE' viene modificata riga per riga. 3. Spiegare la logica matematica sottostante in linguaggio naturale. 4. Evidenziare eventuali 'magic numbers' o costanti hardcoded. CODICE: [Inserire Snippet COBOL]
2. Tree of Thoughts (ToT) per la Disambiguazione
Il codice legacy è spesso ricco di istruzioni GO TO e logiche condizionali nidificate (Spaghetti Code). Qui, la tecnica Tree of Thoughts è superiore. Permette al modello di esplorare diverse interpretazioni possibili di un blocco di codice ambiguo, valutarle e scartare quelle illogiche.
Strategia ToT applicata:
- Generazione: Chiedere al modello di proporre 3 diverse interpretazioni funzionali di un blocco
PERFORM VARYINGcomplesso. - Valutazione: Chiedere al modello di agire come un “Critico” e valutare quale delle 3 interpretazioni è più coerente con il contesto bancario standard (es. regole Basilea III).
- Selezione: Mantenere l’interpretazione vincente come base per la specifica funzionale.
Pipeline di Estrazione: Step-by-Step
Ecco come strutturare una pipeline operativa per supportare la migrazione sistemi legacy:
Fase 1: Isolamento e Sanitizzazione
Prima di inviare il codice all’LLM, rimuovere commenti obsoleti che potrebbero causare allucinazioni (es. “TODO: fix this in 1998”). Isolare le routine di calcolo (Business Logic) da quelle di I/O o gestione database.
Fase 2: Decompilazione Logica (Il Prompt “Architect”)
Utilizzare un prompt strutturato per generare uno pseudo-codice agnostico. L’obiettivo è ottenere una specifica che un umano possa leggere.
PROMPT: Analizza il codice fornito. Estrai ESCLUSIVAMENTE le regole di business. Output richiesto in formato Markdown: - Nome Regola - Precondizioni - Formula Matematica (in formato LaTeX) - Postcondizioni - Eccezioni gestite
Fase 3: Generazione dei Test Case (Il “Golden Master”)
Questo è il passaggio critico per la sicurezza. Usiamo l’LLM per generare input di test che coprano tutti i rami condizionali (Branch Coverage) identificati nella fase precedente.
Integrazione CI/CD e Parity Testing
Una migrazione sistemi legacy di successo non termina con la riscrittura del codice, ma con la prova che il nuovo sistema (es. in Java o Go) si comporti esattamente come il vecchio.
Automazione dei Test di Parità
Possiamo integrare gli LLM nella pipeline CI/CD (es. Jenkins o GitLab CI) per creare unit test dinamici:
- Input Generation: L’LLM analizza la logica estratta e genera un file JSON con 100 casi di test (edge cases inclusi, come tassi negativi o anni bisestili).
- Legacy Execution: Eseguire questi input contro il sistema legacy (o un emulatore) e registrare gli output. Questo diventa il nostro “Golden Master”.
- New System Execution: Eseguire gli stessi input contro il nuovo microservizio.
- Comparison: Se gli output divergono, la pipeline fallisce.
L’IA può essere utilizzata anche in fase di debug: se il test fallisce, si può fornire all’LLM il codice legacy, il nuovo codice e il diff dell’output, chiedendo: “Perché questi due algoritmi producono risultati diversi per l’input X?”.
Troubleshooting e Rischi
Gestione delle Allucinazioni
Gli LLM possono inventare logiche se il codice è troppo criptico. Per mitigare questo rischio:
- Impostare la
temperaturea 0 o valori molto bassi (0.1/0.2) per massimizzare il determinismo. - Richiedere sempre riferimenti alle righe di codice originali nella spiegazione (Citations).
Limiti della Finestra di Contesto
Non tentare di analizzare interi programmi monolitici in un solo prompt. Utilizzare tecniche di chunking intelligente, dividendo il codice per paragrafi o sezioni logiche, mantenendo un riassunto del contesto globale (Global State Summary) che viene passato in ogni prompt successivo.
Conclusioni

L’utilizzo del Prompt Engineering avanzato trasforma la migrazione sistemi legacy da un’operazione di “archeologia informatica” a un processo ingegneristico controllato. Tecniche come Chain-of-Thought e Tree of Thoughts ci permettono di estrarre il valore intellettuale intrappolato nel codice obsoleto, garantendo che la logica di business che sostiene l’istituto finanziario venga preservata intatta nel passaggio al cloud. Non stiamo solo riscrivendo codice; stiamo salvando la conoscenza aziendale.
Domande frequenti

L’utilizzo di tecniche avanzate di Prompt Engineering, come Chain-of-Thought e Tree of Thoughts, trasforma la migrazione da una semplice traduzione sintattica a un processo di ingegneria semantica. Invece di limitarsi a convertire codice obsoleto come il COBOL in linguaggi moderni, gli LLM agiscono come motori di ragionamento per estrarre la logica di business stratificata e spesso non documentata. Questo approccio permette di decompilare gli algoritmi, identificare le regole aziendali critiche e generare specifiche funzionali chiare, riducendo drasticamente gli errori umani e preservando il valore intellettuale del software originale.
La tecnica Chain-of-Thought (CoT) guida il modello a esplicitare i passaggi intermedi del ragionamento, risultando essenziale per linearizzare la logica e tracciare il flusso dei dati attraverso variabili globali in codici lineari. Al contrario, il Tree of Thoughts (ToT) è superiore nella gestione di codice ambiguo o ricco di istruzioni condizionali nidificate, tipico dello spaghetti code. Il ToT permette al modello di esplorare diverse interpretazioni funzionali simultaneamente, valutarle come un critico esperto e selezionare quella più coerente con il contesto bancario o le normative vigenti, scartando le ipotesi illogiche.
La parità funzionale si ottiene attraverso una rigorosa pipeline di test automatizzati, spesso definita approccio Golden Master. Gli LLM vengono utilizzati per generare una vasta gamma di casi di test, inclusi scenari limite, basandosi sulla logica estratta. Questi input vengono eseguiti sia sul sistema legacy originale sia sul nuovo microservizio. I risultati vengono confrontati automaticamente: se gli output divergono, la pipeline di integrazione continua segnala l’errore. Questo metodo assicura che il nuovo sistema, scritto in linguaggi moderni come Java o Go, replichi esattamente il comportamento matematico e logico del predecessore.
Il rischio principale è rappresentato dalle allucinazioni, ovvero la tendenza del modello a inventare logiche inesistenti quando il codice è troppo criptico. Un altro limite è la dimensione della finestra di contesto che impedisce l’analisi di programmi monolitici interi. Per mitigare questi problemi, è fondamentale impostare la temperatura del modello a valori vicini allo zero per massimizzare il determinismo e richiedere sempre citazioni delle righe di codice originali. Inoltre, si adotta una strategia di chunking intelligente, dividendo il codice in sezioni logiche e mantenendo un riassunto dello stato globale per preservare il contesto durante l’analisi.
Nei sistemi mission-critical sviluppati decenni fa, la documentazione è spesso assente, incompleta o, peggio, disallineata rispetto al codice effettivamente in produzione. Con il pensionamento degli sviluppatori originali, il codice sorgente è diventato l’unica fonte di verità affidabile. Affidarsi alla documentazione cartacea o ai commenti nel codice, che potrebbero riferirsi a modifiche di molti anni fa, può portare a gravi errori di interpretazione. L’analisi statica semantica tramite IA permette di ignorare questi artefatti obsoleti e concentrarsi esclusivamente sulla logica operativa attuale.
Fonti e Approfondimenti

- Gazzetta Ufficiale UE – Regolamento DORA sulla resilienza operativa digitale nel settore finanziario
- Wikipedia – Definizione e problematiche dei Sistemi Legacy
- NIST – Framework governativo USA per la gestione dei rischi dell’Intelligenza Artificiale
- Autorità Bancaria Europea (EBA) – Linee guida sulla gestione dei rischi ICT e di sicurezza
- Wikipedia – Approfondimento tecnico sul Prompt Engineering
- Wikipedia – Storia e struttura del linguaggio COBOL

Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.