
Nel panorama tecnologico del 2026, per un imprenditore tecnico o un CTO di una realtà Fintech, l’infrastruttura non è più solo un centro di costo, ma un asset strategico che determina la marginalità del business. L’ottimizzazione costi cloud non riguarda più semplicemente la riduzione della fattura a fine mese; è una disciplina ingegneristica complessa che richiede un approccio culturale noto come FinOps. In ambienti ad alto carico, dove la scalabilità deve garantire la continuità operativa finanziaria (si pensi al trading ad alta frequenza o alla gestione dei mutui in real-time), tagliare i costi senza criterio è un rischio inaccettabile.
Questa guida tecnica esplora come applicare metodologie FinOps avanzate su piattaforme come AWS e Google Cloud, superando il concetto basilare di rightsizing per abbracciare architetture elastiche, tiering intelligente dello storage e gestione granulare del traffico dati.
1. Il Framework FinOps: Oltre il Risparmio, verso l’Efficienza
Secondo la FinOps Foundation, il FinOps è un modello operativo per il cloud che combina sistemi, best practice e cultura per aumentare la capacità di un’organizzazione di comprendere i costi del cloud e prendere decisioni di business consapevoli. In una Fintech, questo significa che ogni ingegnere deve essere consapevole dell’impatto economico di una riga di codice o di una scelta architetturale.
Prerequisiti per l’Ottimizzazione
Prima di implementare modifiche tecniche, è necessario stabilire una base di osservabilità:
- Tagging Strategy Aggressiva: Ogni risorsa deve avere tag obbligatori (es.
CostCenter,Environment,ServiceOwner). Senza questo, l’attribuzione dei costi è impossibile. - Budget e Alerting: Configurazione di AWS Budgets o GCP Budget Alerts non solo su soglie fisse, ma su anomalie di trend (es. un picco improvviso di chiamate API).
- Unit Economics: Definire il costo per transazione o per utente attivo. L’obiettivo non è abbassare il costo totale se il business cresce, ma abbassare il costo unitario.
2. Compute Optimization: Strategie per Carichi di Lavoro Misti
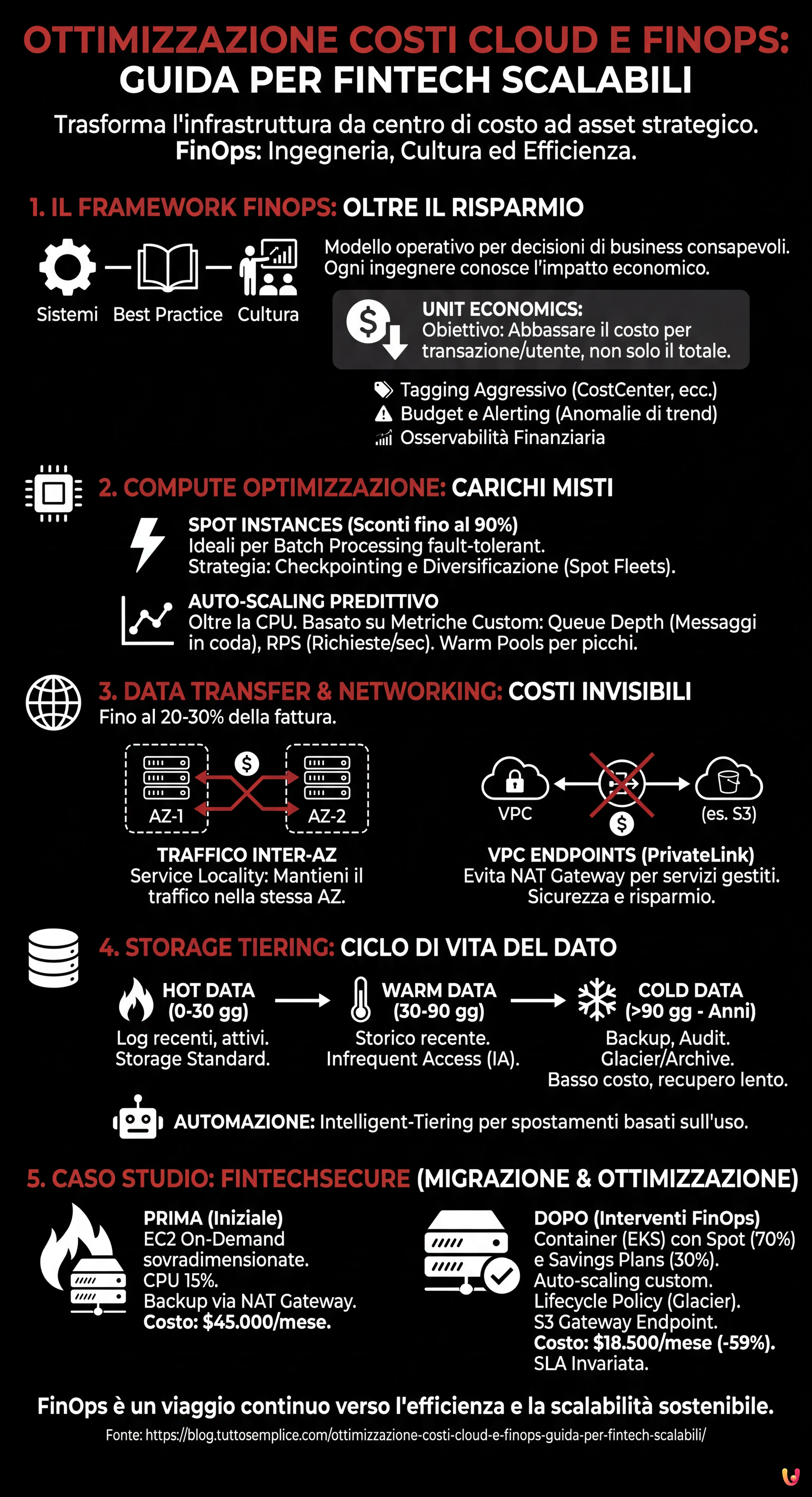
La voce di spesa maggiore è spesso legata alle risorse di calcolo (EC2 su AWS, Compute Engine su GCP). Ecco come ottimizzare in scenari ad alto carico.
Uso Strategico delle Spot Instances
Le Spot Instances (o Preemptible VMs su GCP) offrono sconti fino al 90%, ma possono essere terminate dal provider con poco preavviso. In ambito Fintech, l’uso delle Spot è spesso temuto per via della criticità dei dati, ma è una paura infondata se gestita architettonicamente.
Scenario Applicativo: Batch Processing Notturno.
Consideriamo il calcolo degli interessi sui mutui o la generazione di reportistica normativa che avviene ogni notte. Questo è un carico di lavoro fault-tolerant.
- Strategia: Utilizzare flotte di istanze Spot per i worker node che processano i dati, mantenendo le istanze On-Demand solo per l’orchestrazione (es. il master node di un cluster Kubernetes o EMR).
- Implementazione: Configurare l’applicazione per gestire il “checkpointing”. Se un’istanza Spot viene terminata, il job deve riprendere dall’ultimo checkpoint salvato su un database o su S3/GCS, senza perdita di dati.
- Diversificazione: Non puntare su un solo tipo di istanza. Utilizzare Spot Fleets che richiedono diverse famiglie di istanze (es. m5.large, c5.large, r5.large) per minimizzare il rischio di indisponibilità simultanea.
Auto-scaling Basato su Metriche Custom
L’auto-scaling basato sulla CPU è obsoleto per applicazioni moderne. Spesso, una CPU al 40% nasconde una latenza inaccettabile per l’utente finale.
Per una piattaforma Fintech scalabile, le policy di scaling devono essere aggressive e predittive:
- Metriche di Coda (Queue Depth): Se utilizzate Kafka o SQS/PubSub, scalate in base al numero di messaggi in coda o alla consumer lag. È inutile aggiungere server se la coda è vuota, ma è vitale aggiungerli istantaneamente se la coda supera i 1000 messaggi, indipendentemente dalla CPU.
- Richieste per Secondo (RPS): Per le API Gateway, scalate in base al throughput delle richieste.
- Warm Pools: Mantenere un pool di istanze pre-inizializzate (in stato stopped o hibernate) per ridurre i tempi di avvio durante i picchi di traffico di mercato (es. apertura borsa).
3. Data Transfer e Networking: I Costi Invisibili

Molte aziende si concentrano sul calcolo e ignorano il costo del movimento dati, che può rappresentare il 20-30% della fattura in architetture a microservizi.
Ottimizzazione del Traffico Inter-AZ e Inter-Region
In un’architettura ad alta disponibilità, i dati viaggiano tra diverse Availability Zones (AZ). AWS e GCP addebitano questo traffico.
- Service Locality: Cercate di mantenere il traffico all’interno della stessa AZ quando possibile. Ad esempio, assicuratevi che il microservizio A nella AZ-1 chiami preferibilmente l’istanza del microservizio B nella AZ-1.
- VPC Endpoints (PrivateLink): Evitate di passare per il NAT Gateway per raggiungere servizi come S3 o DynamoDB. L’uso di VPC Endpoints mantiene il traffico sulla rete privata del provider, riducendo i costi di processamento dati del NAT Gateway (che sono significativi per alti volumi) e migliorando la sicurezza.
4. Storage Tiering: Gestione del Ciclo di Vita del Dato Finanziario
Le normative finanziarie (GDPR, PCI-DSS, MiFID II) impongono la conservazione dei dati per anni. Tenere tutto su storage ad alte prestazioni (es. S3 Standard) è uno spreco enorme.
Intelligent Tiering e Lifecycle Policies
L’ottimizzazione costi cloud passa per l’automazione del ciclo di vita del dato:
- Hot Data (0-30 giorni): Log transazionali recenti, dati attivi. Storage Standard.
- Warm Data (30-90 giorni): Storico recente per customer service. Infrequent Access (IA).
- Cold Data (90 giorni – 10 anni): Backup storici, log di audit. Utilizzare classi come S3 Glacier Deep Archive o GCP Archive. Il costo è una frazione dello standard, ma il tempo di recupero è di ore (accettabile per un audit).
- Automazione: Utilizzare S3 Intelligent-Tiering per spostare automaticamente i dati tra i tier in base ai pattern di accesso reali, senza dover scrivere script complessi.
5. Caso Studio: Ottimizzazione Infrastruttura “FinTechSecure”
Analizziamo un caso teorico basato su scenari reali di migrazione e ottimizzazione.
Situazione Iniziale:
La startup “FinTechSecure” gestisce pagamenti P2P. L’infrastruttura è su AWS, interamente basata su istanze EC2 On-Demand sovradimensionate per gestire i picchi del Black Friday, con database RDS Multi-AZ. Costo mensile: $45.000.
Analisi FinOps:
1. Le istanze EC2 hanno una media di utilizzo CPU del 15%.
2. I log di accesso vengono conservati su S3 Standard indefinitamente.
3. Il traffico dati attraverso il NAT Gateway è altissimo a causa dei backup verso S3.
Interventi Eseguiti:
- Compute: Migrazione dei carichi stateless su container (EKS) utilizzando Spot Instances per il 70% dei nodi e Savings Plans per il restante 30% (nodi base). Implementazione di auto-scaling basato su metriche custom (numero transazioni in coda).
- Storage: Attivazione di Lifecycle Policy per spostare i log su Glacier dopo 30 giorni e cancellarli dopo 7 anni (compliance).
- Networking: Implementazione di S3 Gateway Endpoint per eliminare i costi di NAT Gateway per il traffico verso lo storage.
Risultato Finale:
Il costo mensile è sceso a $18.500 (-59%), mantenendo la stessa SLA di disponibilità (99.99%) e migliorando la velocità di scaling durante i picchi imprevisti.
In Breve (TL;DR)
L’approccio FinOps trasforma l’infrastruttura cloud da centro di costo a risorsa strategica, focalizzandosi sulla sostenibilità economica delle singole transazioni.
L’utilizzo di istanze Spot e l’auto-scaling basato su metriche personalizzate garantiscono prestazioni elevate riducendo drasticamente le spese di calcolo.
Una gestione rigorosa del traffico dati e dei tag permette di identificare i costi invisibili e ottimizzare la marginalità aziendale.
Conclusioni

L’ottimizzazione costi cloud in ambito Fintech non è un’attività una tantum, ma un processo continuo. Richiede di bilanciare tre variabili: costo, velocità e qualità (ridondanza/sicurezza). Strumenti come le Spot Instances, le policy di Lifecycle e un monitoraggio granulare permettono di costruire infrastrutture resilienti che scalano economicamente insieme al business. Per l’imprenditore tecnico, padroneggiare il FinOps significa liberare risorse finanziarie da reinvestire in innovazione e sviluppo prodotto.
Domande frequenti

Il FinOps è un modello operativo culturale che unisce ingegneria, finanza e business per ottimizzare la spesa cloud. Nelle aziende Fintech, questo approccio è cruciale perché trasforma l infrastruttura da semplice centro di costo a asset strategico, permettendo di calcolare l impatto economico di ogni scelta tecnica (Unit Economics) e garantendo che la scalabilità tecnologica sia sostenibile finanziariamente anche durante picchi di mercato ad alto carico.
Sebbene le Spot Instances possano essere terminate con poco preavviso, possono essere utilizzate in sicurezza in ambito finanziario per carichi di lavoro fault-tolerant, come il calcolo notturno degli interessi o la reportistica. La strategia corretta prevede l implementazione del checkpointing per salvare i progressi, l uso di flotte miste di istanze per diversificare il rischio e il mantenimento di nodi On-Demand per l orchestrazione del cluster.
L auto-scaling basato sulla sola percentuale di CPU è spesso obsoleto per le moderne piattaforme Fintech. È preferibile adottare strategie aggressive basate su metriche custom come la profondità delle code (Queue Depth) dei sistemi di messaggistica o il numero di richieste per secondo (RPS). Inoltre, l utilizzo di Warm Pools con istanze pre-inizializzate aiuta a gestire latenze zero durante l apertura dei mercati o eventi di traffico improvviso.
I costi di networking possono rappresentare fino al 30% della fattura cloud. Per ridurli, è necessario ottimizzare la Service Locality mantenendo il traffico tra microservizi all interno della stessa Availability Zone. Inoltre, è fondamentale utilizzare VPC Endpoints (PrivateLink) per connettersi ai servizi gestiti come lo storage, evitando così i costosi oneri di processamento dati associati all uso dei NAT Gateway pubblici.
Per rispettare normative come GDPR o PCI-DSS senza sprecare budget, è essenziale implementare il tiering intelligente dello storage. I dati attivi (Hot) rimangono su storage standard, mentre i log storici e i backup (Cold) vengono spostati automaticamente tramite Lifecycle Policies su classi di archiviazione profonda come Glacier o Archive, che hanno costi estremamente ridotti ma tempi di recupero più lunghi, ideali per audit rari.
Hai ancora dubbi su Ottimizzazione Costi Cloud e FinOps: Guida per Fintech Scalabili?
Digita qui la tua domanda specifica per trovare subito la risposta ufficiale di Google.
Fonti e Approfondimenti




Hai trovato utile questo articolo? C’è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.