
Immaginate di aver appena confidato un segreto a un amico fidato, per poi pentirvene immediatamente e chiedergli di dimenticarlo. Per un essere umano, l’atto di dimenticare è spesso involontario e naturale; paradossalmente, sforzarsi di rimuovere un ricordo richiede un impegno cognitivo notevole. Nel mondo digitale classico, la situazione è opposta: cancellare un file da un hard disk è un’operazione banale, un semplice comando binario. Ma quando entriamo nel dominio di una Rete Neurale, l’entità che costituisce il cervello pulsante delle moderne intelligenze artificiali, le regole del gioco cambiano drasticamente. Qui, l’oblio non è una funzione di default, ma una delle sfide matematiche e ingegneristiche più complesse che il progresso tecnologico si trova ad affrontare oggi, in questo febbraio del 2026.
La curiosità che esploreremo oggi non riguarda come le macchine imparano, un tema ormai ampiamente dibattuto, ma perché sia così incredibilmente difficile farle disimparare. Perché non possiamo semplicemente premere “cancella” su un concetto appreso da un LLM (Large Language Model) come ChatGPT o dai suoi successori? La risposta risiede nella natura stessa dell’architettura che sostiene questi sistemi, molto più simile a un cocktail mescolato che a un archivio ordinato.
Non è un database, è un ologramma cognitivo
Per comprendere il problema, dobbiamo prima smantellare un mito comune: l’Intelligenza Artificiale non memorizza le informazioni come fa un database tradizionale. In un database SQL, se volete rimuovere il numero di telefono di un utente, cercate la riga corrispondente e la eliminate. Il dato sparisce senza lasciare traccia e senza influenzare gli altri dati.
Nel Deep Learning, invece, l’informazione non risiede in un singolo luogo. Durante la fase di addestramento, quando l’algoritmo elabora terabyte di testo o immagini, scompone queste informazioni e le diffonde attraverso miliardi di parametri. È quello che gli esperti chiamano “rappresentazione distribuita”. Immaginate di versare una goccia di inchiostro blu in una vasca d’acqua e mescolare: l’inchiostro non è più in un punto specifico, ma è ovunque, ha cambiato impercettibilmente il colore dell’intera massa d’acqua. Chiedere a una rete neurale di dimenticare uno specifico dato di training è come chiedere di estrarre quella specifica goccia d’inchiostro dalla vasca senza alterare l’acqua o le altre gocce di colore (altri dati) che vi sono state versate.
Il peso della memoria: come funzionano i Pesi Sinaptici
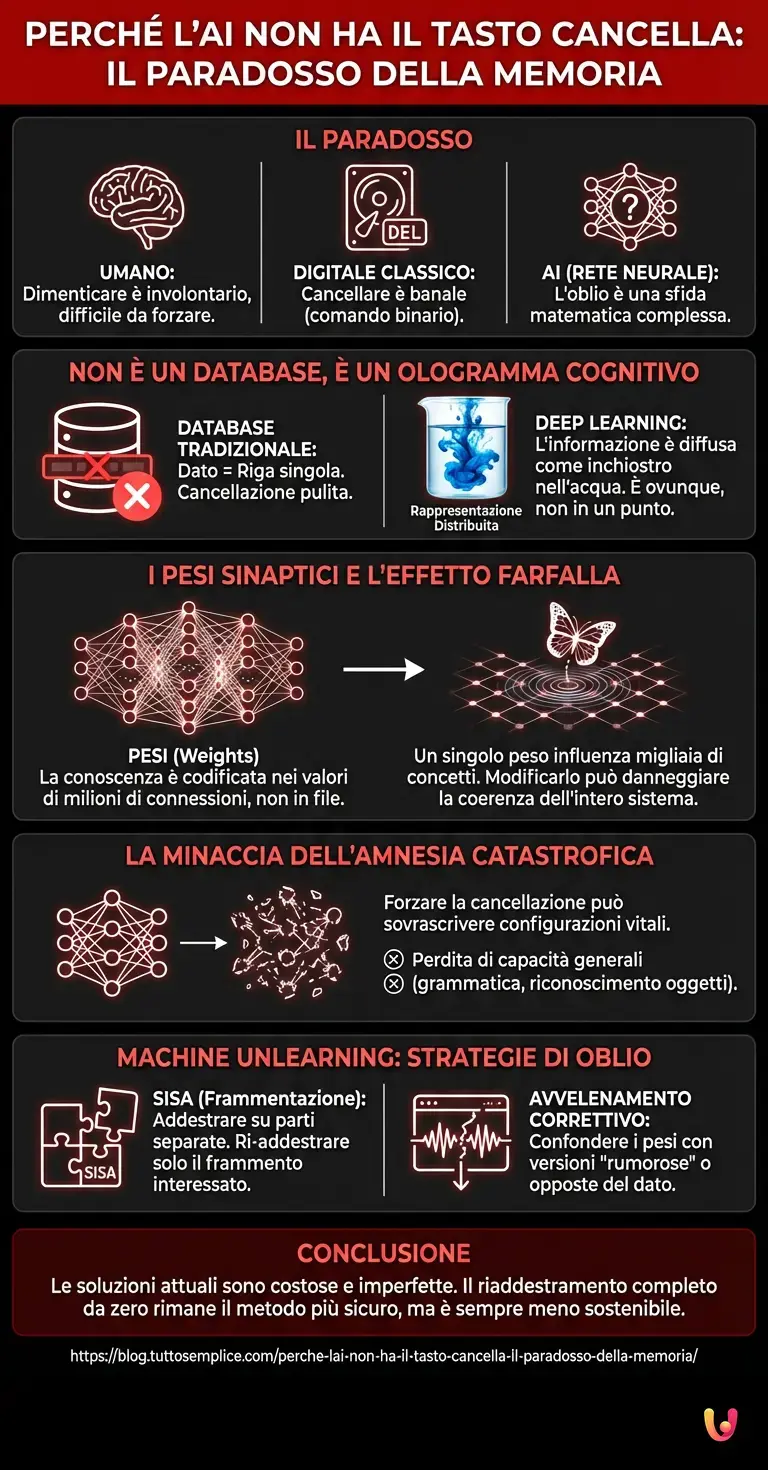
Tecnicamente, la conoscenza in un modello di Machine Learning è codificata nei “pesi” (weights) delle connessioni tra i neuroni artificiali. Ogni volta che il modello impara che “il cielo è blu”, non scrive questa frase su un disco. Invece, aggiusta leggermente i valori numerici di milioni di connessioni affinché, data la parola “cielo”, la probabilità che la parola successiva sia “blu” aumenti.
Questo processo di ottimizzazione crea una struttura interconnessa estremamente densa. Un singolo peso nella rete non è responsabile di un solo ricordo, ma contribuisce alla formazione di migliaia di concetti diversi. Se provassimo a modificare manualmente quei pesi per cancellare un’informazione specifica (ad esempio, un dato coperto da copyright o un’informazione privata sensibile), rischieremmo di danneggiare la capacità del modello di comprendere concetti correlati o, peggio, di distruggere la sua coerenza linguistica. È il cosiddetto effetto farfalla dell’architettura neurale: toccare un singolo nodo può causare vibrazioni impreviste in tutto il sistema.
La minaccia dell’Amnesia Catastrofica

Qui entra in gioco uno dei fenomeni più affascinanti e temuti dagli ingegneri dell’AI: il Catastrophic Forgetting (l’amnesia catastrofica). Quando si tenta di forzare una rete neurale a modificare la sua struttura per rimuovere una conoscenza pregressa o per apprenderne una nuova in modo troppo aggressivo, la rete tende a sovrascrivere drasticamente le configurazioni precedenti.
Il risultato? Il modello potrebbe dimenticare con successo il dato richiesto, ma nel processo potrebbe perdere la capacità di coniugare i verbi, riconoscere la struttura di una frase o distinguere un gatto da un cane. L’equilibrio raggiunto durante mesi di costoso addestramento è fragile. Mantenere le prestazioni generali (i benchmark di qualità) mentre si esegue una chirurgia di precisione sulla memoria del modello è la frontiera attuale della ricerca.
Machine Unlearning: l’arte di disimparare
Di fronte a queste difficoltà, e spinti dalle normative sulla privacy sempre più stringenti (come il diritto all’oblio digitale), i ricercatori hanno sviluppato un nuovo campo di studi chiamato Machine Unlearning. Non potendo semplicemente “cancellare”, si utilizzano strategie alternative:
- SISA (Sharded, Isolated, Sliced, Aggregated): Invece di addestrare un modello monolitico gigante, si addestra l’AI su frammenti di dati separati. Se un dato deve essere cancellato, basta ri-addestrare solo il piccolo frammento che lo conteneva, risparmiando tempo ed energia computazionale.
- Algoritmi di “avvelenamento” correttivo: Si sottopone il modello a un ulteriore addestramento con versioni “rumorose” o opposte del dato da dimenticare, cercando di confondere i pesi specifici associati a quel ricordo fino a renderlo inaccessibile, neutralizzando l’informazione senza distruggere la rete.
Tuttavia, nessuna di queste soluzioni è perfetta. L’automazione del processo di oblio è ancora imperfetta e costosa in termini di calcolo. Spesso, il modo più sicuro per garantire che un’AI abbia dimenticato un set di dati è ancora quello più drastico: resettare tutto e riaddestrare il modello da zero, escludendo quei dati. Una soluzione che, con la crescita esponenziale delle dimensioni dei modelli, diventa sempre meno sostenibile ecologicamente ed economicamente.
In Breve (TL;DR)
Cancellare ricordi dall’AI è complesso perché le informazioni sono diffuse come inchiostro nell’acqua, non archiviate in semplici database.
Modificare i pesi sinaptici per rimuovere un dato specifico può causare un’amnesia catastrofica, danneggiando le capacità generali del modello.
La ricerca attuale punta sul Machine Unlearning per garantire il diritto all’oblio digitale senza compromettere la coerenza dell’intelligenza artificiale.
Conclusioni

La difficoltà dell’Intelligenza Artificiale nel dimenticare ci svela una verità profonda sulla natura di queste tecnologie: non sono archivi passivi, ma sistemi dinamici che “digeriscono” l’esperienza. Mentre il progresso tecnologico ci spinge verso modelli sempre più capaci di apprendere e generare, la vera maturità dell’AI si misurerà forse non sulla sua capacità di ricordare tutto, ma sulla sua abilità di dimenticare selettivamente ciò che non deve più esistere. Fino ad allora, ogni dato che forniamo a un algoritmo diventa parte indissolubile della sua essenza matematica, un tatuaggio digitale che è molto difficile rimuovere senza lasciare cicatrici.
Domande frequenti

Nelle reti neurali l’informazione non è archiviata in un singolo file come nei database classici, ma è diffusa attraverso miliardi di parametri chiamati pesi sinaptici. Questo fenomeno, noto come rappresentazione distribuita, rende la cancellazione simile al tentativo di estrarre una specifica goccia d’inchiostro da una vasca d’acqua già mescolata: rimuovere un singolo elemento senza alterare il resto del sistema è una sfida matematica estremamente complessa che rischia di compromettere la coerenza dell’intero modello.
Il Machine Unlearning è un campo di ricerca emergente che sviluppa tecniche per permettere agli algoritmi di dimenticare informazioni specifiche senza dover essere riaddestrati da zero. Tra le strategie utilizzate vi sono l’approccio SISA, che frammenta l’addestramento in parti isolabili, e gli algoritmi di avvelenamento correttivo, che mirano a confondere i pesi associati a un ricordo. Queste soluzioni nascono per rispondere alle esigenze di privacy e al diritto all’oblio digitale, sebbene siano ancora processi costosi e in fase di perfezionamento.
L’Amnesia Catastrofica, o Catastrophic Forgetting, è un fenomeno rischioso che si verifica quando si tenta di modificare aggressivamente una rete neurale per cancellare una conoscenza pregressa. A causa della forte interconnessione dei pesi sinaptici, l’alterazione mirata può causare un effetto a catena che degrada le prestazioni generali del modello. In pratica, l’AI potrebbe dimenticare il dato richiesto ma perdere contemporaneamente capacità fondamentali come la coniugazione dei verbi o il riconoscimento di oggetti comuni.
A differenza di un archivio ordinato, un modello LLM memorizza la conoscenza attraverso un processo di ottimizzazione dei pesi delle connessioni tra neuroni artificiali. Durante l’addestramento, il sistema non salva frasi o immagini, ma aggiusta valori numerici per prevedere sequenze logiche. Ogni singolo peso contribuisce alla formazione di migliaia di concetti diversi; pertanto, ogni dato fornito diventa parte integrante e indissolubile della struttura matematica del modello, rendendo l’informazione un ologramma cognitivo piuttosto che un semplice record di database.
Nonostante lo sviluppo di tecniche di cancellazione selettiva, il metodo più sicuro per garantire la totale rimozione di un set di dati rimane il riaddestramento completo del modello da zero, escludendo le informazioni indesiderate dal dataset iniziale. Tuttavia, questa soluzione presenta notevoli svantaggi economici ed ecologici, poiché richiede enormi risorse di calcolo e tempo, diventando sempre meno sostenibile con la crescita esponenziale delle dimensioni delle moderne intelligenze artificiali.
Fonti e Approfondimenti

- Wikipedia – Machine unlearning (Disapprendimento automatico)
- Garante per la protezione dei dati personali – Il Diritto all’oblio
- Wikipedia – Interferenza catastrofica (Catastrophic interference)
- NIST – Framework per la gestione del rischio nell’Intelligenza Artificiale
- Unione Europea – Regolamento Generale sulla Protezione dei Dati (GDPR – Art. 17)



Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.