In Breve (TL;DR)
Il prompt engineering finanziario converte documenti non strutturati in dati JSON validati per ottimizzare il credit scoring moderno.
Strategie tecniche come Chain-of-Thought e Few-Shot Prompting garantiscono estrazioni precise mitigando i rischi di allucinazioni numeriche.
L’integrazione di pipeline AI con validazione automatica riduce i tempi operativi e migliora l’affidabilità dei processi bancari.
Il diavolo è nei dettagli. 👇 Continua a leggere per scoprire i passaggi critici e i consigli pratici per non sbagliare.
Nel panorama fintech del 2026, la capacità di trasformare documenti non strutturati in dati azionabili è diventata il discriminante principale tra un processo di credit scoring efficiente e uno obsoleto. Il prompt engineering finanziario non è più una semplice skill accessoria, ma una componente critica dell’architettura software bancaria. Questa guida tecnica esplora come progettare pipeline AI robuste per l’estrazione di dati da buste paga, bilanci XBRL/PDF ed estratti conto, minimizzando i rischi operativi.

Il Problema dei Dati Non Strutturati nel Credit Scoring
Nonostante l’evoluzione degli standard digitali, una porzione significativa della documentazione necessaria per l’istruttoria di un fido (specialmente per PMI e privati) arriva ancora in formati non strutturati: PDF scansionati, immagini o file di testo disordinati. L’obiettivo è convertire questo caos in un oggetto JSON validato che possa alimentare direttamente gli algoritmi di valutazione del rischio.
Le sfide principali includono:
- Ambiguità Semantica: Distinguere tra “Reddito Lordo” e “Imponibile Fiscale” in buste paga con layout proprietari.
- Allucinazioni Numeriche: La tendenza degli LLM a inventare cifre o sbagliare i calcoli se non correttamente istruiti.
- Rumore da OCR: Errori di lettura (es. scambiare uno ‘0’ per una ‘O’ o un ‘8’ per una ‘B’).
Architettura della Pipeline di Estrazione
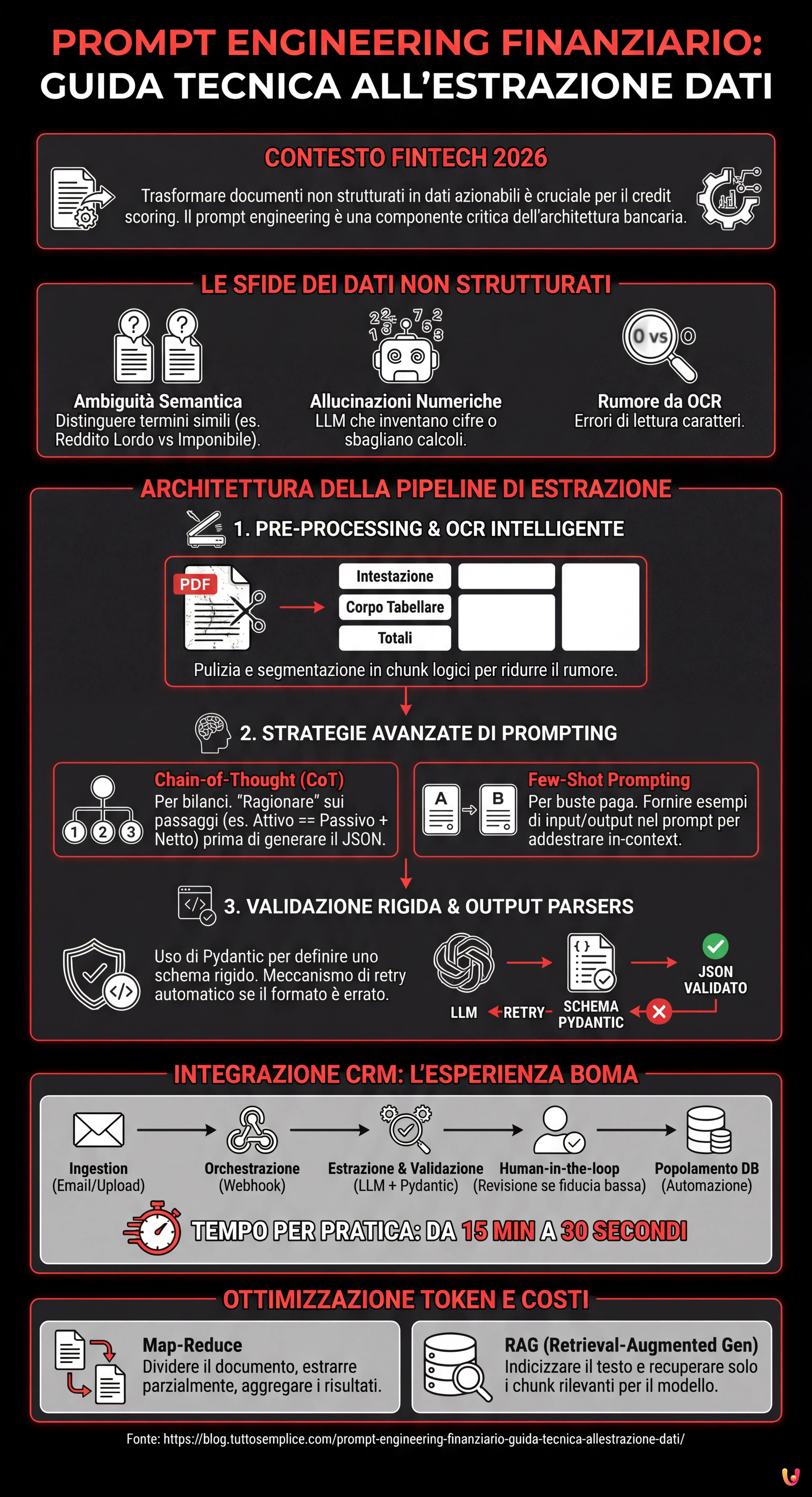
Per costruire un sistema affidabile, non basta inviare un PDF a un modello come GPT-4o o Claude. È necessaria un’orchestrazione complessa, gestita tipicamente tramite framework come LangChain o LlamaIndex.
1. Pre-processing e OCR Intelligente
Prima di applicare qualsiasi tecnica di prompt engineering finanziario, il documento deve essere “pulito”. L’uso di OCR avanzati è mandatorio. In questa fase, è utile segmentare il documento in chunk logici (es. “Intestazione”, “Corpo Tabellare”, “Totali”) per evitare di saturare la context window del modello con rumore inutile.
2. Strategie Avanzate di Prompting
Qui risiede il cuore della tecnica. Un prompt generico come “Estrai i dati” fallirà nel 90% dei casi complessi. Ecco le metodologie vincenti:
Chain-of-Thought (CoT) per la Validazione Logica
Per i bilanci aziendali, è fondamentale che il modello “ragioni” prima di rispondere. Utilizzando il CoT, forziamo l’LLM a esplicitare i passaggi intermedi.
SYSTEM PROMPT:
Sei un analista finanziario esperto. Il tuo compito è estrarre i dati di bilancio.
USER PROMPT:
Analizza il testo fornito. Prima di generare il JSON finale, esegui questi passaggi:
1. Identifica il Totale Attivo e il Totale Passivo.
2. Verifica se Attivo == Passivo + Patrimonio Netto.
3. Se i conti non tornano, segnala l'incongruenza nel campo 'warning'.
4. Solo alla fine genera l'output JSON.Few-Shot Prompting per Buste Paga Eterogenee
Le buste paga variano enormemente tra diversi datori di lavoro. Il Few-Shot Prompting consiste nel fornire al modello esempi di input (testo grezzo) e output desiderato (JSON) all’interno del prompt stesso. Questo “addestra” il modello in-context a riconoscere pattern specifici senza necessità di fine-tuning.
ESEMPIO 1:
Input: "Totale competenze: 2.500,00 euro. Netto in busta: 1.850,00."
Output: {"lordo": 2500.00, "netto": 1850.00}
ESEMPIO 2:
Input: "Lordo mensile: € 3.000. Trattenute totali: € 800. Netto a pagare: € 2.200."
Output: {"lordo": 3000.00, "netto": 2200.00}
TASK:
Input: [Nuovo Testo Busta Paga]...Mitigazione delle Allucinazioni e Validazione

In ambito finanziario, un’allucinazione (inventare un numero) è inaccettabile. Per mitigare questo rischio, implementiamo una validazione rigida post-processing.
Output Parsers e Pydantic
Utilizzando librerie come Pydantic in Python, possiamo definire uno schema rigido che il modello deve rispettare. Se l’LLM genera un campo “data” in un formato errato o una stringa al posto di un float, il validatore solleva un’eccezione e, tramite un meccanismo di retry, chiede al modello di correggersi.
Integrazione CRM: L’Esperienza BOMA
L’applicazione pratica di queste tecniche trova la sua massima espressione nell’integrazione con sistemi proprietari. Nel contesto del progetto BOMA (Back Office Management Automation), l’integrazione della pipeline AI ha seguito questi step:
- Ingestion: Il CRM riceve il documento via email o upload.
- Orchestrazione: Un webhook attiva la pipeline LangChain.
- Estrazione & Validazione: L’LLM estrae i dati e Pydantic li valida.
- Human-in-the-loop: Se il confidence score è basso, il sistema crea un task nel CRM per una revisione manuale, evidenziando i campi sospetti.
- Popolamento: I dati validati popolano automaticamente i campi del DB, riducendo il tempo di data entry da 15 minuti a 30 secondi per pratica.
Ottimizzazione dei Token e dei Costi
Gestire la token window è essenziale per mantenere i costi delle API sostenibili, specialmente con bilanci di centinaia di pagine.
- Map-Reduce: Invece di passare l’intero documento in una volta, si divide il testo in sezioni, si estraggono i dati parziali e si chiede a un secondo prompt di aggregarli.
- RAG (Retrieval-Augmented Generation): Per documenti molto estesi, si indicizza il testo in un database vettoriale e si recuperano solo i chunk rilevanti (es. solo le pagine relative al “Conto Economico”) da passare al modello.
Conclusioni

Il prompt engineering finanziario è una disciplina che richiede rigore. Non si tratta solo di saper “parlare” con l’AI, ma di costruire un’infrastruttura di controllo attorno ad essa. Attraverso l’uso combinato di Chain-of-Thought, Few-Shot Prompting e validatori di schema, è possibile automatizzare l’analisi del rischio di credito con un livello di precisione che nel 2026 compete con, e spesso supera, l’accuratezza umana.
Domande frequenti

Il prompt engineering finanziario è una disciplina tecnica focalizzata sulla progettazione di istruzioni precise per modelli di intelligenza artificiale, finalizzata a trasformare documenti non strutturati come buste paga e bilanci in dati strutturati. Nel settore fintech, questa competenza è diventata cruciale per automatizzare il credit scoring, permettendo di convertire formati caotici come PDF e scansioni in oggetti JSON validati, riducendo drasticamente i tempi di lavorazione e i rischi operativi.
Per prevenire che i modelli linguistici inventino cifre o commettano errori di calcolo, è necessario implementare una validazione rigida post-processing utilizzando librerie come Pydantic, che impongono uno schema fisso all output. Inoltre, l uso di strategie di prompting come il Chain-of-Thought obbliga il modello a esplicitare i passaggi logici intermedi, come verificare che il totale attivo corrisponda al passivo più il patrimonio netto, prima di generare il risultato finale.
Le tecniche variano in base al tipo di documento. Per i bilanci aziendali, che richiedono coerenza logica, è preferibile il Chain-of-Thought che guida il ragionamento del modello. Per documenti eterogenei come le buste paga, risulta più efficace il Few-Shot Prompting, che consiste nel fornire al modello esempi concreti di input e output desiderato all interno del prompt stesso, aiutandolo a riconoscere pattern specifici senza necessità di un nuovo addestramento.
Per documenti estesi che rischiano di saturare la memoria del modello o aumentare i costi, si utilizzano tecniche di ottimizzazione dei token. L approccio Map-Reduce divide il documento in sezioni più piccole per estrazioni parziali poi aggregate. Alternativamente, la tecnica RAG (Retrieval-Augmented Generation) permette di recuperare e analizzare solo i frammenti di testo realmente pertinenti, come le specifiche tabelle di un bilancio, ignorando le parti non necessarie.
L OCR intelligente rappresenta il primo passo fondamentale per pulire il documento prima dell analisi AI. Poiché molti documenti arrivano come scansioni o immagini, un OCR avanzato è necessario per convertire questi file in testo leggibile e segmentarli in blocchi logici. Questo riduce il rumore causato da errori di lettura e prepara il terreno per un prompt engineering efficace, evitando che il modello venga confuso da dati disordinati.
Fonti e Approfondimenti

- Banca d’Italia: Fintech e innovazione digitale nel sistema finanziario
- European Banking Authority (EBA): Report su Big Data e Advanced Analytics nel settore bancario
- Wikipedia: Definizione e standard XBRL (eXtensible Business Reporting Language)
- Wikipedia: Approfondimento sul Prompt Engineering e i modelli linguistici
- AgID: L’Intelligenza Artificiale nella Pubblica Amministrazione e standard dati

Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.