Pe Scurt (TL;DR)
Depășirea naturii probabilistice a modelelor generative este esențială pentru integrarea fiabilă a inteligenței artificiale în procesele decizionale critice.
O abordare hibridă combină flexibilitatea semantică a LLM-urilor cu rigiditatea logică a Expresiilor Regulate pentru validarea datelor.
Utilizarea Chain-of-Thought și a output-urilor JSON structurate garantează precizia și conformitatea în extragerea automată a informațiilor financiare complexe.
Diavolul se ascunde în detalii. 👇 Continuă să citești pentru a descoperi pașii critici și sfaturile practice pentru a nu greși.
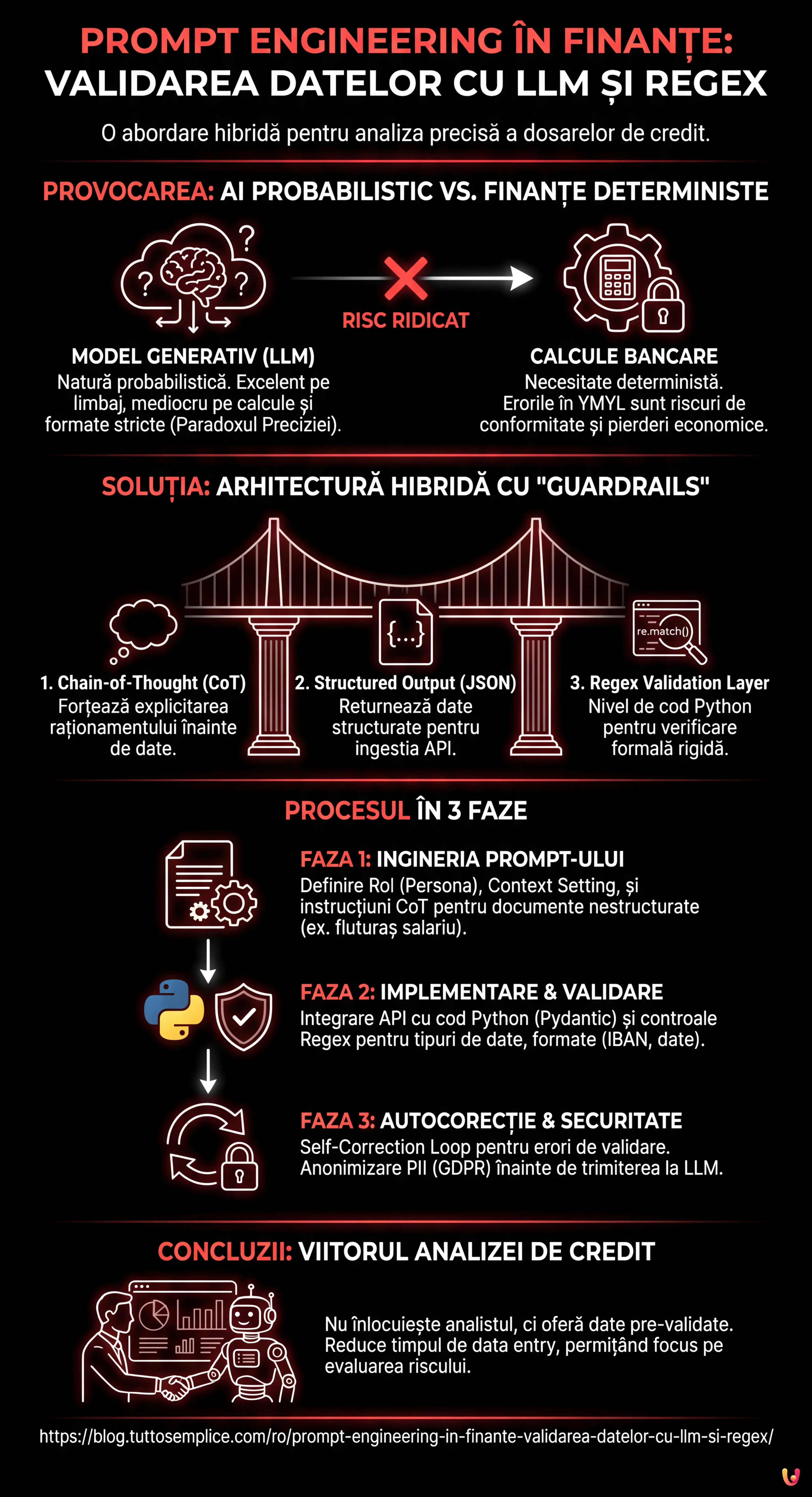
În peisajul fintech din 2026, adoptarea Inteligenței Artificiale Generative nu mai este o noutate, ci un standard operațional. Cu toate acestea, adevărata provocare nu constă în implementarea unui chatbot, ci în integrarea fiabilă a modelelor LLM (Large Language Models) în procesele decizionale critice. În acest ghid tehnic, vom explora prompt engineering în finanțe cu o abordare inginerească, concentrându-ne pe un caz de utilizare specific și cu risc ridicat: extragerea și validarea datelor pentru analiza dosarelor de credit ipotecar.
Vom aborda problema principală a AI în domeniul financiar: natura probabilistică a modelelor generative versus necesitatea deterministă a calculelor bancare. Așa cum vom vedea, soluția constă într-o arhitectură hibridă care combină flexibilitatea semantică a modelelor precum GPT-4 (sau succesorii săi) cu rigiditatea logică a Expresiilor Regulate (Regex) și a controalelor programatice.

Paradoxul Preciziei: De ce LLM-urile greșesc calculele
Oricine a lucrat cu AI generativă știe că modelele sunt excelente în înțelegerea limbajului natural, dar mediocre în aritmetica complexă sau în respectarea riguroasă a formatelor de ieșire non-standard. Într-un context YMYL (Your Money Your Life), o eroare în calculul gradului de îndatorare (raportul rată/venit) nu este o halucinație acceptabilă; este un risc de conformitate și o potențială pierdere economică.
Conceptul de prompt engineering în finanțe nu se referă doar la scrierea unor fraze elegante pentru model. Este vorba despre proiectarea unui sistem de Guardrails (bariere de siguranță) care să constrângă modelul să opereze în limite definite. Abordarea pe care o vom utiliza se bazează pe trei piloni:
- Chain-of-Thought (CoT): Forțarea modelului să expliciteze raționamentul înainte de a furniza data finală.
- Structured Output (JSON): Obligarea modelului să returneze date structurate pentru ingestia via API.
- Regex Validation Layer: Un nivel de cod Python care verifică dacă output-ul LLM respectă modelele formale (ex. IBAN, Cod Fiscal, formate de dată).
Faza 1: Ingineria Prompt-ului pentru Documente Nestructurate
Să ne imaginăm că trebuie să extragem date dintr-un fluturaș de salariu sau dintr-o evaluare imobiliară scanată (OCR). Textul este murdar, dezordonat și plin de abrevieri. Un prompt generic ar eșua. Trebuie să construim un prompt structurat.
Tehnica “Persona” și “Context Setting”
Prompt-ul trebuie să definească clar rolul modelului. Nu cerem un rezumat, cerem o extragere de date ETL (Extract, Transform, Load).
SYSTEM ROLE:
Ești un Senior Credit Analyst specializat în analiza dosarelor de credit ipotecar. Sarcina ta este să extragi date financiare critice din text nestructurat provenit din documentație OCR.
OBIECTIV:
Identificarea și normalizarea Venitului Net Lunar și a cheltuielilor recurente pentru calculul gradului de îndatorare.
CONSTRÂNGERI:
1. Nu inventa date. Dacă o dată lipsește, returnează "null".
2. Ignoră bonusurile unice, concentrează-te pe retribuția ordinară.
3. Output-ul TREBUIE să fie exclusiv în format JSON valid.Implementarea Chain-of-Thought (CoT)
Pentru a crește acuratețea, utilizăm tehnica Chain-of-Thought. Cerem modelului să “gândească” într-un câmp separat al JSON-ului înainte de a extrage valoarea. Acest lucru reduce drastic halucinațiile privind numerele.
Exemplu de structură a prompt-ului utilizator:
INPUT TEXT:
[Introduceți aici textul OCR al fluturașului de salariu...]
INSTRUCȚIUNI:
Analizează textul pas cu pas.
1. Identifică toate intrările pozitive (salariu de bază, sporuri permanente).
2. Identifică reținerile fiscale și contribuțiile sociale.
3. Exclude decontările de cheltuieli sau bonusurile nerecurente.
4. Calculează netul dacă nu este indicat explicit, altfel extrage "Netul lunii".
OUTPUT FORMAT (JSON):
{
"reasoning": "Șir de text unde explici raționamentul logic urmat pentru identificarea netului.",
"net_income_value": Float sau null,
"currency": "EUR",
"document_date": "YYYY-MM-DD"
}Faza 2: Implementare Python și Validare Hibridă


Conceptul de prompt engineering în finanțe este inutil fără un backend care să îl susțină. Aici intervine abordarea hibridă. Nu ne încredem orbește în JSON-ul generat de LLM. Îl trecem printr-un validator bazat pe Regex și Pydantic.
Cod Python pentru Integrarea API
Mai jos este un exemplu despre cum să structurați apelul API (utilizând biblioteci standard precum openai și pydantic pentru validarea tipurilor) și să integrați controlul Regex.
import openai
import json
import re
from pydantic import BaseModel, ValidationError, validator
from typing import Optional
# Definirea schemei de date așteptate (Guardrail #1)
class FinancialData(BaseModel):
reasoning: str
net_income_value: float
currency: str
document_date: str
# Validator Regex pentru dată (Guardrail #2)
@validator('document_date')
def date_format_check(cls, v):
pattern = r'^d{4}-d{2}-d{2}$'
if not re.match(pattern, v):
raise ValueError('Format dată invalid. Se solicită YYYY-MM-DD')
return v
# Validator logic pentru venit (Guardrail #3)
@validator('net_income_value')
def realistic_income_check(cls, v):
if v 50000: # Praguri de siguranță pentru alertă manuală
raise ValueError('Valoare venit în afara parametrilor standard (Anomaly Detection)')
return v
def extract_financial_data(ocr_text):
prompt = f"""
Analizează următorul text OCR bancar și extrage datele solicitate.
TEXT: {ocr_text}
Returnează DOAR un obiect JSON.
"""
try:
response = openai.ChatCompletion.create(
model="gpt-4-turbo", # Sau model echivalent 2026
messages=[
{"role": "system", "content": "Ești un extractor de date financiare riguros."},
{"role": "user", "content": prompt}
],
temperature=0.0 # Temperatură la 0 pentru determinism maxim
)
raw_content = response.choices[0].message.content
# Parsare și Validare
data_dict = json.loads(raw_content)
validated_data = FinancialData(**data_dict)
return validated_data
except json.JSONDecodeError:
return "Eroare: LLM-ul nu a produs un JSON valid."
except ValidationError as e:
return f"Eroare de Validare Date: {e}"
except Exception as e:
return f"Eroare generică: {e}"
# Exemplu de utilizare
# result = extract_financial_data("Fluturaș salariu luna Ianuarie... Net de plată: 2.450,00 euro...")
Faza 3: Gestionarea Halucinațiilor și Bucla de Corecție
Ce se întâmplă dacă validarea eșuează? Într-un sistem de producție avansat, implementăm un Self-Correction Loop (Buclă de Autocorecție). Dacă Pydantic ridică o excepție (ex. format dată greșit), sistemul poate trimite automat o nouă cerere către LLM incluzând eroarea primită.
Exemplu de Prompt de Corecție Automată:
“Ai generat un JSON cu o eroare. Câmpul ‘document_date’ nu a respectat formatul YYYY-MM-DD. Corectează valoarea și returnează din nou JSON-ul.”
Considerații privind Confidențialitatea și Securitatea (YMYL)
Când se aplică prompt engineering în finanțe, gestionarea datelor PII (Personally Identifiable Information) este critică. Înainte de a trimite orice text OCR către un API public (chiar dacă este enterprise), este o bună practică să se aplice o tehnică de Anonymization Pre-Processing.
Utilizând Regex locale (deci nu AI), se pot masca nume, coduri numerice personale și adrese, înlocuindu-le cu token-uri (ex. [NUME_CLIENT_1]). LLM-ul va analiza structura financiară fără a expune identitatea reală a solicitantului creditului, menținând conformitatea cu GDPR.
Concluzii: Viitorul Analizei Dosarelor de Credit
Integrarea dintre prompt engineering în finanțe, logica de programare tradițională și validarea Regex reprezintă singura cale viabilă pentru a aduce AI în procesele de bază ale băncilor. Nu este vorba despre înlocuirea analistului uman, ci despre furnizarea de date pre-validate și normalizate, reducând timpul de data entry cu 80% și permițându-i să se concentreze pe evaluarea riscului de credit.
Cheia succesului nu este un model mai inteligent, ci o inginerie a prompt-ului mai robustă și un sistem de control mai rigid.
Întrebări frecvente

Prompt engineering-ul este esențial pentru a transforma natura probabilistică a modelelor generative în output-uri deterministe necesare băncilor. Prin utilizarea barierelor de siguranță (guardrails) și a instrucțiunilor structurate, se atenuează riscurile de halucinații și se garantează că extragerea datelor pentru procese critice, cum ar fi analiza dosarelor de credit, respectă standarde riguroase de conformitate și precizie.
Soluția constă într-o abordare hibridă care combină capacitatea semantică a AI cu rigiditatea logică a Expresiilor Regulate (Regex) și a controalelor programatice. În loc să cerem modelului să execute calcule complexe, îl utilizăm pentru a extrage date structurate care sunt ulterior validate și procesate de un nivel de cod Python, asigurând acuratețea necesară în domeniul financiar.
Tehnica Chain-of-Thought îmbunătățește acuratețea extragerii datelor obligând modelul să expliciteze raționamentul logic înainte de a furniza rezultatul final. În cazul documentelor nestructurate precum fluturașii de salariu, această metodă constrânge AI-ul să identifice pas cu pas intrările pozitive și negative, reducând semnificativ erorile de interpretare și falsurile pozitive în valorile numerice.
Pentru a garanta confidențialitatea și conformitatea cu GDPR, este necesar să se aplice o tehnică de anonimizare pre-procesare. Înainte de a trimite datele către API-ul modelului, se utilizează scripturi locale pentru a masca informațiile identificabile (PII) precum nume și coduri fiscale, permițând AI-ului să analizeze contextul financiar fără a expune vreodată identitatea reală a solicitantului.
Self-Correction Loop este un mecanism automatizat care gestionează erorile de output ale modelului. Dacă validatorul (ex. Pydantic) detectează un format JSON greșit sau o dată în afara pragurilor, sistemul retrimite prompt-ul către LLM incluzând eroarea constatată, cerând modelului să corecteze specific acel parametru. Acest ciclu iterativ crește drastic rata de succes în extragerea automată.
Surse și Aprofundare


")

Ați găsit acest articol util? Există un alt subiect pe care ați dori să-l tratez?
Scrieți-l în comentariile de mai jos! Mă inspir direct din sugestiile voastre.