In Breve (TL;DR)
Il paradigma Data Lakehouse modernizza il credit scoring unificando la gestione di dati strutturati e non strutturati in un’unica infrastruttura scalabile.
L’estrazione di valore da fonti eterogenee come documenti e log avviene tramite pipeline NLP avanzate che trasformano informazioni grezze in feature predittive.
L’architettura a strati integrata con Feature Store garantisce la governance del dato e l’allineamento tra addestramento dei modelli e inferenza in tempo reale.
Il diavolo è nei dettagli. 👇 Continua a leggere per scoprire i passaggi critici e i consigli pratici per non sbagliare.
Nel panorama fintech del 2026, la capacità di valutare il rischio di credito non dipende più solo dallo storico dei pagamenti o dal saldo del conto corrente. La frontiera moderna è il data lakehouse credit scoring, un approccio architetturale che supera la dicotomia tra Data Warehouse (ottimi per i dati strutturati) e Data Lake (necessari per i dati non strutturati). Questa guida tecnica esplora come progettare un’infrastruttura capace di ingerire, processare e servire dati eterogenei per alimentare modelli di Machine Learning di nuova generazione.

L’Evoluzione del Credit Scoring: Oltre i Dati Tabellari
Tradizionalmente, il credit scoring si basava su modelli di regressione logistica alimentati da dati rigidamente strutturati provenienti dai Core Banking System. Tuttavia, questo approccio ignora una miniera d’oro di informazioni: i dati non strutturati. Email di supporto, log delle chat, documenti PDF di bilancio e persino metadati di navigazione offrono segnali predittivi cruciali sulla stabilità finanziaria di un cliente o sulla sua propensione all’abbandono (churn).
Il paradigma del Data Lakehouse emerge come la soluzione definitiva. Unendo la flessibilità dello storage a basso costo (come Amazon S3 o Google Cloud Storage) con le capacità transazionali e di gestione dei metadati tipiche dei Warehouse (tramite tecnologie come Delta Lake, Apache Iceberg o Apache Hudi), è possibile creare una Single Source of Truth per il credit scoring avanzato.
Architettura di Riferimento per il Credit Scoring 2.0
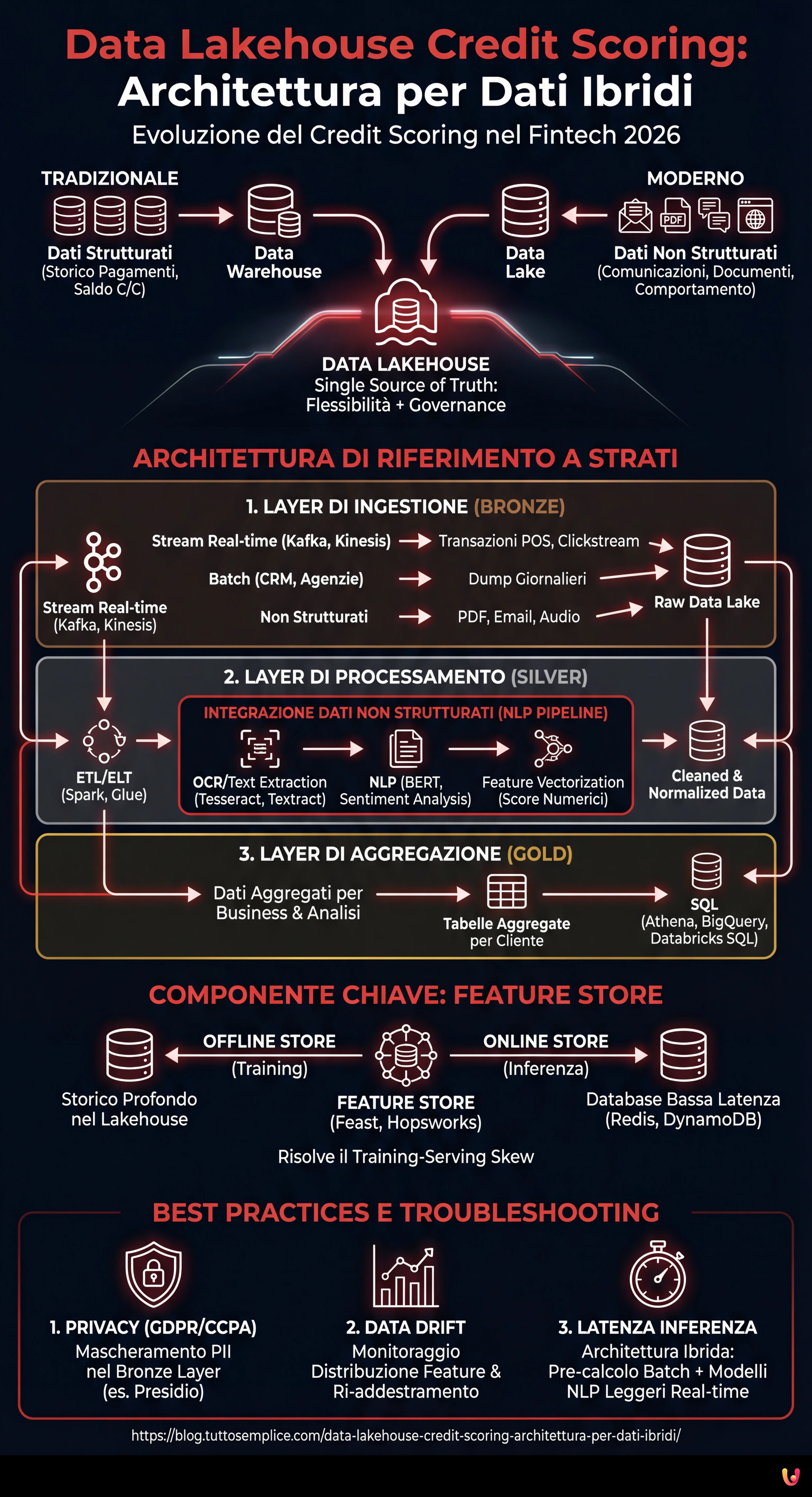
Per costruire un sistema efficace, dobbiamo delineare un’architettura a strati che garantisca scalabilità e governance. Ecco i componenti fondamentali:
1. Layer di Ingestione (Bronze Layer)
I dati atterrano nel Lakehouse nel loro formato nativo. In uno scenario di credit scoring, avremo:
- Stream in tempo reale: Transazioni POS, clickstream dell’app mobile (via Apache Kafka o Amazon Kinesis).
- Batch: Dump giornalieri del CRM, report di agenzie di credito esterne.
- Non Strutturati: PDF di buste paga, email, registrazioni call center.
2. Layer di Processamento e Pulizia (Silver Layer)
Qui avviene la magia dell’ETL/ELT. Utilizzando motori distribuiti come Apache Spark o servizi gestiti come AWS Glue, i dati vengono puliti, deduplicati e normalizzati. È in questa fase che i dati non strutturati vengono trasformati in feature utilizzabili.
3. Layer di Aggregazione (Gold Layer)
I dati sono pronti per il consumo business e per l’analisi, organizzati in tabelle aggregate per cliente, pronte per essere interrogate via SQL (es. Athena, BigQuery o Databricks SQL).
Integrazione dei Dati Non Strutturati: La Sfida NLP

La vera innovazione nel data lakehouse credit scoring risiede nell’estrazione di feature da testo e immagini. Non possiamo inserire un PDF in un modello XGBoost, quindi dobbiamo processarlo nel Silver Layer.
Supponiamo di voler analizzare le email scambiate con il servizio clienti per rilevare segnali di stress finanziario. Il processo prevede:
- OCR e Text Extraction: Utilizzo di librerie come Tesseract o servizi cloud (AWS Textract) per convertire PDF/Immagini in testo.
- NLP Pipeline: Applicazione di modelli Transformer (es. BERT finetuned per il dominio finanziario) per estrarre entità (NER) o analizzare il sentiment.
- Feature Vectorization: Conversione del risultato in vettori numerici o score categorici (es. “Sentiment_Score_Last_30_Days”).
Il Ruolo Cruciale del Feature Store
Uno dei problemi più comuni nel MLOps è il training-serving skew: le feature calcolate durante il training del modello differiscono da quelle calcolate in tempo reale durante l’inferenza (quando il cliente chiede un prestito dall’app). Per risolvere questo problema, l’architettura Lakehouse deve integrare un Feature Store (come Feast, Hopsworks o SageMaker Feature Store).
Il Feature Store gestisce due viste:
- Offline Store: Basato sul Data Lakehouse, contiene lo storico profondo per il training dei modelli.
- Online Store: Un database a bassa latenza (es. Redis o DynamoDB) che serve l’ultimo valore noto delle feature per l’inferenza in tempo reale.
Esempio Pratico: Pipeline ETL con PySpark
Di seguito un esempio concettuale di come un job Spark potrebbe unire dati transazionali strutturati con score di sentiment derivati da dati non strutturati all’interno di un’architettura Delta Lake.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, current_timestamp
# Inizializzazione Spark con supporto Delta Lake
spark = SparkSession.builder
.appName("CreditScoringETL")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
# 1. Caricamento Dati Strutturati (Transazioni)
df_transactions = spark.read.format("delta").load("s3://datalake/silver/transactions")
# Feature Engineering: Media transata ultimi 30 giorni
feat_avg_spend = df_transactions.groupBy("customer_id")
.agg(avg("amount").alias("avg_monthly_spend"))
# 2. Caricamento Dati Non Strutturati Processati (Log Chat/Email)
# Assumiamo che una pipeline NLP precedente abbia salvato i sentiment score
df_sentiment = spark.read.format("delta").load("s3://datalake/silver/customer_sentiment")
# Feature Engineering: Sentiment medio
feat_sentiment = df_sentiment.groupBy("customer_id")
.agg(avg("sentiment_score").alias("avg_sentiment_risk"))
# 3. Join per creare il Feature Set Unificato
final_features = feat_avg_spend.join(feat_sentiment, "customer_id", "left_outer")
.fillna({"avg_sentiment_risk": 0.5}) # Gestione nulli
# 4. Scrittura nel Feature Store (Offline Layer)
final_features.write.format("delta")
.mode("overwrite")
.save("s3://datalake/gold/credit_scoring_features")
print("Pipeline completata: Feature Store aggiornato.")
Troubleshooting e Best Practices
Nell’implementazione di un sistema di data lakehouse credit scoring, è comune incontrare ostacoli specifici. Ecco come mitigarli:
Gestione della Privacy (GDPR/CCPA)
I dati non strutturati contengono spesso PII (Personally Identifiable Information) sensibili. È imperativo implementare tecniche di mascheramento o tokenizzazione nel Bronze Layer, prima che i dati diventino accessibili ai Data Scientist. Strumenti come Presidio di Microsoft possono automatizzare l’anonimizzazione del testo.
Data Drift
Il comportamento dei clienti cambia. Un modello addestrato sui dati del 2024 potrebbe non essere valido nel 2026. Monitorare la distribuzione statistica delle feature nel Feature Store è essenziale per attivare il ri-addestramento automatico dei modelli.
Latenza nell’Inferenza
Se il calcolo delle feature non strutturate (es. analisi di un PDF caricato al momento) è troppo lento, l’esperienza utente ne risente. In questi casi, si consiglia un’architettura ibrida: pre-calcolare tutto il possibile in batch (storico) e utilizzare modelli NLP leggeri e ottimizzati (es. DistilBERT on ONNX) per l’elaborazione real-time.
Conclusioni

Adottare un approccio Data Lakehouse per il credit scoring non è solo un aggiornamento tecnologico, ma un vantaggio competitivo strategico. Centralizzando dati strutturati e non strutturati e garantendo la loro coerenza tramite un Feature Store, le istituzioni finanziarie possono costruire profili di rischio olistici, riducendo i default e personalizzando l’offerta per il cliente. La chiave del successo risiede nella qualità della pipeline di ingegneria dei dati: un modello AI è valido solo quanto i dati che lo alimentano.
Domande frequenti

Il Data Lakehouse Credit Scoring è un modello architetturale ibrido che supera i limiti dei tradizionali Data Warehouse unendo la gestione dei dati strutturati con la flessibilità dei Data Lake. Questo approccio consente alle fintech di sfruttare fonti non strutturate, come email e documenti, per calcolare il rischio di credito con maggiore precisione, riducendo la dipendenza dai soli storici di pagamento.
I dati non strutturati, come PDF o log di chat, vengono elaborati nel Silver Layer tramite pipeline di NLP e OCR. Queste tecnologie convertono il testo e le immagini in vettori numerici o punteggi di sentiment, trasformando informazioni qualitative in feature quantitative che i modelli predittivi possono analizzare per valutare l’affidabilità del cliente.
Il Feature Store agisce come un sistema centrale per garantire la coerenza dei dati tra la fase di addestramento e quella di inferenza. Esso elimina il disallineamento noto come training-serving skew mantenendo due viste sincronizzate: un Offline Store per lo storico profondo e un Online Store a bassa latenza per fornire dati aggiornati in tempo reale durante le richieste di credito.
L’infrastruttura si organizza in tre stadi principali: il Bronze Layer per l’ingestione dei dati grezzi, il Silver Layer per la pulizia e l’arricchimento tramite algoritmi di elaborazione, e il Gold Layer dove i dati sono aggregati e pronti per l’uso business. Questa struttura a strati assicura scalabilità, governance e qualità del dato lungo tutto il ciclo di vita.
La protezione delle informazioni personali avviene implementando tecniche di mascheramento e tokenizzazione direttamente nel livello di ingestione, il Bronze Layer. Utilizzando strumenti specifici per l’anonimizzazione automatica, è possibile analizzare i comportamenti e i trend dai dati non strutturati senza esporre le identità dei clienti o violare normative come il GDPR.
Fonti e Approfondimenti

- Banca d’Italia: Analisi sull’uso del Machine Learning nel credit scoring delle imprese
- Autorità Bancaria Europea (EBA): Report su Big Data e Advanced Analytics nel settore bancario
- Wikipedia: Definizione tecnica e caratteristiche dell’architettura Data Lakehouse
- Bank for International Settlements: Studio sugli effetti del prestito FinTech e l’uso di dati alternativi

Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.