Kurz gesagt (TL;DR)
Die RAG-Architektur revolutioniert die Finanzanalyse, indem sie komplexe Richtlinien in sofortiges Wissen verwandelt und die Prüfzeiten von Stunden auf Sekunden reduziert.
Eine robuste Pipeline erfordert fortschrittliches semantisches Chunking, um Tabellen und rechtliche Strukturen zu bewältigen, die typisch für unstrukturierte Bankdokumente sind.
Die Präzision der Antworten wird durch Prompts gewährleistet, die Halluzinationen verhindern und überprüfbare Verweise auf die ursprünglichen normativen Quellen erzwingen.
Der Teufel steckt im Detail. 👇 Lesen Sie weiter, um die kritischen Schritte und praktischen Tipps zu entdecken, um keine Fehler zu machen.
In der heutigen Finanzlandschaft ist die Geschwindigkeit der Informationsverarbeitung zu einem entscheidenden Wettbewerbsvorteil geworden. Für Kreditvermittler und Banken besteht die größte Herausforderung nicht im Mangel an Daten, sondern in deren Fragmentierung in unstrukturierten Dokumenten. Die Implementierung einer Fintech-RAG-Architektur (Retrieval-Augmented Generation) stellt die ultimative Lösung dar, um Betriebshandbücher und Richtlinien zur Kreditvergabe in umsetzbares Wissen zu verwandeln.
Stellen Sie sich ein gängiges Szenario vor: Ein Makler muss die Machbarkeit einer Hypothek für einen Kunden mit ausländischem Einkommen prüfen, indem er die Richtlinien von 20 verschiedenen Instituten konsultiert. Manuell dauert dies Stunden. Mit einem gut konzipierten RAG-System, wie es die Entwicklung fortschrittlicher CRM-Plattformen wie BOMA zeigt, reduziert sich die Zeit auf wenige Sekunden. Der Finanzsektor toleriert jedoch keine Fehler: Eine Halluzination des Sprachmodells (LLM) kann zu einer falschen Entscheidung und Compliance-Risiken führen.
Dieser technische Leitfaden untersucht, wie man eine robuste RAG-Pipeline aufbaut, wobei der Fokus auf den Besonderheiten des Bankwesens liegt: von der Handhabung komplexer PDFs bis zur strengen Quellenangabe.

Ingestion-Pipeline: Vom PDF zum Vektor
Das Herzstück einer effektiven Fintech-RAG-Architektur liegt in der Qualität der Eingangsdaten. Bankrichtlinien liegen oft im PDF-Format vor, reich an Tabellen (z. B. LTV/Einkommens-Raster), Fußnoten und voneinander abhängigen Rechtsklauseln. Ein einfacher Text-Parser würde daran scheitern, die notwendige logische Struktur zu bewahren.
Strategien für semantisches Chunking
Das Unterteilen des Textes in Segmente (Chunking) ist ein kritischer Schritt. Im Kreditkontext kann das Halbieren eines Absatzes die Bedeutung einer Ausschlussregel verändern. Nach aktuellen Best Practices für die Dokumentenverarbeitung:
- Hierarchisches Chunking: Anstatt nach einer festen Anzahl von Token zu unterteilen, ist es wichtig, die Dokumentenstruktur (Titel, Artikel, Absatz) zu respektieren. Die Verwendung von Bibliotheken wie LangChain oder LlamaIndex ermöglicht die Konfiguration von Splittern, die Header in juristischen Dokumenten erkennen.
- Kontextueller Overlap: Es ist ratsam, eine Überlappung (Overlap) von 15–20 % zwischen den Chunks beizubehalten, um sicherzustellen, dass der Kontext an den Schnittkanten nicht verloren geht.
- Tabellenmanagement: Tabellen müssen extrahiert, in Markdown- oder JSON-Format linearisiert und als einzigartige semantische Einheiten eingebettet werden. Wenn eine Tabelle zerstückelt wird, kann das Modell Zeilen und Spalten während der Retrieval-Phase nicht korrekt zuordnen.
Wahl der Vektordatenbank: Pinecone vs. pgvector
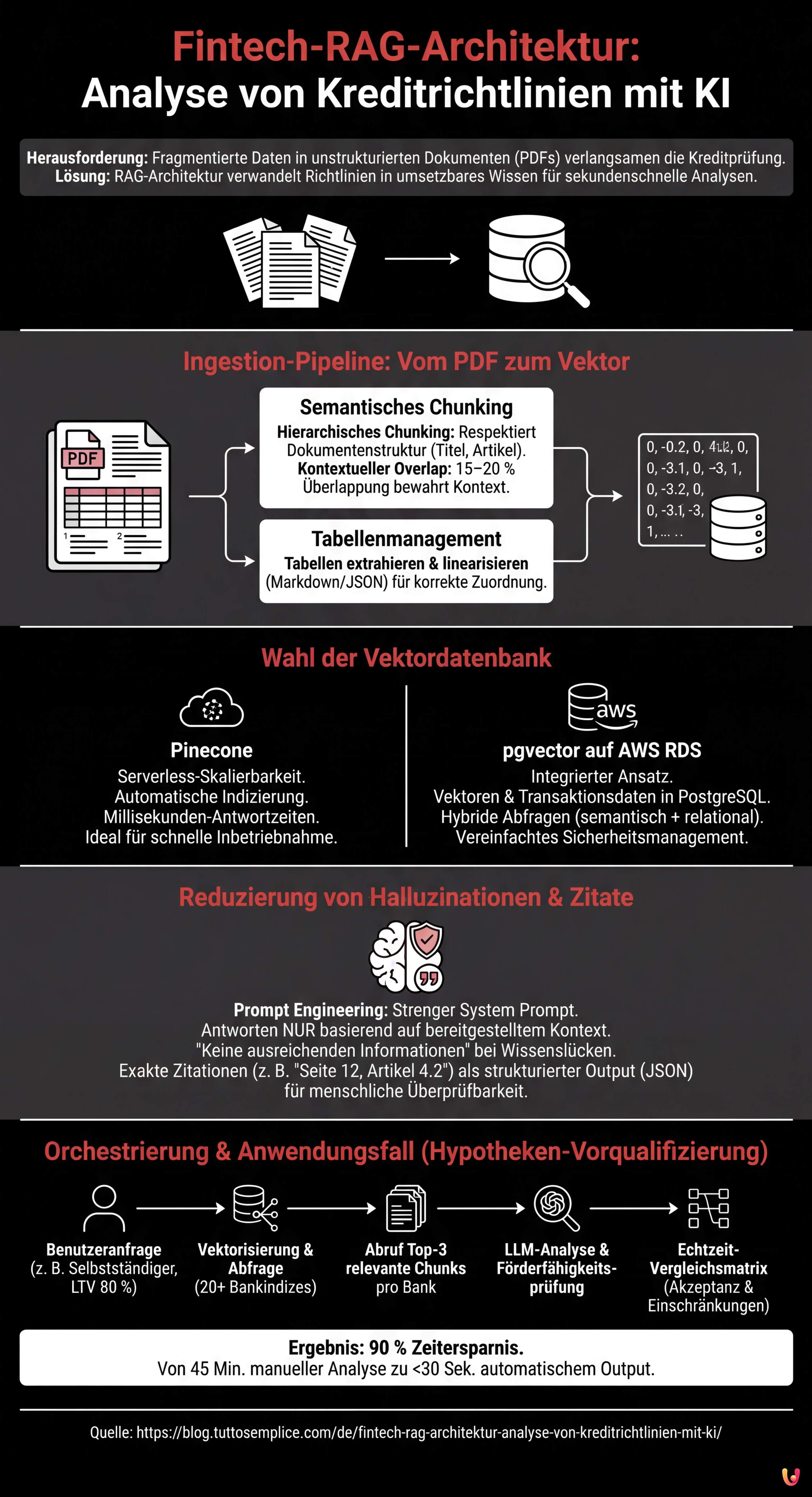
Sobald die Chunks in numerische Vektoren (Embeddings) umgewandelt sind, müssen sie in einer Vektordatenbank archiviert werden. Die Wahl der Infrastruktur wirkt sich auf Latenz und Kosten aus.
Pinecone: Serverless-Skalierbarkeit
Für Projekte, die eine schnelle Inbetriebnahme und automatische Skalierung erfordern, bleibt Pinecone ein Referenzstandard. Seine Serverless-Architektur verwaltet die Indizierung automatisch und bietet Antwortzeiten im Millisekundenbereich, was für eine flüssige Benutzererfahrung in einem CRM unerlässlich ist.
pgvector auf AWS RDS: Der integrierte Ansatz
Für Finanzinstitute jedoch, die bereits PostgreSQL auf AWS RDS für Transaktionsdaten nutzen, bietet die Erweiterung pgvector erhebliche Vorteile. Das Vorhalten der Vektoren in derselben Datenbank wie die Kundendaten vereinfacht das Sicherheitsmanagement und ermöglicht hybride Abfragen (z. B. Filtern der Vektoren nicht nur nach semantischer Ähnlichkeit, sondern auch nach relationalen Metadaten wie “Bank-ID” oder “Gültigkeitsdatum der Richtlinie”). Dies reduziert die Infrastrukturkomplexität und die Data-Egress-Kosten.
Reduzierung von Halluzinationen: Prompt Engineering und Zitate

Im Fintech-Bereich ist Präzision nicht verhandelbar. Eine Fintech-RAG-Architektur muss so konzipiert sein, dass sie Unwissenheit zugibt, anstatt eine Antwort zu erfinden. Prompt Engineering spielt hier eine fundamentale Rolle.
Es ist notwendig, einen strengen System Prompt zu implementieren, der das Modell anweist:
- Ausschließlich basierend auf dem bereitgestellten Kontext (den abgerufenen Chunks) zu antworten.
- “Ich habe keine ausreichenden Informationen” zu erklären, wenn die Richtlinie den spezifischen Fall nicht abdeckt.
- Die exakte Zitation zu liefern (z. B. “Seite 12, Artikel 4.2”).
Technisch wird dies erreicht, indem der Output des LLM nicht als Freitext, sondern als strukturiertes Objekt (JSON) strukturiert wird, das separate Felder für die Antwort und die Quellenverweise enthalten muss. Dies ermöglicht es dem Frontend der Anwendung, dem Bediener den direkten Link zum Original-PDF anzuzeigen, was die menschliche Überprüfbarkeit der Daten garantiert.
Orchestrierung mit LangChain: Der praktische Anwendungsfall
Die finale Orchestrierung erfolgt über Frameworks wie LangChain, die das Retrieval mit dem generativen Modell verbinden. In einem realen Anwendungsfall für die Hypotheken-Vorqualifizierung sieht der operative Ablauf wie folgt aus:
Der Benutzer gibt die Kundendaten ein (z. B. “Selbstständiger, Pauschalbesteuerung, LTV 80 %”). Das System wandelt diese Anfrage in einen Vektor um und fragt gleichzeitig die Vektorindizes von 20 Kreditinstituten ab. Das System ruft die Top-3 relevantesten Chunks für jede Bank ab.
Anschließend analysiert das LLM die abgerufenen Chunks, um die Förderfähigkeit zu bestimmen. Das Ergebnis ist eine in Echtzeit generierte Vergleichsmatrix, die hervorhebt, welche Banken den Antrag akzeptieren würden und mit welchen Einschränkungen. Nach Daten, die bei der Entwicklung ähnlicher Lösungen erhoben wurden, reduziert dieser Ansatz die Vorqualifizierungszeiten um 90 %, von einer manuellen Analyse von 45 Minuten auf einen automatischen Output in weniger als 30 Sekunden.
Fazit

Die Implementierung einer Fintech-RAG-Architektur zur Analyse von Kreditrichtlinien ist nicht nur eine technologische Übung, sondern ein strategischer Hebel für die operative Effizienz. Der Schlüssel zum Erfolg liegt nicht im leistungsstärksten Sprachmodell, sondern in der Sorgfalt der Daten-Ingestion-Pipeline und dem strengen Kontextmanagement. Durch den Einsatz von semantischen Chunking-Strategien und optimierten Vektordatenbanken ist es möglich, virtuelle Assistenten zu schaffen, die nicht nur die Bankensprache verstehen, sondern als Garanten der Compliance agieren und präzise, verifizierte und nachvollziehbare Antworten bieten.
Häufig gestellte Fragen

Eine Fintech-RAG-Architektur, kurz für Retrieval-Augmented Generation, ist eine Technologie, die die Informationssuche in Dokumentendatenbanken mit der generativen Fähigkeit künstlicher Intelligenz kombiniert. Im Finanzsektor dient sie dazu, unstrukturierte Dokumente wie Betriebshandbücher und Kreditrichtlinien im PDF-Format in sofort zugängliches Wissen zu verwandeln. Dies ermöglicht Banken und Maklern, riesige Datenmengen schnell abzufragen, um die Machbarkeit von Hypotheken und Krediten zu prüfen, wodurch die manuelle Analysezeit von Stunden auf wenige Sekunden reduziert wird.
Um die im Bankwesen erforderliche Präzision zu gewährleisten und vom Modell erfundene Antworten zu vermeiden, ist die Implementierung eines strengen System Prompts unerlässlich. Dieser weist die künstliche Intelligenz an, ausschließlich auf der Grundlage der aus den offiziellen Dokumenten abgerufenen Textsegmente zu antworten und Unwissenheit zuzugeben, wenn die Information fehlt. Darüber hinaus muss das System so konfiguriert sein, dass es exakte Quellenangaben liefert, damit menschliche Bediener den Artikel oder die Seite des Originaldokuments, aus dem die Information stammt, direkt überprüfen können.
Der effektive Umgang mit Dokumenten, die reich an Tabellen und rechtlichen Hinweisen sind, erfordert den Einsatz von semantischen Chunking-Strategien anstelle einer einfachen Unterteilung nach Zeichenanzahl. Es ist wichtig, die hierarchische Struktur des Dokuments zu respektieren, Artikel und Absätze intakt zu lassen und einen kontextuellen Overlap zwischen den Segmenten zu verwenden. Tabellen, insbesondere solche mit LTV- oder Einkommensrastern, müssen extrahiert und in strukturierte Formate wie JSON oder Markdown linearisiert werden, damit das Modell die Beziehungen zwischen den Daten während des Abrufs korrekt interpretieren kann.
Die Wahl der Vektordatenbank hängt von den infrastrukturellen Prioritäten des Finanzinstituts ab. Pinecone ist oft die beste Wahl für diejenigen, die sofortige Serverless-Skalierbarkeit und minimale Latenz ohne komplexes Management benötigen. Im Gegensatz dazu ist pgvector auf AWS RDS ideal für Unternehmen, die bereits PostgreSQL für Transaktionsdaten verwenden, da es hybride Abfragen ermöglicht, indem Ergebnisse sowohl nach semantischer Ähnlichkeit als auch nach relationalen Metadaten gefiltert werden, was die Sicherheit vereinfacht und die Kosten für die Datenverschiebung senkt.
Die Implementierung einer gut konzipierten RAG-Pipeline kann die Betriebszeiten drastisch reduzieren. Nach Daten, die bei der Entwicklung ähnlicher Lösungen erhoben wurden, kann die für die Vorqualifizierung eines Antrags erforderliche Zeit um 90 Prozent sinken. Man wechselt von einer manuellen Analyse, die etwa 45 Minuten für die Konsultation verschiedener Bankrichtlinien erfordern könnte, zu einem automatischen und vergleichenden Output, der in weniger als 30 Sekunden generiert wird, was die Effizienz und Reaktionsfähigkeit gegenüber dem Endkunden erheblich verbessert.
Quellen und Vertiefung

- BaFin – Aufsichtsprinzipien für Big Data und künstliche Intelligenz im Finanzsektor
- Europäische Kommission – Das europäische Konzept für künstliche Intelligenz (AI Act)
- Wikipedia – Definition und Funktionsweise von Retrieval Augmented Generation
- NIST – Framework für das Risikomanagement von künstlicher Intelligenz

Fanden Sie diesen Artikel hilfreich? Gibt es ein anderes Thema, das Sie von mir behandelt sehen möchten?
Schreiben Sie es in die Kommentare unten! Ich lasse mich direkt von Ihren Vorschlägen inspirieren.