Kurz gesagt (TL;DR)
Die Automatisierung durch NLP transformiert die Immobilien-Lead-Qualifizierung und überwindet statische Formulare, um präzise Daten aus natürlichen Gesprächen zu extrahieren.
Das Fine-Tuning italienischer BERT-Modelle ermöglicht die Erstellung maßgeschneiderter NER-Systeme, die Beträge, Berufe und Immobilientypen identifizieren können.
Die Normalisierung der extrahierten Daten und die direkte Integration in das CRM BOMA optimieren die Berechnung des Kreditratings und das Vertriebsmanagement.
Der Teufel steckt im Detail. 👇 Lesen Sie weiter, um die kritischen Schritte und praktischen Tipps zu entdecken, um keine Fehler zu machen.
Im Wettbewerbsumfeld des Jahres 2026 ist die Reaktionsgeschwindigkeit nicht mehr der einzige entscheidende Faktor im Kredit- und Immobiliensektor. Die wahre Herausforderung liegt in der Präzision und der Fähigkeit, das Rauschen zu filtern. Die Immobilien-Lead-Qualifizierung hat sich von einer manuellen Aufgabe in Callcentern zu einem automatisierten Prozess gewandelt, der von Algorithmen des Natural Language Processing (NLP) gesteuert wird. In diesem technischen Leitfaden werden wir untersuchen, wie man ein maßgeschneidertes System zur Named Entity Recognition (NER) aufbaut, um strukturierte Daten aus unstrukturierten Konversationen zu extrahieren und diese direkt in das CRM BOMA zu integrieren.

Warum Entity Extraction die Immobilien-Lead-Qualifizierung verändert
Statische Formulare auf Websites (Vorname, Nachname, Telefon) weisen immer niedrigere Konversionsraten auf. Nutzer bevorzugen die Interaktion über natürliche Chats oder Sprachnachrichten. Dies erzeugt jedoch unstrukturierte Daten, die schwer zu verarbeiten sind. Hier kommt die semantische Entity Extraction ins Spiel.
Das Ziel ist nicht nur, die Absicht zu verstehen (z. B. “Ich möchte eine Hypothek”), sondern spezifische Informations-Slots zu extrahieren, die für die Berechnung des Kreditratings oder die Machbarkeit des Kaufs erforderlich sind. Ein gut konzipiertes System muss Folgendes identifizieren:
- ENT_AMOUNT: Der angeforderte Betrag (z. B. “ich brauche 200k”).
- ENT_LTV: Der implizite Beleihungsauslauf (Loan-to-Value) oder der Immobilienwert.
- ENT_JOB_TYPE: Die Art des Arbeitsvertrags (z. B. “unbefristet”, “selbstständig mit Pauschalsteuer”).
- ENT_PROPERTY: Immobilientyp und Energieklasse.
Voraussetzungen und Technologie-Stack
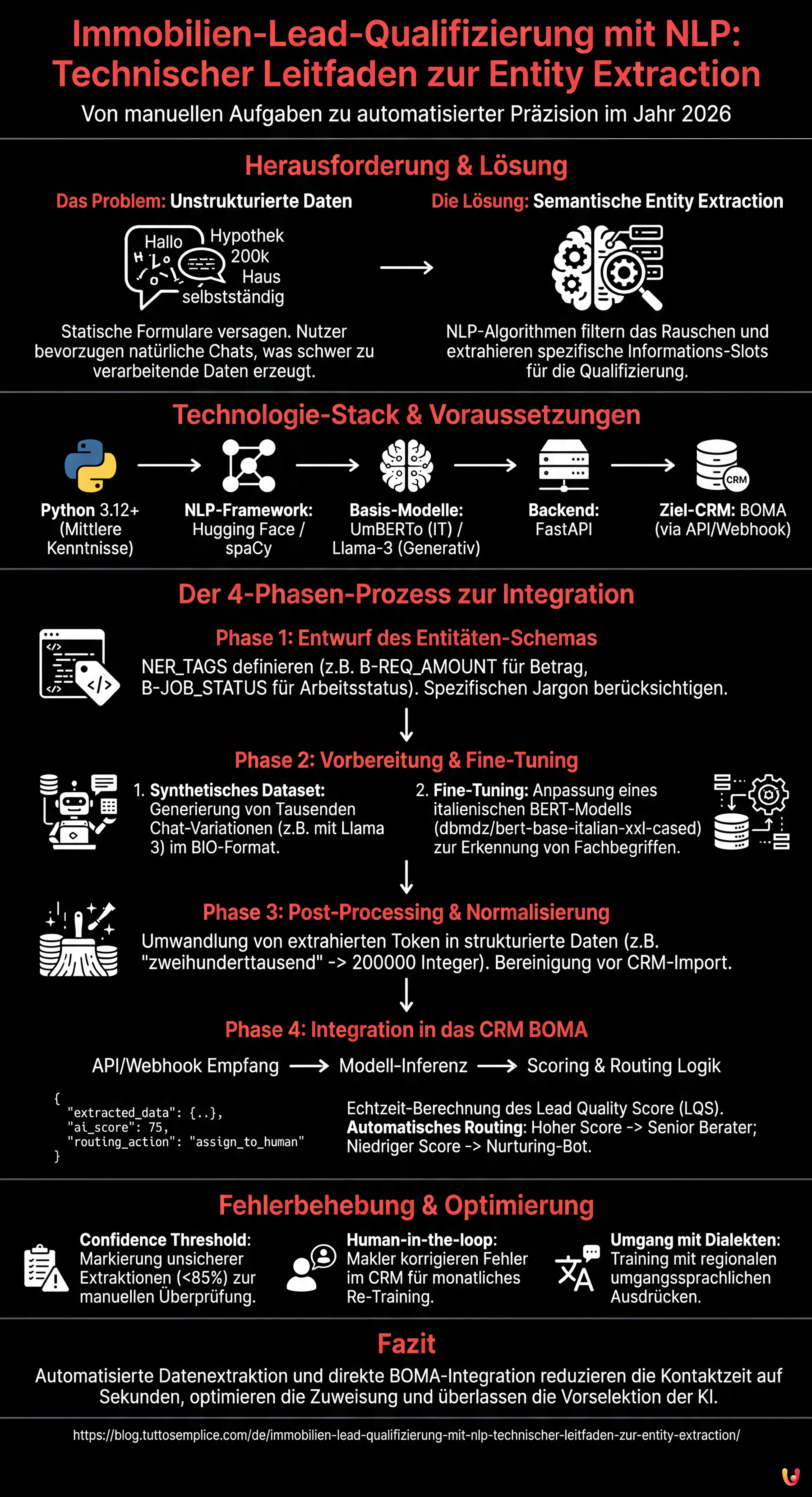
Um diesem Leitfaden folgen zu können, sind mittlere Kenntnisse in Python und den Prinzipien des maschinellen Lernens erforderlich. Wir verwenden den folgenden Stack, standardisiert für 2026:
- Sprache: Python 3.12+
- NLP-Framework: Hugging Face Transformers, spaCy 4.x
- Basis-Modelle:
UmBERTo(für Italienisch) oder quantisierte Versionen vonLlama-3-8B-Instructfür generative Aufgaben. - Backend: FastAPI für die Bereitstellung des Modells.
- Ziel-CRM: BOMA (via REST API/Webhook).
Phase 1: Entwurf des Entitäten-Schemas

Bevor wir Code schreiben, müssen wir definieren, wonach unser Modell suchen soll. Im Kontext italienischer Hypotheken ist der Jargon spezifisch. Ein generisches Modell würde scheitern, zwischen “Anzahlung” (anticipo) und “Rate” (rata) zu unterscheiden.
Wir definieren die Labels für unseren Trainingsdatensatz:
NER_TAGS = [
"O", # Outside (keine Entität)
"B-REQ_AMOUNT", # Beginn angeforderter Betrag
"I-REQ_AMOUNT", # Innerhalb angeforderter Betrag
"B-JOB_STATUS", # Beginn Arbeitsstatus
"I-JOB_STATUS", # Innerhalb Arbeitsstatus
"B-PROPERTY_VAL", # Immobilienwert
"B-INTENT_TIME" # Gewünschter Zeitrahmen (z. B. "Notartermin bis März")
]
Phase 2: Vorbereitung des Datasets und Fine-Tuning
Um eine präzise Immobilien-Lead-Qualifizierung zu erreichen, können wir uns für die Massenextraktion nicht auf generalistische Zero-Shot-Modelle verlassen, da diese teuer und langsam sind. Die beste Lösung ist das Fine-Tuning eines italienischen BERT-basierten Modells.
1. Erstellung des synthetischen Datasets
Wenn Sie über keine DSGVO-konformen Chat-Verläufe verfügen, können Sie ein synthetisches Dataset unter Verwendung eines LLM (wie Meta AI Llama 3) generieren, um Tausende von Variationen typischer Sätze zu erstellen:
“Ich bin Staatsangestellter und suche eine Hypothek für ein Haus im Wert von 250.000 Euro, ich habe 50k Anzahlung.”
Annotieren Sie diese Sätze im Standard-JSONL-Format für das Training (BIO-Format).
2. Fine-Tuning mit Hugging Face
Wir werden dbmdz/bert-base-italian-xxl-cased als Basis verwenden, da es eines der leistungsfähigsten Modelle für die italienische Syntax ist. Hier ist ein vereinfachter Ausschnitt für den Trainings-Loop:
from transformers import AutoTokenizer, AutoModelForTokenClassification, TrainingArguments, Trainer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=len(NER_TAGS))
args = TrainingArguments(
output_dir="./boma-ner-v1",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
num_train_epochs=5,
weight_decay=0.01,
)
# Angenommen, 'tokenized_datasets' ist bereits vorbereitet
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
)
trainer.train()
Dieser Prozess passt die Gewichte des Modells an, um spezifische Begriffe wie “Umschuldung” (surroga), “Festzins” (tasso fisso) oder “Berater” (consulente) im Kontext des Satzes zu erkennen.
Phase 3: Post-Processing und Normalisierung
Das NER-Modell gibt Token und Labels zurück. Für die Immobilien-Lead-Qualifizierung müssen wir "zweihunderttausend Euro" in 200000 (Integer) umwandeln. Diese Normalisierungsphase ist kritisch für das Befüllen der Datenbank.
Wir verwenden Bibliotheken wie word2number für Italienisch oder benutzerdefinierte Regex, um die Ausgabe des Modells vor dem Senden an das CRM zu bereinigen.
Phase 4: Integration in das CRM BOMA
Sobald das Modell über eine API bereitgestellt wird (z. B. in einem Docker-Container), müssen wir es mit dem Eingangsstrom der Leads verbinden. Die Integration mit BOMA erfolgt normalerweise über Webhooks, die beim Empfang einer neuen Nachricht ausgelöst werden.
Logik für Scoring und Routing
Nicht alle Leads sind gleich. Unter Verwendung der extrahierten Daten können wir einen Lead Quality Score (LQS) in Echtzeit berechnen:
- Lead A (Score 90/100): Vollständige Daten (Arbeit, Betrag, Immobilie), LTV Sofortiges Routing an den Senior Consultant.
- Lead B (Score 40/100): Teilweise Daten, LTV > 95%, befristeter Vertrag. -> Routing an den automatischen Nurturing-Bot.
Hier ist ein Beispiel für einen JSON-Payload zum Senden an die BOMA-APIs:
{
"lead_source": "Whatsapp_Business",
"message_body": "Hallo, ich hätte gerne Infos für eine Hypothek für das erste Haus, ich bin Krankenpfleger",
"extracted_data": {
"job_type": "Krankenpfleger",
"job_category": "oeffentlicher_dienst",
"intent": "kauf_erstwohnsitz"
},
"ai_score": 75,
"routing_action": "assign_to_human"
}
Fehlerbehebung: Umgang mit Halluzinationen und Mehrdeutigkeit
Auch die besten Modelle können Fehler machen. So mindern Sie die Risiken:
- Confidence Threshold: Wenn das Modell eine Entität mit einer Konfidenz von weniger als 85% extrahiert, muss das System das Feld im CRM BOMA als “Zu überprüfen” markieren und menschliches Eingreifen erfordern.
- Human-in-the-loop: Implementieren Sie einen Feedback-Mechanismus, bei dem Immobilienmakler die Labeling-Fehler im CRM korrigieren können. Diese korrigierten Daten müssen in das Trainings-Dataset für das monatliche Re-Training des Modells zurückfließen.
- Umgang mit Dialekten: Trainieren Sie das Modell mit Datasets, die regionale umgangssprachliche Ausdrücke enthalten, die oft in informellen Chats verwendet werden.
Fazit

Die Implementierung eines Systems zur Entity Extraction für die Immobilien-Lead-Qualifizierung ist keine akademische Übung mehr, sondern eine operative Notwendigkeit. Durch die Automatisierung der Extraktion kritischer Daten (LTV, Arbeit, Budget) und deren direkte Integration in BOMA können Agenturen die Zeit bis zum ersten Kontakt von Stunden auf Sekunden reduzieren, die komplexesten Fälle den besten Beratern zuweisen und der KI die Verwaltung der anfänglichen Selektion überlassen.
Häufig gestellte Fragen

Es handelt sich um einen auf NLP basierenden Prozess, der spezifische Daten wie Hypothekenbetrag oder Vertragsart aus natürlichen und unstrukturierten Konversationen identifiziert und extrahiert. Im Gegensatz zu statischen Formularen ermöglicht diese Technologie, die Absicht des Nutzers zu verstehen und die für die Berechnung des Kreditratings erforderlichen Felder direkt im CRM automatisch zu befüllen.
Um eine hohe Leistung bei der italienischen Syntax zu erzielen, ist das Fine-Tuning von BERT-basierten Modellen wie UmBERTo oder dbmdz bert-base-italian die beste Wahl. Diese Modelle sind generalistischen Zero-Shot-Lösungen überlegen, da sie trainiert werden können, um den spezifischen Jargon des Kreditsektors zu erkennen und technische Begriffe wie «Rate», «Anzahlung» oder «Umschuldung» zu unterscheiden.
Durch die Integration eines Modells zur Entitätsextraktion via API oder Webhook kann BOMA bereits bereinigte und normalisierte Daten empfangen. Dies ermöglicht es, dem Lead in Echtzeit einen Qualitäts-Score zuzuweisen und die Kontakte automatisch weiterzuleiten: Vollständige Profile gehen an Senior-Berater, während unvollständige von Nurturing-Bots verwaltet werden, was die Zeit des Vertriebsteams optimiert.
Ein gut konzipiertes System extrahiert kritische Entitäten wie den angeforderten Betrag, den Immobilienwert zur Berechnung des Loan-to-Value, die Art des Arbeitsvertrags und die Energieklasse des Hauses. Diese Daten, definiert als Informations-Slots, sind essenziell, um die Machbarkeit des Vorgangs sofort ohne lange Vorgespräche zu bestimmen.
Es ist notwendig, eine Konfidenzschwelle zu implementieren, beispielsweise bei 85 Prozent, unterhalb derer das System die Daten zur manuellen Überprüfung meldet. Zudem wird ein Human-in-the-loop-Ansatz verfolgt, bei dem Korrekturen durch Immobilienmakler gespeichert und für das periodische Nachtraining des Modells wiederverwendet werden, was die Präzision im Laufe der Zeit verbessert.
Quellen und Vertiefung

- Wikipedia: Named Entity Recognition (NER) – Definition und Funktionsweise
- Europäische Kommission: Datenschutz-Grundverordnung (DSGVO) – Regeln für die Datenverarbeitung
- BaFin: Verbraucherinformationen zu Immobilienkrediten und Kreditwürdigkeitsprüfung
- Europäische Kommission: Das europäische Gesetz über künstliche Intelligenz (AI Act)

Fanden Sie diesen Artikel hilfreich? Gibt es ein anderes Thema, das Sie von mir behandelt sehen möchten?
Schreiben Sie es in die Kommentare unten! Ich lasse mich direkt von Ihren Vorschlägen inspirieren.