Kurz gesagt (TL;DR)
SEO für YMYL-Sektoren erfordert strenges Prompt Engineering, um Halluzinationen zu vermeiden und Google-Qualitätskriterien zu erfüllen.
Fortgeschrittene Techniken wie Chain-of-Thought und Kontext-Injektion verwandeln probabilistische Modelle in zuverlässige Werkzeuge für komplexe Finanzdaten.
Die Orchestrierung über Python und APIs ermöglicht die mathematische Validierung von Inhalten, indem die reale Berechnung von der Textgenerierung getrennt wird.
Der Teufel steckt im Detail. 👇 Lesen Sie weiter, um die kritischen Schritte und praktischen Tipps zu entdecken, um keine Fehler zu machen.
Wir schreiben das Jahr 2026 und die Landschaft der Suchmaschinenoptimierung hat sich radikal verändert. Es reicht nicht mehr aus, ein LLM zu bitten, einen „Artikel über Hypotheken zu schreiben“. Im Sektor Your Money Your Life (YMYL), wo die Genauigkeit von Informationen die finanzielle Stabilität eines Nutzers beeinträchtigen kann, ist der generische Ansatz eine Einbahnstraße zur Deindexierung. Dieser technische Leitfaden untersucht SEO Prompt Engineering nicht als kreative Kunst, sondern als strenge Ingenieursdisziplin.
Wir werden analysieren, wie man Pipelines zur Inhaltserstellung baut, die die E-E-A-T-Kriterien (Experience, Expertise, Authoritativeness, Trustworthiness) von Google respektieren, unter Verwendung von Python, OpenAI-APIs und fortgeschrittenen Techniken wie Chain-of-Thought (CoT), um die mathematische Präzision sensibler Daten wie Sollzins und effektiver Jahreszins zu gewährleisten.

Das YMYL-Paradoxon: Warum Standard-Prompts scheitern
Large Language Models (LLM) sind probabilistische Motoren, keine Datenbanken der Wahrheit. Wenn es um Finanzen geht, ist eine KI-Halluzination (zum Beispiel das Erfinden eines Zinssatzes oder die falsche Berechnung einer Rate) inakzeptabel. Gemäß den Richtlinien der Google Quality Rater erfordern YMYL-Inhalte das höchste Maß an Genauigkeit.
Ein Standard-Prompt wie „Schreibe einen Leitfaden über Festzinshypotheken“ scheitert, weil:
- Er keinen Zugriff auf Marktdaten in Echtzeit hat (ohne RAG).
- Er dazu neigt, Finanzratschläge zu verallgemeinern, was gegen die Richtlinien zur Beratung verstößt.
- Er Daten nicht so strukturiert, dass Google sie als Entitäten interpretieren kann.
Das moderne SEO Prompt Engineering betrifft daher nicht die Generierung des Endtextes, sondern den Aufbau der logischen Architektur, die dem Schreiben vorausgeht.
Prompt-Architektur: Chain-of-Thought und Few-Shot
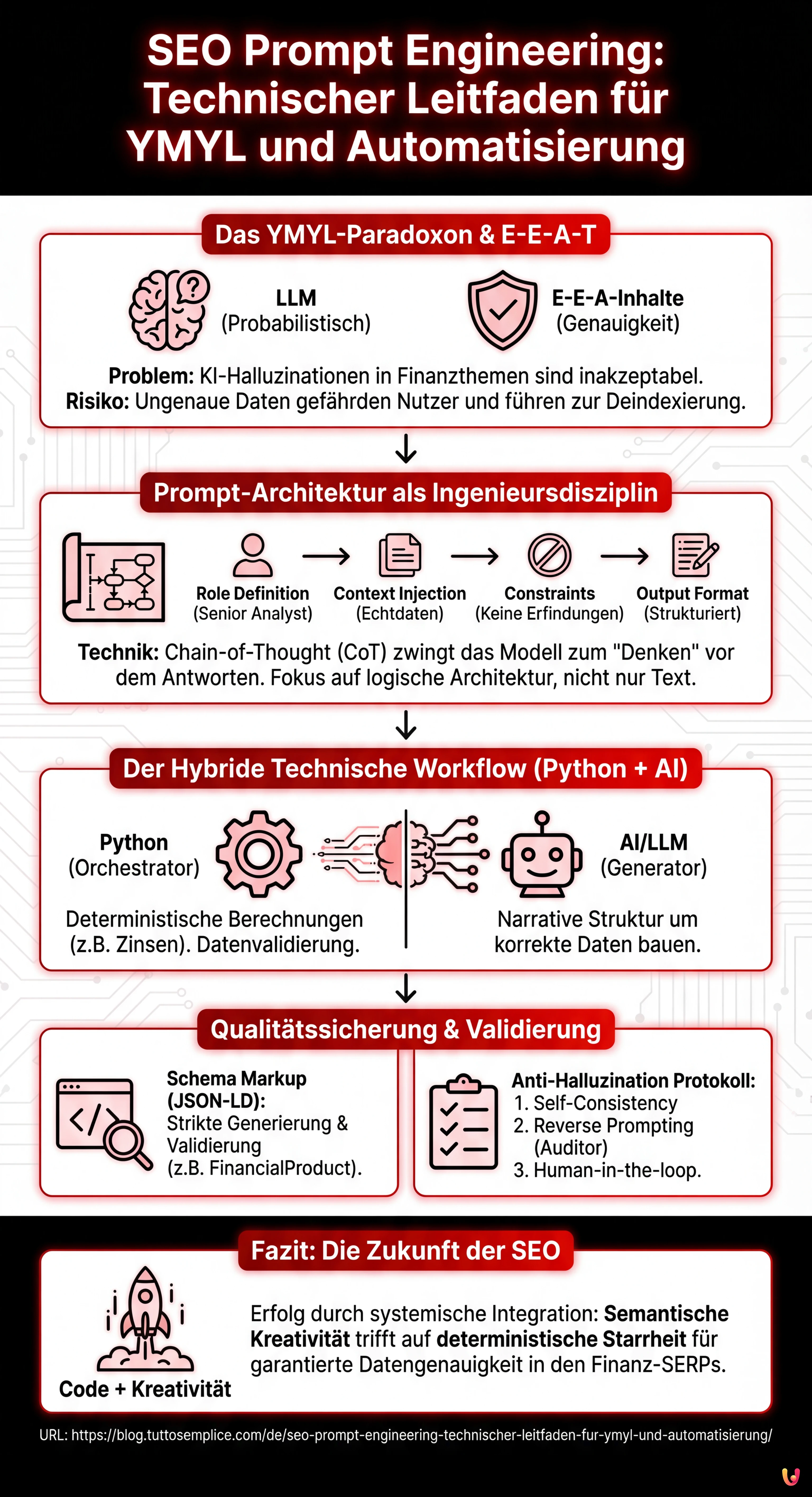
Um Fehler zu minimieren, müssen wir das Modell zwingen, zu „denken“, bevor es antwortet. Wir verwenden die Technik Chain-of-Thought (CoT). Anstatt direkt nach dem Output zu fragen, weisen wir das Modell an, die logischen Schritte zu skizzieren.
Beispiel für die Struktur des System-Prompts
Ein effektiver Prompt für Finanz-SEO muss modular sein. Hier ist eine getestete Struktur für die Produktionsumgebung:
- Role Definition: Definiere die KI nicht als Texter, sondern als „Senior Finanzanalyst mit Expertise in semantischer SEO“.
- Context Injection: Stelle Rohdaten (aktuelle Zinssätze, geltende Gesetze) als unveränderlichen Kontext bereit.
- Constraints: Negative Regeln (z. B. „Erfinde keine Zinssätze“, „Verwende keine Werbesprache“).
- Output Format: Anforderung eines strukturierten Outputs (JSON oder spezifisches Markdown).
Technischer Workflow: Python und OpenAI API

Kommen wir zur Praxis. Wir erstellen ein Python-Skript, das als „Orchestrator“ fungiert. Dieses System beschränkt sich nicht darauf, Text zu generieren, sondern validiert numerische Daten.
Voraussetzungen
- Python 3.10+
- Bibliothek
openai - Bibliothek
pydanticzur Datenvalidierung
Code: Kontrollierte Generierung mit Validierung
Das folgende Snippet zeigt, wie man Function Calling (oder Tools) verwendet, um sicherzustellen, dass Finanzberechnungen per Code ausgeführt und nicht statistisch vom Modell vorhergesagt werden.
import openai
from pydantic import BaseModel, Field
# Definition der erwarteten Datenstruktur (Schema Validation)
class FinancialContent(BaseModel):
titolo_h1: str = Field(..., description="SEO optimierter Titel")
intro_summary: str = Field(..., description="Zusammenfassung E-E-A-T konform")
calcolo_rata_esempio: float = Field(..., description="Die Ratenberechnung muss präzise sein")
spiegazione_tecnica: str
# Konfiguration des Clients (Pseudo-Code)
client = openai.OpenAI(api_key="DEIN_TOKEN")
def generate_finance_article(topic, interest_rate, loan_amount, years):
# Deterministische Berechnung (NICHT KI) zur Vermeidung von Halluzinationen
# Hypothekenformel: R = C * (i / (1 - (1 + i)**-n))
i = interest_rate / 12 / 100
n = years * 12
rata_reale = loan_amount * (i / (1 - (1 + i)**-n))
prompt = f"""
Du bist ein finanzieller SEO-Experte. Schreibe einen technischen Abschnitt über Festzinshypotheken.
ECHTDATEN OBLIGATORISCH:
- Betrag: {loan_amount}€
- Jahreszins: {interest_rate}%
- Laufzeit: {years} Jahre
- Mathematisch berechnete Rate: {rata_reale:.2f}€
ANWEISUNGEN:
1. Benutze die bereitgestellten Daten. Berechne die Rate NICHT neu, benutze den Wert '{rata_reale:.2f}'.
2. Erkläre, wie der Zinssatz den effektiven Jahreszins beeinflusst.
3. Bleibe neutral und institutionell.
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "system", "content": "Du bist ein Validator für Finanzinhalte."},
{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
# Ausführung
print(generate_finance_article("Festzinshypothek", 3.5, 200000, 20))Bei diesem hybriden Ansatz berechnet der Ingenieur die Mathematik (Python) und die KI baut die Erzählung um die korrekten Daten herum auf. Das ist der Kern des SEO Prompt Engineering für YMYL: Unsicherheit aus kritischen Punkten entfernen.
Automatisierung strukturierter Daten (Schema Markup)
Um in den Finanz-SERPs zu konkurrieren, ist das Markup FinancialProduct unerlässlich. Bitte die KI nicht darum, „das Schema zu generieren“. Verwende einen Prompt, der ein striktes JSON basierend auf den Spezifikationen von Schema.org zurückgibt.
Beispiel für eine Anweisung im System-Prompt:
„Generiere NUR ein gültiges JSON-LD Objekt für ‘FinancialProduct’. Verwende die im Kontext bereitgestellten Zinssatzwerte. Füge keinen Text vor oder nach dem JSON hinzu.“
Verwende anschließend eine Python-Bibliothek wie jsonschema, um den Output der KI zu validieren, bevor er in das HTML der Seite injiziert wird. Wenn die Validierung fehlschlägt, muss das Skript den Inhalt automatisch neu generieren.
Minderung von Halluzinationen und Fact-Checking
Selbst mit den besten Prompts sind Fehler möglich. Hier ist ein Überprüfungsprotokoll in 3 Phasen für YMYL-Inhalte:
1. Self-Consistency (Selbstkonsistenz)
Bitte das Modell, die Antwort dreimal zu generieren, und vergleiche die Ergebnisse. Wenn die numerischen Daten abweichen, verwerfe den Output und melde den Fehler an einen menschlichen Operator.
2. Reverse Prompting (Umgekehrte Überprüfung)
Verwende nach der Erstellung des Artikels einen zweiten Prompt (mit einer separaten Instanz der KI), der als „Auditor“ fungiert.
Prompt Auditor: „Analysiere den folgenden Text. Extrahiere alle Zinssätze und regulatorischen Aussagen. Vergleiche sie mit dieser Referenzdatenbank [Daten einfügen]. Melde jede Diskrepanz.“
3. Menschliche Überwachung (Human-in-the-loop)
Die Automatisierung bereitet den Entwurf zu 80-90% vor. Der SEO-/Finanzexperte muss den endgültigen Output immer validieren. Die KI dient dazu, die Produktion zu skalieren, nicht die redaktionelle Verantwortung zu ersetzen.
Fazit: Die Zukunft der technischen SEO
Das SEO Prompt Engineering im Jahr 2026 ist keine Frage von sprachlichen „Tricks“ mehr, sondern von systemischer Integration. Für YMYL-Sektoren liegt der Schlüssel zum Erfolg in der Fähigkeit, die semantische Kreativität von LLMs mit der deterministischen Starrheit von Code zu verschmelzen. Wer Pipelines bauen kann, die Datengenauigkeit (E-E-A-T) garantieren und gleichzeitig die semantische Struktur automatisieren, wird die Finanz-SERPs dominieren.
Häufig gestellte Fragen

SEO Prompt Engineering für YMYL-Sektoren ist eine technische Disziplin, die die semantische Kreativität von LLMs mit der Starrheit von Programmcode kombiniert. Im Gegensatz zum Standardschreiben verwendet diese Methode logische Architekturen und Datenvalidierung, um sicherzustellen, dass Finanzinhalte die E-E-A-T-Kriterien von Google erfüllen und Fehler vermieden werden, die das Ranking bestrafen oder die finanzielle Stabilität der Nutzer gefährden könnten.
Um Halluzinationen in Finanztexten vorzubeugen, ist ein hybrider Ansatz erforderlich, bei dem mathematische Berechnungen durch deterministische Skripte wie Python ausgeführt und nicht vom Sprachmodell vorhergesagt werden. Darüber hinaus stellt die Verwendung von Techniken wie Chain-of-Thought und dreistufigen Überprüfungsprotokollen, einschließlich menschlicher Überwachung und Reverse Prompting, sicher, dass numerische und regulatorische Daten vor der Veröffentlichung korrekt sind.
Generische Prompts scheitern in «Your Money Your Life»-Sektoren, weil Sprachmodelle probabilistische Motoren ohne Echtzeitzugriff auf Marktdaten sind und dazu neigen, komplexe Ratschläge zu verallgemeinern. Ohne strengen Kontext und extern injizierte Daten riskiert die künstliche Intelligenz, ungenaue Informationen über Zinssätze oder Vorschriften zu generieren, was gegen die Qualitätsrichtlinien der Suchmaschinen verstößt und zur Deindexierung des Inhalts führt.
Python fungiert als Orchestrator, der die Logik und Datenvalidierung verwaltet, bevor die KI den narrativen Text generiert. Konkret wird es verwendet, um präzise Finanzberechnungen durchzuführen, die Datenstruktur über spezifische Bibliotheken zu validieren und automatisch strukturierte Markups wie FinancialProduct zu generieren, wodurch sichergestellt wird, dass der endgültige Output technisch perfekt und für Rich Snippets optimiert ist.
Die Optimierung von Schema Markup sollte nicht der freien Interpretation der KI überlassen werden, sondern durch Prompts gesteuert werden, die einen Output in strengem JSON-Format basierend auf offiziellen Spezifikationen erfordern. Es ist entscheidend, Validierungsskripte zu verwenden, um zu überprüfen, ob der generierte Code die korrekte Syntax einhält, bevor er in das HTML injiziert wird, um sicherzustellen, dass Google Entitäten wie Finanzprodukte oder Dienstleistungen korrekt interpretieren kann.
Quellen und Vertiefung

- Google Search Central: Leitfaden zu hilfreichen, vertrauenswürdigen und nutzerorientierten Inhalten (E-E-A-T)
- Google Search Quality Evaluator Guidelines (Offizielles PDF zu YMYL und E-E-A-T)
- Deutsche Bundesbank: Aktuelle Statistiken zu Zinssätzen und Renditen
- Wikipedia: Definition und Techniken des Prompt Engineering

Fanden Sie diesen Artikel hilfreich? Gibt es ein anderes Thema, das Sie von mir behandelt sehen möchten?
Schreiben Sie es in die Kommentare unten! Ich lasse mich direkt von Ihren Vorschlägen inspirieren.