In Breve (TL;DR)
L’adozione del modello ELT garantisce alle istituzioni Fintech auditabilità completa e velocità di calcolo essenziali per la conformità normativa.
L’integrazione di Google BigQuery e Apache Airflow assicura un’ingestione dati scalabile mantenendo inalterato lo storico delle transazioni finanziarie.
L’utilizzo di dbt eleva le trasformazioni dati a codice software, ottimizzando la governance e la precisione nel calcolo dei KPI.
Il diavolo è nei dettagli. 👇 Continua a leggere per scoprire i passaggi critici e i consigli pratici per non sbagliare.
Nel panorama dell’ingegneria dei dati del 2026, la scelta dell’architettura corretta per la movimentazione dei dati non è solo una questione di performance, ma di conformità normativa, specialmente nel settore finanziario. Quando si progetta una pipeline etl vs elt per un’istituzione Fintech, la posta in gioco include la precisione decimale, l’auditabilità completa (Lineage) e la capacità di calcolare il rischio in tempo quasi reale. Questa guida tecnica esplora perché l’approccio ELT (Extract, Load, Transform) è diventato lo standard de facto rispetto al tradizionale ETL, utilizzando uno stack moderno composto da Google BigQuery, dbt (data build tool) e Apache Airflow.

ETL vs ELT: Il Cambio di Paradigma nel Fintech
Per anni, l’approccio ETL (Extract, Transform, Load) è stato dominante. I dati venivano estratti dai sistemi transazionali (es. database dei mutui), trasformati in un server intermedio (staging area) e infine caricati nel Data Warehouse. Questo approccio, sebbene sicuro, presentava colli di bottiglia significativi: la potenza di calcolo del server di trasformazione limitava la velocità e ogni modifica alla logica di business richiedeva complessi aggiornamenti della pipeline prima ancora che il dato atterrasse nel warehouse.
Con l’avvento dei Cloud Data Warehouse come Google BigQuery e AWS Redshift, il paradigma si è spostato verso l’ELT (Extract, Load, Transform). In questo modello:
- Extract: I dati vengono estratti dai sistemi sorgente (CRM, Core Banking).
- Load: I dati vengono caricati immediatamente nel Data Warehouse in formato grezzo (Raw Data).
- Transform: Le trasformazioni avvengono direttamente all’interno del Warehouse sfruttando la sua potenza di calcolo massiva (MPP).
Per il Fintech, l’ELT offre un vantaggio cruciale: l’auditabilità. Poiché i dati grezzi sono sempre disponibili nel Warehouse, è possibile ricostruire la storia di qualsiasi transazione o ricalcolare i KPI retroattivamente senza dover rieseguire l’estrazione.
Architettura della Soluzione: Lo Stack Moderno
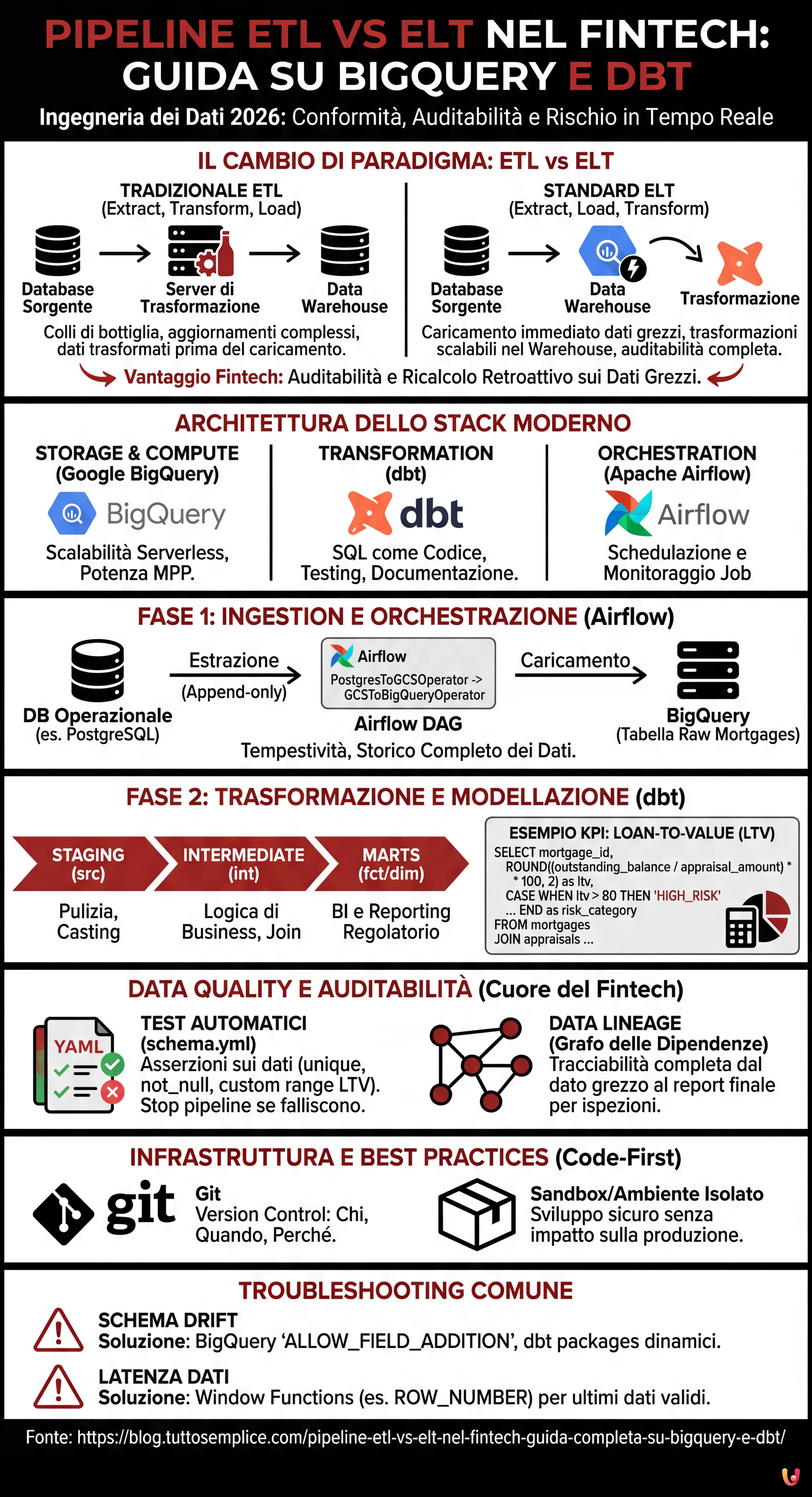
Per costruire una pipeline robusta per la gestione dei mutui, utilizzeremo il seguente stack tecnologico, considerato best-practice nel 2026:
- Storage & Compute: Google BigQuery (per la scalabilità serverless).
- Transformation: dbt (per gestire le trasformazioni SQL, la documentazione e il testing).
- Orchestration: Apache Airflow (per schedulare e monitorare i job).
Fase 1: Ingestion e Orchestrazione con Apache Airflow

Il primo passo è portare i dati nel Data Lake/Warehouse. In un contesto Fintech, la tempestività è fondamentale. Utilizziamo Apache Airflow per orchestrare l’estrazione dai database operazionali (es. PostgreSQL) verso BigQuery.
Esempio di DAG Airflow per l’Ingestion
Il seguente snippet concettuale mostra come configurare un task per caricare i dati dei mutui in modalità “append-only” per mantenere lo storico completo.
from airflow import DAG
from airflow.providers.google.cloud.transfers.postgres_to_gcs import PostgresToGCSOperator
from airflow.providers.google.cloud.transfers.gcs_to_bigquery import GCSToBigQueryOperator
from airflow.utils.dates import days_ago
with DAG('fintech_mortgage_ingestion', start_date=days_ago(1), schedule_interval='@hourly') as dag:
extract_mortgages = PostgresToGCSOperator(
task_id='extract_mortgages_raw',
postgres_conn_id='core_banking_db',
sql='SELECT * FROM mortgages WHERE updated_at > {{ prev_execution_date }}',
bucket='fintech-datalake-raw',
filename='mortgages/{{ ds }}/mortgages.json',
)
load_to_bq = GCSToBigQueryOperator(
task_id='load_mortgages_bq',
bucket='fintech-datalake-raw',
source_objects=['mortgages/{{ ds }}/mortgages.json'],
destination_project_dataset_table='fintech_warehouse.raw_mortgages',
write_disposition='WRITE_APPEND', # Cruciale per lo storico
source_format='NEWLINE_DELIMITED_JSON',
)
extract_mortgages >> load_to_bq
Fase 2: Trasformazione e Modellazione con dbt
Una volta che i dati sono in BigQuery, entra in gioco dbt. A differenza delle stored procedure tradizionali, dbt permette di trattare le trasformazioni dati come codice software (software engineering best practices), includendo versionamento (Git), testing e CI/CD.
Struttura del Progetto dbt
Organizziamo i modelli in tre layer logici:
- Staging (src): Pulizia leggera, rinomina colonne, casting dei tipi dati.
- Intermediate (int): Logica di business complessa, join tra tabelle.
- Marts (fct/dim): Tabelle finali pronte per la BI e il reporting regolatorio.
Calcolo KPI Complessi: Loan-to-Value (LTV) in SQL
Nel settore mutui, il LTV è un indicatore di rischio critico. Ecco come appare un modello dbt (file .sql) che calcola il LTV aggiornato e classifica il rischio, unendo dati anagrafici e valutazioni immobiliari.
-- models/marts/risk/fct_mortgage_risk.sql
WITH mortgages AS (
SELECT * FROM {{ ref('stg_core_mortgages') }}
),
appraisals AS (
-- Prendiamo l'ultima valutazione disponibile per l'immobile
SELECT
property_id,
appraisal_amount,
appraisal_date,
ROW_NUMBER() OVER (PARTITION BY property_id ORDER BY appraisal_date DESC) as rn
FROM {{ ref('stg_external_appraisals') }}
)
SELECT
m.mortgage_id,
m.customer_id,
m.outstanding_balance,
a.appraisal_amount,
-- Calcolo LTV: (Saldo Residuo / Valore Immobile) * 100
ROUND((m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) * 100, 2) as loan_to_value_ratio,
CASE
WHEN (m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) > 0.80 THEN 'HIGH_RISK'
WHEN (m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) BETWEEN 0.50 AND 0.80 THEN 'MEDIUM_RISK'
ELSE 'LOW_RISK'
END as risk_category,
CURRENT_TIMESTAMP() as calculated_at
FROM mortgages m
LEFT JOIN appraisals a ON m.property_id = a.property_id AND a.rn = 1
WHERE m.status = 'ACTIVE'
Data Quality e Auditabilità: Il Cuore del Fintech
In ambito finanziario, un dato errato può portare a sanzioni. L’approccio ELT con dbt eccelle nella Data Quality grazie ai test integrati.
Implementazione dei Test Automatici
Nel file schema.yml di dbt, definiamo le asserzioni che i dati devono soddisfare. Se un test fallisce, la pipeline si blocca o invia un alert, prevenendo la propagazione di dati corrotti.
version: 2
models:
- name: fct_mortgage_risk
description: "Tabella dei fatti per il rischio mutui"
columns:
- name: mortgage_id
tests:
- unique
- not_null
- name: loan_to_value_ratio
tests:
- not_null
# Custom test: LTV non può essere negativo o assurdamente alto (>200%)
- dbt_utils.expression_is_true:
expression: ">= 0 AND <= 200"
Data Lineage
dbt genera automaticamente un grafo di dipendenze (DAG). Per un auditor, questo significa poter visualizzare graficamente come il dato “Rischio Alto” di un cliente sia stato derivato: dalla tabella raw, attraverso le trasformazioni intermedie, fino al report finale. Questo livello di trasparenza è spesso obbligatorio nelle ispezioni bancarie.
Gestione dell’Infrastruttura e Versionamento
A differenza delle pipeline ETL legacy basate su GUI (interfacce grafiche drag-and-drop), l’approccio moderno è Code-First.
- Version Control (Git): Ogni modifica alla logica di calcolo del LTV è un commit su Git. Possiamo sapere chi ha cambiato la formula, quando e perché (tramite la Pull Request).
- Ambienti Isolati: Grazie a dbt, ogni sviluppatore può eseguire la pipeline in un ambiente sandbox (es.
dbt run --target dev) su un sottoinsieme di dati BigQuery, senza impattare la produzione.
Troubleshooting Comune
1. Schema Drift (Cambiamento dello schema sorgente)
Problema: Il Core Banking aggiunge una colonna alla tabella mutui e la pipeline si rompe.
Soluzione: In BigQuery, utilizzare l’opzione schema_update_options=['ALLOW_FIELD_ADDITION'] durante il caricamento. In dbt, utilizzare pacchetti come dbt_utils.star per selezionare dinamicamente le colonne o implementare test di schema rigorosi che avvisano del cambiamento senza rompere il flusso critico.
2. Latenza dei Dati
Problema: I dati delle valutazioni immobiliari arrivano in ritardo rispetto ai saldi dei mutui.
Soluzione: Implementare la logica di “Late Arriving Facts”. Utilizzare le Window Functions di SQL (come visto nell’esempio sopra con ROW_NUMBER) per prendere sempre l’ultimo dato valido disponibile al momento dell’esecuzione, oppure modellare tabelle snapshot per storicizzare lo stato esatto a fine mese.
Conclusioni

La transizione da una pipeline etl vs elt nel settore Fintech non è una moda, ma una necessità operativa. L’utilizzo di BigQuery per lo storage a basso costo e l’alta capacità computazionale, combinato con dbt per la governance delle trasformazioni, permette alle aziende finanziarie di avere dati affidabili, auditabili e tempestivi. Implementare questa architettura richiede competenze di software engineering applicate ai dati, ma il ritorno sull’investimento in termini di compliance e agilità di business è incalcolabile.
Domande frequenti

La distinzione principale riguarda il momento della trasformazione dei dati. Nel modello ETL i dati vengono elaborati prima del caricamento, mentre nel paradigma ELT i dati grezzi vengono caricati subito nel Data Warehouse e trasformati successivamente. Nel Fintech il metodo ELT è preferito poiché garantisce la totale auditabilità e consente di ricalcolare i KPI storici senza rieseguire la estrazione dai sistemi sorgente.
Questa combinazione costituisce lo standard attuale grazie alla scalabilità serverless di Google BigQuery e alla capacità di dbt di gestire le trasformazioni SQL come codice software. Il loro utilizzo congiunto permette di sfruttare la potenza di calcolo del cloud per elaborare massicci volumi di dati finanziari, assicurando al contempo versionamento, testing automatico e una documentazione chiara della logica di business.
Il modello ELT facilita la compliance conservando i dati grezzi originali nel Data Warehouse, rendendo possibile ricostruire la storia di ogni transazione in qualsiasi momento. Inoltre, strumenti come dbt generano automaticamente un grafo di dipendenze, noto come Data Lineage, che consente agli auditor di visualizzare esattamente come un dato finale sia stato derivato dalla fonte durante le ispezioni normative.
La integrità del dato viene assicurata tramite test automatici integrati nel codice di trasformazione, i quali verificano unicità e coerenza dei valori. Definendo regole specifiche nel file di configurazione, la pipeline può bloccare il processo o inviare avvisi immediati se rileva anomalie, prevenendo la propagazione di errori nei report decisionali o regolatori.
Il calcolo di indicatori di rischio viene gestito attraverso modelli SQL modulari dentro il Data Warehouse, unendo anagrafiche e valutazioni immobiliari. Grazie al metodo ELT è possibile implementare logiche che storicizzano il rischio e gestiscono i ritardi dei dati, assicurando che il calcolo rifletta sempre la informazione più valida e aggiornata disponibile al momento della esecuzione.
Fonti e Approfondimenti

- Definizione e confronto dei processi di integrazione dati ETL ed ELT su Wikipedia
- Banca d’Italia – Disposizioni di vigilanza per le banche (Circolare n. 285) su controlli interni e rischi
- Panoramica tecnica e storia della piattaforma di orchestrazione Apache Airflow su Wikipedia
- Autorità Bancaria Europea (EBA) – Linee guida sulla gestione dei rischi ICT e di sicurezza

Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.