In Breve (TL;DR)
L’architettura RAG potenzia i CRM finanziari consultando normative e dati clienti in tempo reale per generare risposte accurate e prive di allucinazioni.
La pipeline tecnica integra ingestion semantica, database vettoriali e prompt engineering per trasformare documenti complessi in consulenze finanziarie sicure e totalmente tracciabili.
L’uso strategico di pgvector e chunking avanzato permette di costruire assistenti virtuali capaci di pre-qualificare lead e gestire mutui garantendo la compliance.
Il diavolo è nei dettagli. 👇 Continua a leggere per scoprire i passaggi critici e i consigli pratici per non sbagliare.
Siamo nel 2026 e l’integrazione dell’Intelligenza Artificiale nei sistemi aziendali non è più una novità, ma uno standard operativo. Tuttavia, nel settore fintech e immobiliare, la sfida non è solo generare testo, ma generare risposte accurate, tracciabili e conformi. È qui che entra in gioco l’architettura RAG nel CRM (Retrieval-Augmented Generation). A differenza di un LLM generico che si basa solo sul suo training set (spesso datato), un sistema RAG permette al vostro CRM proprietario (come BOMA o soluzioni custom) di consultare in tempo reale la documentazione normativa, i tassi di interesse attuali e lo storico del cliente prima di formulare una risposta.
In questo deep dive tecnico, esploreremo come costruire un assistente finanziario intelligente capace di pre-qualificare lead e fornire consulenza sui mutui, minimizzando le allucinazioni e garantendo la massima sicurezza dei dati.

L’Architettura RAG nel Contesto Finanziario
L’implementazione della RAG nel CRM richiede una pipeline robusta composta da tre fasi principali: Ingestion (preparazione dei dati), Retrieval (recupero semantico) e Generation (sintesi della risposta). Nel contesto di un CRM finanziario, i dati non sono solo testo libero, ma una combinazione di:
- Dati Non Strutturati: PDF di normative bancarie, policy di credito, trascrizioni di email.
- Dati Strutturati: Anagrafiche clienti, scoring creditizio, tassi LTV (Loan-to-Value) presenti nel database SQL.
L’obiettivo è trasformare questi dati in vettori numerici (embedding) che l’LLM possa “comprendere” e interrogare.
Step 1: Data Ingestion e Chunking Strategico
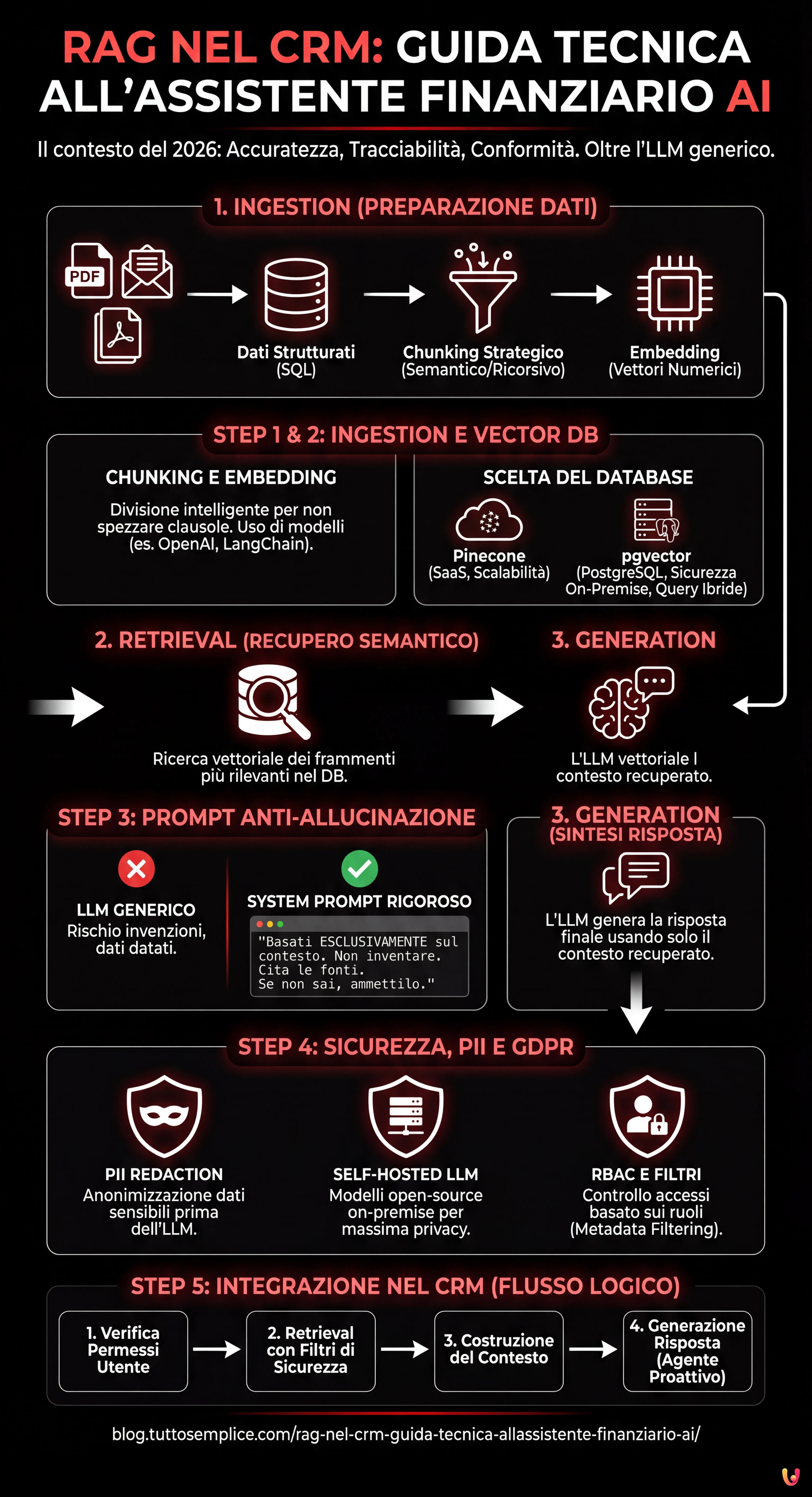
Il primo passo è la trasformazione della documentazione (es. “Guida ai Mutui 2026.pdf”) in frammenti gestibili. Non possiamo passare un intero manuale di 500 pagine nella finestra di contesto dell’LLM. Dobbiamo dividere il testo in chunks.
Per documenti finanziari, un chunking basato puramente sui caratteri è rischioso perché potrebbe spezzare una clausola legale a metà. Utilizziamo un approccio semantico o ricorsivo.
Esempio di Codice: Pipeline di Ingestion con LangChain
Ecco come implementare una funzione Python per processare i documenti e creare embedding utilizzando OpenAI (o modelli open-source equivalenti).
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
import os
# Configurazione API Key (gestita via variabili d'ambiente per sicurezza)
os.environ["OPENAI_API_KEY"] = "sk-..."
def process_financial_docs(file_path):
# 1. Caricamento del documento
loader = PyPDFLoader(file_path)
docs = loader.load()
# 2. Chunking Strategico
# Chunk size di 1000 token con overlap di 200 per mantenere il contesto tra i frammenti
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["nn", "n", " ", ""]
)
splits = text_splitter.split_documents(docs)
# 3. Creazione degli Embedding
# Utilizziamo text-embedding-3-small per un buon bilanciamento costo/performance
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
return splits, embeddingsStep 2: Scelta e Gestione del Vector Database

Una volta creati gli embedding, dove li archiviamo? La scelta del database vettoriale è critica per le performance della RAG nel CRM.
- Pinecone: Soluzione gestita (SaaS). Ottima per scalabilità e velocità, ma i dati risiedono su cloud terzi. Ideale se la policy aziendale lo permette.
- pgvector (PostgreSQL): La scelta preferita per i CRM proprietari che già usano Postgres. Permette di eseguire query ibride (es. “trova documenti simili semanticamente” AND “appartenenti al cliente ID=123”).
Se stiamo costruendo un assistente finanziario interno, pgvector offre il vantaggio di mantenere i dati vettoriali nello stesso perimetro di sicurezza dei dati finanziari strutturati.
Step 3: Retrieval e Prompt Engineering Anti-Allucinazione
Il cuore del sistema è il recupero delle informazioni pertinenti. Quando un operatore chiede al CRM: “Il cliente Rossi può accedere al Mutuo Giovani con un ISEE di 35k?”, il sistema deve recuperare le policy relative al “Mutuo Giovani” e i limiti ISEE.
Tuttavia, recuperare i dati non basta. Dobbiamo istruire l’LLM a non inventare. Questo si ottiene tramite un System Prompt rigoroso.
Esempio di Prompt Engineering Avanzato
Utilizziamo un template che forza il modello a citare le fonti o ad ammettere l’ignoranza.
SYSTEM_PROMPT = """
Sei un Assistente Finanziario Senior integrato nel CRM BOMA.
Il tuo compito è rispondere alle domande basandoti ESCLUSIVAMENTE sul contesto fornito di seguito.
REGOLE OPERATIVE:
1. Se la risposta non è presente nel contesto, devi rispondere: "Mi dispiace, le policy attuali non coprono questo caso specifico."
2. Non inventare tassi di interesse o regole non scritte.
3. Cita sempre il documento di riferimento (es. [Policy Mutui v2.4]).
4. Mantieni un tono professionale e formale.
CONTESTO:
{context}
DOMANDA UTENTE:
{question}
"""Step 4: Sicurezza, PII e Compliance GDPR
Integrare la RAG nel CRM finanziario comporta rischi enormi legati alla privacy. Non possiamo inviare dati sensibili (PII – Personally Identifiable Information) come Codici Fiscali, nomi completi o saldi bancari direttamente alle API di OpenAI o Anthropic senza precauzioni, specialmente sotto GDPR.
Strategie di Protezione (Guardrails)
- PII Redaction (Anonimizzazione): Prima di inviare il prompt all’LLM, utilizzare librerie come Microsoft Presidio per identificare e mascherare i dati sensibili. “Mario Rossi” diventa “<PERSON>”.
- Self-Hosted LLM: Per la massima sicurezza, valutare l’uso di modelli open-source come Llama 3 o Mistral, ospitati su server proprietari (on-premise o VPC privata). Questo garantisce che nessun dato lasci mai l’infrastruttura aziendale.
- Role-Based Access Control (RBAC): Il sistema RAG deve rispettare i permessi del CRM. Un agente junior non deve poter interrogare vettori relativi a documenti riservati della direzione. Questo filtro va applicato a livello di query sul database vettoriale (Metadata Filtering).
Step 5: Orchestrazione e Integrazione nel CRM
L’ultimo tassello è l’integrazione nel frontend del CRM. L’assistente non deve essere solo una chat, ma un agente proattivo. Ecco un esempio logico di come strutturare la chiamata:
def get_crm_answer(user_query, user_id):
# 1. Verifica permessi utente
user_permissions = db.get_permissions(user_id)
# 2. Recupero documenti pertinenti (Retrieval) con filtri di sicurezza
docs = vector_store.similarity_search(
user_query,
k=3,
filter={"access_level": {"$in": user_permissions}}
)
# 3. Costruzione del contesto
context_text = "nn".join([d.page_content for d in docs])
# 4. Generazione Risposta (Generation)
response = llm_chain.invoke({"context": context_text, "question": user_query})
return responseConclusioni: Il Futuro del CRM Finanziario
Implementare la RAG nel CRM trasforma un database statico in un consulente dinamico. Per le istituzioni finanziarie, questo significa ridurre i tempi di onboarding dei nuovi dipendenti (che hanno accesso istantaneo a tutta la knowledge base aziendale) e garantire che ogni risposta data al cliente sia conforme alle ultime normative vigenti.
La chiave del successo non risiede nel modello più potente, ma nella qualità della pipeline di dati e nella rigidità dei protocolli di sicurezza. Nel 2026, la fiducia è l’asset più prezioso, e un’architettura RAG ben progettata è lo strumento migliore per preservarla.
Domande frequenti

Mentre un LLM generico si basa su dati di addestramento statici e spesso datati, un’architettura RAG (Retrieval-Augmented Generation) integrata nel CRM permette di consultare in tempo reale documenti aziendali, tassi di interesse attuali e storico clienti. Questo approccio garantisce risposte basate su dati proprietari aggiornati, riducendo il rischio di informazioni obsolete e migliorando la conformità normativa nelle consulenze finanziarie.
La protezione dei dati personali avviene attraverso diverse strategie difensive. È essenziale applicare tecniche di PII Redaction per anonimizzare nomi e codici fiscali prima che raggiungano il modello AI. Inoltre, l’uso di modelli open-source ospitati su server proprietari e l’implementazione di controlli di accesso basati sui ruoli (RBAC) assicurano che le informazioni sensibili non lascino mai l’infrastruttura aziendale e siano accessibili solo al personale autorizzato.
Per documenti legali e finanziari, la divisione del testo basata puramente sui caratteri è sconsigliata poiché rischia di spezzare clausole importanti. La strategia ottimale prevede un chunking semantico o ricorsivo, che mantiene uniti i paragrafi logici e utilizza un sistema di sovrapposizione (overlap) tra i frammenti. Questo metodo preserva il contesto necessario affinché l’intelligenza artificiale possa interpretare correttamente le normative durante la fase di recupero.
L’utilizzo di pgvector su PostgreSQL è spesso preferibile per i CRM proprietari perché permette di mantenere i dati vettoriali (embedding) nello stesso perimetro di sicurezza dei dati strutturati dei clienti. A differenza delle soluzioni SaaS esterne, questa configurazione facilita l’esecuzione di query ibride che combinano la ricerca semantica con filtri SQL tradizionali, offrendo un controllo maggiore sulla privacy e riducendo la latenza di rete.
Il Prompt Engineering avanzato agisce come un filtro di sicurezza istruendo il modello a basarsi esclusivamente sul contesto fornito. Attraverso un System Prompt rigoroso, si impone all’assistente di citare le fonti documentali specifiche per ogni affermazione e di ammettere esplicitamente l’ignoranza se la risposta non è presente nelle policy aziendali, impedendo così la generazione di tassi o regole finanziarie inesistenti.
Fonti e Approfondimenti


Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.