Pe Scurt (TL;DR)
Automatizarea prin NLP transformă calificarea lead-urilor imobiliare, depășind formularele statice pentru a extrage date precise din conversații naturale.
Fine-tuning-ul modelelor BERT italiene permite crearea de sisteme NER personalizate capabile să identifice sume, profesii și tipologii imobiliare.
Normalizarea datelor extrase și integrarea directă în CRM-ul BOMA optimizează calculul ratingului de credit și gestiunea comercială.
Diavolul se ascunde în detalii. 👇 Continuă să citești pentru a descoperi pașii critici și sfaturile practice pentru a nu greși.
În peisajul competitiv din 2026, viteza de răspuns nu mai este singurul factor determinant în sectorul creditelor și al imobiliarelor. Adevărata provocare constă în precizie și în capacitatea de a filtra zgomotul. Calificarea lead-urilor imobiliare a trecut de la a fi o sarcină manuală efectuată de call center-uri la un proces automatizat ghidat de algoritmi de Procesare a Limbajului Natural (NLP). În acest ghid tehnic, vom explora cum să construim un sistem de Named Entity Recognition (NER) personalizat pentru a extrage date structurate din conversații nestructurate și a le integra direct în CRM-ul BOMA.

De ce Extragerea Entităților schimbă Calificarea Lead-urilor Imobiliare
Formularele statice de pe site-uri (Nume, Prenume, Telefon) au rate de conversie din ce în ce mai mici. Utilizatorii preferă să interacționeze prin chat-uri naturale sau mesaje vocale. Totuși, acest lucru generează date nestructurate dificil de procesat. Aici intervine Extragerea Semantică a Entităților.
Obiectivul nu este doar înțelegerea intenției (ex. “vreau un credit”), ci extragerea unor sloturi specifice de informații necesare pentru calculul ratingului de credit sau fezabilitatea achiziției. Un sistem bine proiectat trebuie să identifice:
- ENT_AMOUNT: Suma solicitată (ex. “am nevoie de 200k”).
- ENT_LTV: Loan-to-Value implicit sau valoarea imobilului.
- ENT_JOB_TYPE: Tipul contractului (ex. “nedeterminat”, “PFA”).
- ENT_PROPERTY: Tipul imobilului și clasa energetică.
Cerințe preliminare și Stack Tehnologic
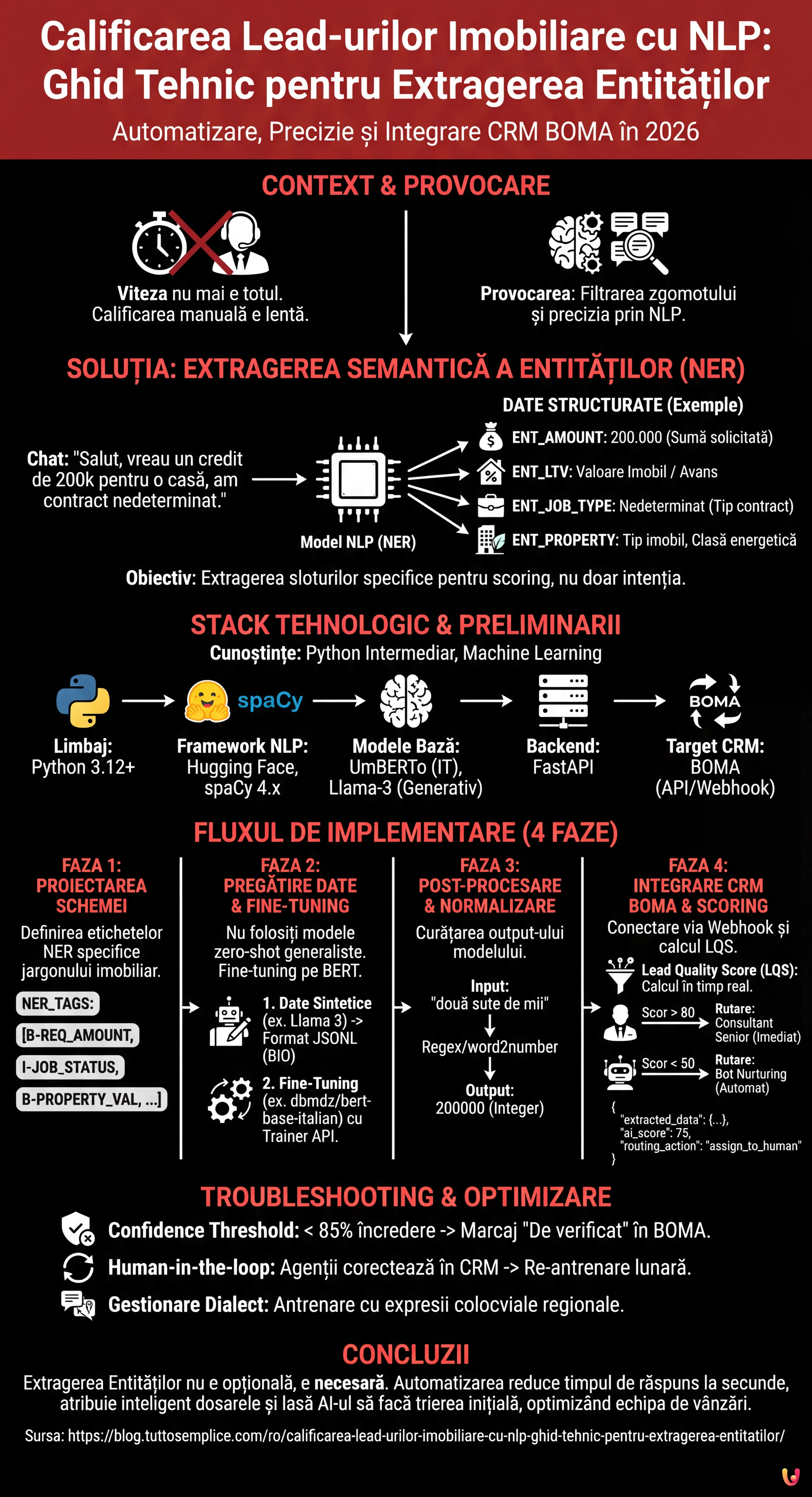
Pentru a urma acest ghid, este necesară o cunoaștere intermediară de Python și a principiilor de Machine Learning. Vom utiliza următorul stack, standardizat pentru 2026:
- Limbaj: Python 3.12+
- Framework NLP: Hugging Face Transformers, spaCy 4.x
- Modele de Bază:
UmBERTo(pentru italiană) sau versiuni cuantizate deLlama-3-8B-Instructpentru sarcini generative. - Backend: FastAPI pentru expunerea modelului.
- Target CRM: BOMA (prin API REST/Webhook).
Faza 1: Proiectarea Schemei Entităților

Înainte de a scrie cod, trebuie să definim ce trebuie să caute modelul nostru. În contextul creditelor ipotecare, jargonul este specific. Un model generic ar eșua în a distinge între “avans” și “rată”.
Definim etichetele pentru setul nostru de date de antrenament:
NER_TAGS = [
"O", # Outside (nicio entitate)
"B-REQ_AMOUNT", # Început sumă solicitată
"I-REQ_AMOUNT", # Interior sumă solicitată
"B-JOB_STATUS", # Început statut profesional
"I-JOB_STATUS", # Interior statut profesional
"B-PROPERTY_VAL", # Valoare imobil
"B-INTENT_TIME" # Timp dorit (ex. "contract până în martie")
]
Faza 2: Pregătirea Setului de Date și Fine-Tuning
Pentru a obține o calificare a lead-urilor imobiliare precisă, nu ne putem baza pe modele generaliste zero-shot pentru extragerea masivă, deoarece sunt costisitoare și lente. Cea mai bună soluție este fine-tuning-ul unui model bazat pe BERT.
1. Crearea Setului de Date Sintetic
Dacă nu dispuneți de istorice de chat conforme cu GDPR, puteți genera un set de date sintetic utilizând un LLM (precum Meta AI Llama 3) pentru a crea mii de variații de fraze tipice:
“Sunt angajat la stat și caut un credit pentru o casă de 250.000 euro, am 50k avans.”
Adnotați aceste fraze în formatul JSONL standard pentru antrenament (format BIO).
2. Fine-Tuning cu Hugging Face
Vom utiliza dbmdz/bert-base-italian-xxl-cased ca bază, fiind unul dintre cele mai performante modele pe sintaxa italiană (adaptabil pentru contextul specific). Iată un snippet simplificat pentru bucla de antrenament:
from transformers import AutoTokenizer, AutoModelForTokenClassification, TrainingArguments, Trainer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=len(NER_TAGS))
args = TrainingArguments(
output_dir="./boma-ner-v1",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
num_train_epochs=5,
weight_decay=0.01,
)
# Presupunând că 'tokenized_datasets' este deja pregătit
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
)
trainer.train()
Acest proces adaptează ponderile modelului pentru a recunoaște specific termeni precum “refinanțare”, “rată fixă” sau “consultant” în contextul frazei.
Faza 3: Post-procesare și Normalizare
Modelul NER returnează token-uri și etichete. Pentru calificarea lead-urilor imobiliare, trebuie să transformăm "două sute de mii de euro" în 200000 (Integer). Această fază de normalizare este critică pentru popularea bazei de date.
Utilizăm biblioteci precum word2number sau regex personalizate pentru a curăța output-ul modelului înainte de trimiterea către CRM.
Faza 4: Integrarea în CRM-ul BOMA
Odată ce modelul este expus via API (ex. pe un container Docker), trebuie să îl conectăm la fluxul de intrare a lead-urilor. Integrarea cu BOMA se face de obicei prin webhook-uri care se declanșează la primirea unui nou mesaj.
Logica de Scoring și Rutare
Nu toate lead-urile sunt egale. Utilizând datele extrase, putem calcula un Lead Quality Score (LQS) în timp real:
- Lead A (Scor 90/100): Date complete (Job, Sumă, Imobil), LTV Rutare imediată către Senior Consultant.
- Lead B (Scor 40/100): Date parțiale, LTV > 95%, Contract Determinat. -> Rutare către Bot-ul automat de Nurturing.
Iată un exemplu de payload JSON de trimis către API-urile BOMA:
{
"lead_source": "Whatsapp_Business",
"message_body": "Salut, aș dori info pentru credit prima casă, sunt asistent medical",
"extracted_data": {
"job_type": "asistent medical",
"job_category": "sector_public",
"intent": "achizitie_prima_casa"
},
"ai_score": 75,
"routing_action": "assign_to_human"
}
Troubleshooting: Gestionarea Halucinațiilor și a Ambiguității
Chiar și cele mai bune modele pot greși. Iată cum să atenuați riscurile:
- Confidence Threshold: Dacă modelul extrage o entitate cu o încredere mai mică de 85%, sistemul trebuie să marcheze câmpul ca “De verificat” în CRM-ul BOMA, solicitând intervenția umană.
- Human-in-the-loop: Implementați un mecanism de feedback unde agenții imobiliari pot corecta etichetarea în CRM. Aceste date corectate trebuie să reintre în setul de date de antrenament pentru re-antrenarea lunară a modelului.
- Gestionarea Dialectului: Antrenați modelul pe seturi de date care includ expresii colocviale regionale folosite adesea în chat-urile informale.
Concluzii

Implementarea unui sistem de Extragere a Entităților pentru calificarea lead-urilor imobiliare nu mai este un exercițiu academic, ci o necesitate operațională. Automatizând extragerea datelor critice (LTV, job, buget) și integrându-le direct în BOMA, agențiile pot reduce timpul primului contact de la ore la secunde, atribuind dosarele cele mai complexe celor mai buni consultanți și lăsând AI-ului gestionarea trierii inițiale.
Întrebări frecvente

Este un proces bazat pe NLP care identifică și extrage date specifice, cum ar fi suma creditului sau tipul de contract, din conversații naturale și nestructurate. Spre deosebire de formularele statice, această tehnologie permite înțelegerea intenției utilizatorului și popularea automată a câmpurilor necesare pentru calculul ratingului de credit direct în CRM.
Pentru a obține performanțe ridicate pe sintaxa italiană, cea mai bună alegere este fine-tuning-ul modelelor bazate pe BERT, precum UmBERTo sau dbmdz bert-base-italian. Aceste modele sunt superioare soluțiilor generaliste zero-shot deoarece pot fi antrenate să recunoască jargonul specific sectorului de creditare, distingând termeni tehnici precum «rată», «avans» sau «refinanțare».
Integrând un model de extragere a entităților prin API sau Webhook, BOMA poate primi date deja curățate și normalizate. Acest lucru permite atribuirea unui scor de calitate lead-ului în timp real și rutarea automată a contactelor: profilurile complete merg la consultanții seniori, în timp ce cele parțiale sunt gestionate de boți de nurturing, optimizând timpul echipei de vânzări.
Un sistem bine proiectat extrage entități critice precum suma solicitată, valoarea imobilului pentru calculul Loan-to-Value, tipul contractului de muncă și clasa energetică a casei. Aceste date, definite ca sloturi informaționale, sunt esențiale pentru a determina imediat fezabilitatea dosarului fără interviuri preliminare lungi.
Este necesară implementarea unui prag de încredere, de exemplu la 85 la sută, sub care sistemul semnalează data ca fiind de verificat manual. În plus, se adoptă o abordare human-in-the-loop unde corecțiile aduse de agenții imobiliari sunt salvate și reutilizate pentru re-antrenarea periodică a modelului, îmbunătățindu-i precizia în timp.

Ați găsit acest articol util? Există un alt subiect pe care ați dori să-l tratez?
Scrieți-l în comentariile de mai jos! Mă inspir direct din sugestiile voastre.