Pe Scurt (TL;DR)
Paradigma Data Lakehouse modernizează scorul de credit unificând gestionarea datelor structurate și nestructurate într-o singură infrastructură scalabilă.
Extragerea valorii din surse eterogene precum documente și jurnale are loc prin pipeline-uri NLP avansate care transformă informațiile brute în feature-uri predictive.
Arhitectura stratificată integrată cu Feature Store garantează guvernanța datelor și alinierea între antrenarea modelelor și inferența în timp real.
Diavolul se ascunde în detalii. 👇 Continuă să citești pentru a descoperi pașii critici și sfaturile practice pentru a nu greși.
În peisajul fintech din 2026, capacitatea de a evalua riscul de credit nu mai depinde doar de istoricul plăților sau de soldul contului curent. Frontiera modernă este data lakehouse credit scoring, o abordare arhitecturală care depășește dihotomia dintre Data Warehouse (excelente pentru date structurate) și Data Lake (necesare pentru date nestructurate). Acest ghid tehnic explorează modul de proiectare a unei infrastructuri capabile să ingereze, să proceseze și să servească date eterogene pentru a alimenta modele de Machine Learning de nouă generație.

Evoluția Credit Scoring-ului: Dincolo de Datele Tabelare
În mod tradițional, scorul de credit se baza pe modele de regresie logistică alimentate de date rigid structurate provenite din sistemele Core Banking. Totuși, această abordare ignoră o mină de aur de informații: datele nestructurate. E-mailurile de asistență, jurnalele de chat, documentele PDF de bilanț și chiar metadatele de navigare oferă semnale predictive cruciale despre stabilitatea financiară a unui client sau despre predispoziția acestuia la abandon (churn).
Paradigma Data Lakehouse apare ca soluția definitivă. Prin îmbinarea flexibilității stocării la costuri reduse (precum Amazon S3 sau Google Cloud Storage) cu capacitățile tranzacționale și de gestionare a metadatelor tipice Warehouse-urilor (prin tehnologii precum Delta Lake, Apache Iceberg sau Apache Hudi), este posibilă crearea unei Single Source of Truth pentru scorul de credit avansat.
Arhitectură de Referință pentru Credit Scoring 2.0
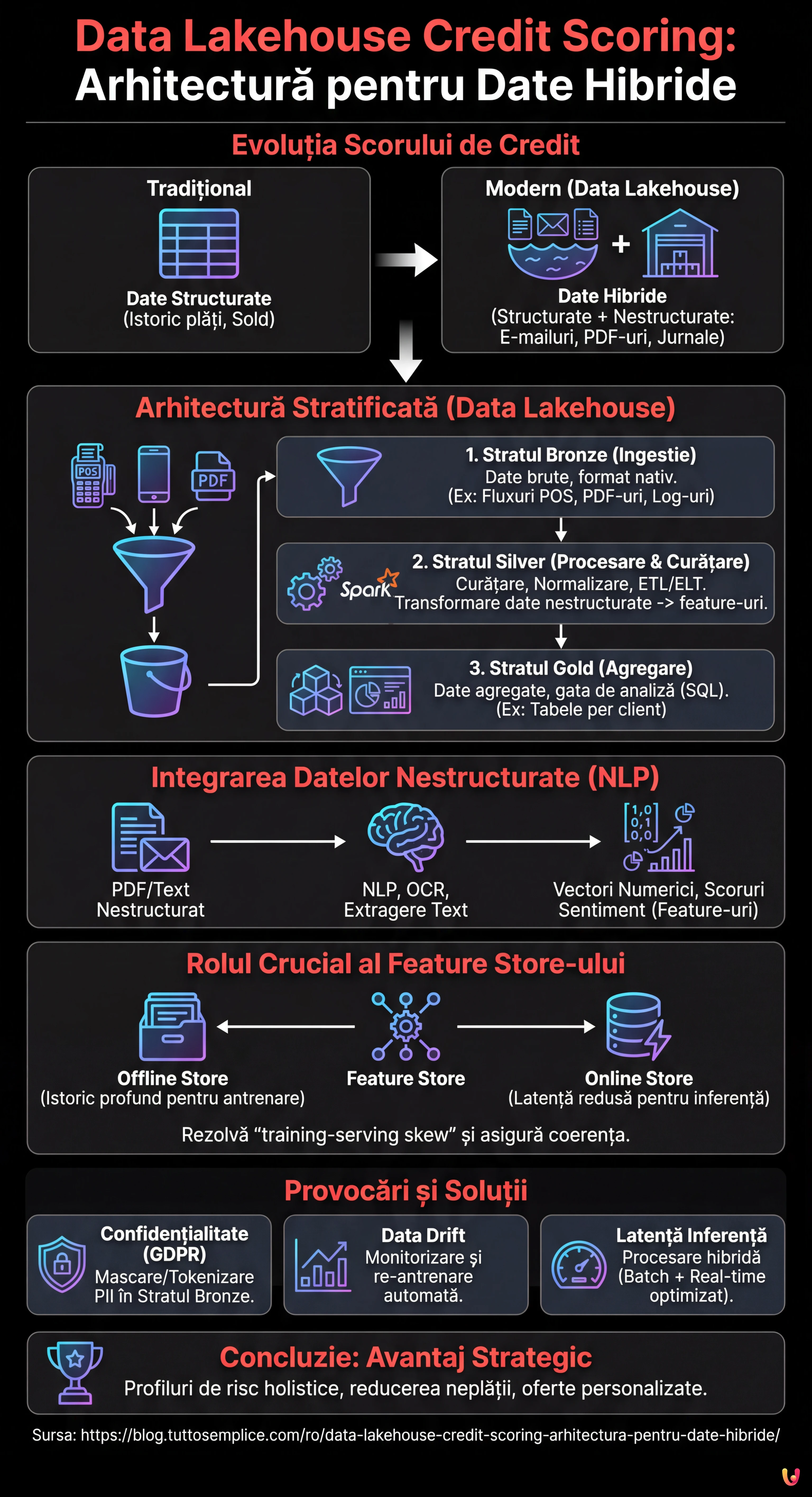
Pentru a construi un sistem eficient, trebuie să conturăm o arhitectură stratificată care să garanteze scalabilitatea și guvernanța. Iată componentele fundamentale:
1. Stratul de Ingestie (Bronze Layer)
Datele ajung în Lakehouse în formatul lor nativ. Într-un scenariu de credit scoring, vom avea:
- Fluxuri în timp real: Tranzacții POS, clickstream din aplicația mobilă (via Apache Kafka sau Amazon Kinesis).
- Batch: Exporturi zilnice din CRM, rapoarte de la agenții de credit externe.
- Nestructurate: PDF-uri cu fluturași de salariu, e-mailuri, înregistrări call center.
2. Stratul de Procesare și Curățare (Silver Layer)
Aici are loc magia ETL/ELT. Utilizând motoare distribuite precum Apache Spark sau servicii gestionate precum AWS Glue, datele sunt curățate, deduplicate și normalizate. În această fază datele nestructurate sunt transformate în feature-uri utilizabile.
3. Stratul de Agregare (Gold Layer)
Datele sunt gata pentru consumul de business și pentru analiză, organizate în tabele agregate per client, gata pentru a fi interogate via SQL (ex. Athena, BigQuery sau Databricks SQL).
Integrarea Datelor Nestructurate: Provocarea NLP

Adevărata inovație în data lakehouse credit scoring constă în extragerea de feature-uri din text și imagini. Nu putem introduce un PDF într-un model XGBoost, deci trebuie să îl procesăm în Silver Layer.
Să presupunem că vrem să analizăm e-mailurile schimbate cu serviciul clienți pentru a detecta semnale de stres financiar. Procesul prevede:
- OCR și Text Extraction: Utilizarea de biblioteci precum Tesseract sau servicii cloud (AWS Textract) pentru a converti PDF/Imagini în text.
- NLP Pipeline: Aplicarea de modele Transformer (ex. BERT finetuned pentru domeniul financiar) pentru a extrage entități (NER) sau a analiza sentimentul.
- Feature Vectorization: Conversia rezultatului în vectori numerici sau scoruri categorice (ex. “Sentiment_Score_Last_30_Days”).
Rolul Crucial al Feature Store-ului
Una dintre problemele cele mai comune în MLOps este training-serving skew: feature-urile calculate în timpul antrenării modelului diferă de cele calculate în timp real în timpul inferenței (când clientul solicită un împrumut din aplicație). Pentru a rezolva această problemă, arhitectura Lakehouse trebuie să integreze un Feature Store (precum Feast, Hopsworks sau SageMaker Feature Store).
Feature Store-ul gestionează două vizualizări:
- Offline Store: Bazat pe Data Lakehouse, conține istoricul profund pentru antrenarea modelelor.
- Online Store: O bază de date cu latență redusă (ex. Redis sau DynamoDB) care servește ultima valoare cunoscută a feature-urilor pentru inferența în timp real.
Exemplu Practic: Pipeline ETL cu PySpark
Mai jos este un exemplu conceptual despre cum un job Spark ar putea uni date tranzacționale structurate cu scoruri de sentiment derivate din date nestructurate în cadrul unei arhitecturi Delta Lake.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, current_timestamp
# Inițializare Spark cu suport Delta Lake
spark = SparkSession.builder
.appName("CreditScoringETL")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
# 1. Încărcare Date Structurate (Tranzacții)
df_transactions = spark.read.format("delta").load("s3://datalake/silver/transactions")
# Feature Engineering: Media tranzacționată în ultimele 30 de zile
feat_avg_spend = df_transactions.groupBy("customer_id")
.agg(avg("amount").alias("avg_monthly_spend"))
# 2. Încărcare Date Nestructurate Procesate (Log Chat/Email)
# Presupunem că un pipeline NLP anterior a salvat scorurile de sentiment
df_sentiment = spark.read.format("delta").load("s3://datalake/silver/customer_sentiment")
# Feature Engineering: Sentiment mediu
feat_sentiment = df_sentiment.groupBy("customer_id")
.agg(avg("sentiment_score").alias("avg_sentiment_risk"))
# 3. Join pentru a crea Setul de Feature-uri Unificat
final_features = feat_avg_spend.join(feat_sentiment, "customer_id", "left_outer")
.fillna({"avg_sentiment_risk": 0.5}) # Gestionare valori nule
# 4. Scriere în Feature Store (Offline Layer)
final_features.write.format("delta")
.mode("overwrite")
.save("s3://datalake/gold/credit_scoring_features")
print("Pipeline finalizat: Feature Store actualizat.")
Depanare și Cele Mai Bune Practici
În implementarea unui sistem de data lakehouse credit scoring, este obișnuit să întâmpinați obstacole specifice. Iată cum să le atenuați:
Gestionarea Confidențialității (GDPR/CCPA)
Datele nestructurate conțin adesea PII (Personally Identifiable Information) sensibile. Este imperativ să implementați tehnici de mascare sau tokenizare în Bronze Layer, înainte ca datele să devină accesibile pentru Data Scientists. Instrumente precum Presidio de la Microsoft pot automatiza anonimizarea textului.
Data Drift
Comportamentul clienților se schimbă. Un model antrenat pe datele din 2024 ar putea să nu fie valid în 2026. Monitorizarea distribuției statistice a feature-urilor în Feature Store este esențială pentru a activa re-antrenarea automată a modelelor.
Latența în Inferență
Dacă calculul feature-urilor nestructurate (ex. analiza unui PDF încărcat pe moment) este prea lent, experiența utilizatorului are de suferit. În aceste cazuri, se recomandă o arhitectură hibridă: pre-calcularea a tot ce este posibil în batch (istoric) și utilizarea de modele NLP ușoare și optimizate (ex. DistilBERT pe ONNX) pentru procesarea în timp real.
Concluzii

Adoptarea unei abordări Data Lakehouse pentru scorul de credit nu este doar o actualizare tehnologică, ci un avantaj competitiv strategic. Prin centralizarea datelor structurate și nestructurate și garantarea coerenței acestora printr-un Feature Store, instituțiile financiare pot construi profiluri de risc holistice, reducând neplata și personalizând oferta pentru client. Cheia succesului constă în calitatea pipeline-ului de inginerie a datelor: un model AI este la fel de valid precum datele care îl alimentează.
Întrebări frecvente

Data Lakehouse Credit Scoring este un model arhitectural hibrid care depășește limitele Data Warehouse-urilor tradiționale, unind gestionarea datelor structurate cu flexibilitatea Data Lake-urilor. Această abordare permite fintech-urilor să exploateze surse nestructurate, precum e-mailuri și documente, pentru a calcula riscul de credit cu o precizie mai mare, reducând dependența doar de istoricul plăților.
Datele nestructurate, precum PDF-uri sau jurnale de chat, sunt prelucrate în Silver Layer prin pipeline-uri de NLP și OCR. Aceste tehnologii convertesc textul și imaginile în vectori numerici sau scoruri de sentiment, transformând informațiile calitative în feature-uri cantitative pe care modelele predictive le pot analiza pentru a evalua fiabilitatea clientului.
Feature Store-ul acționează ca un sistem central pentru a garanta coerența datelor între faza de antrenare și cea de inferență. Acesta elimină nealinierea cunoscută sub numele de training-serving skew, menținând două vizualizări sincronizate: un Offline Store pentru istoricul profund și un Online Store cu latență redusă pentru a furniza date actualizate în timp real în timpul cererilor de credit.
Infrastructura se organizează în trei stadii principale: Bronze Layer pentru ingestia datelor brute, Silver Layer pentru curățare și îmbogățire prin algoritmi de procesare, și Gold Layer unde datele sunt agregate și gata pentru utilizarea de business. Această structură stratificată asigură scalabilitatea, guvernanța și calitatea datelor pe tot parcursul ciclului de viață.
Protecția informațiilor personale are loc prin implementarea tehnicilor de mascare și tokenizare direct în nivelul de ingestie, Bronze Layer. Utilizând instrumente specifice pentru anonimizarea automată, este posibilă analizarea comportamentelor și tendințelor din datele nestructurate fără a expune identitățile clienților sau a încălca reglementări precum GDPR.
Surse și Aprofundare


Ați găsit acest articol util? Există un alt subiect pe care ați dori să-l tratez?
Scrieți-l în comentariile de mai jos! Mă inspir direct din sugestiile voastre.