Pe Scurt (TL;DR)
Arhitectura Data Lakehouse unifică datele structurate și documentele complexe precum PDF-urile într-un singur mediu cloud performant și economic.
BigQuery și Document AI permit interogarea fișierelor brute via SQL, transformând procesele manuale în pipeline-uri automatizate și inteligente.
Această strategie valorifică Dark Data financiare, oferind CTO-urilor o gestionare unificată pentru analize predictive și operaționale în timp real.
Diavolul se ascunde în detalii. 👇 Continuă să citești pentru a descoperi pașii critici și sfaturile practice pentru a nu greși.
În peisajul financiar actual, și în special în sectorul ipotecar, adevărata valoare nu rezidă doar în bazele de date structurate, ci într-o mină de aur adesea neutilizată: documentele nestructurate. Fluturașii de salariu, evaluările imobiliare, actele notariale și documentele de identitate constituie ceea ce este adesea definit ca Dark Data. Provocarea pentru CTO și Arhitecții de Date în 2026 nu mai este doar arhivarea acestor fișiere, ci transformarea lor în date interogabile în timp real, alături de datele tranzacționale.
În acest articol tehnic, vom explora modul de proiectare și implementare a unei arhitecturi data lakehouse google cloud capabile să elimine silozurile dintre data lake (unde se află PDF-urile) și data warehouse (unde se află datele CRM). Vom utiliza puterea BigQuery, inteligența Document AI și capacitățile predictive ale Vertex AI pentru a transforma un proces de analiză manuală într-un pipeline automatizat și sigur.

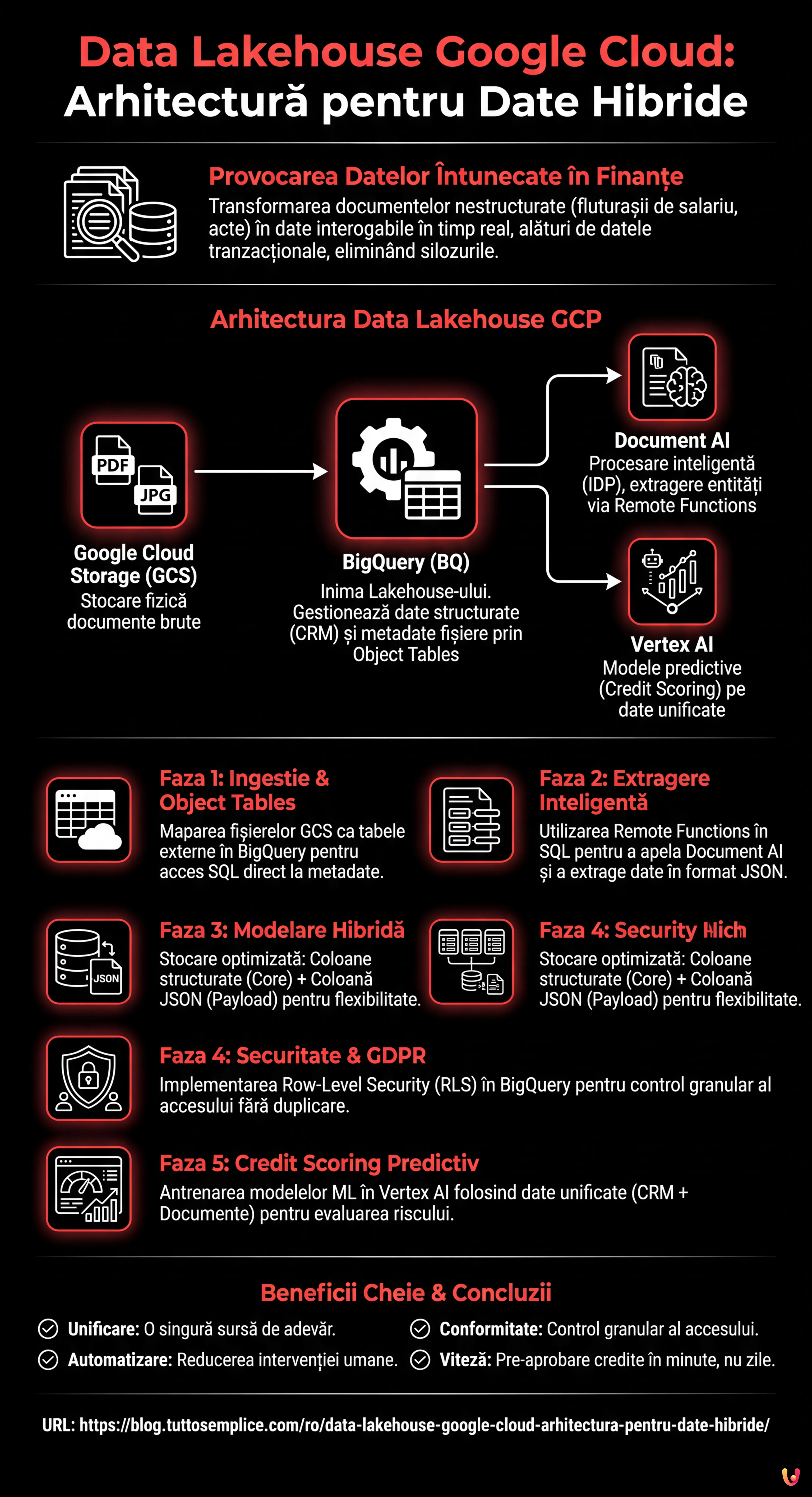
Paradigma Data Lakehouse în Fintech
În mod tradițional, băncile mențineau două stive separate: un Data Lake (ex. Google Cloud Storage) pentru fișierele brute și un Data Warehouse (ex. baze de date SQL legacy sau primele MPP) pentru Business Intelligence. Această abordare implica duplicarea datelor, latență ridicată și nealinierea informațiilor.
Data Lakehouse pe Google Cloud Platform (GCP) rezolvă această problemă permițând tratarea fișierelor arhivate în stocarea de obiecte ca și cum ar fi tabele ale unei baze de date relaționale, menținând totodată costurile reduse de stocare și performanțele ridicate ale warehouse-ului.
Componente Cheie ale Arhitecturii
- Google Cloud Storage (GCS): Nivelul de stocare fizică pentru documente (PDF, JPG, TIFF).
- BigQuery (BQ): Inima Lakehouse-ului. Gestionează atât datele structurate (CRM), cât și metadatele fișierelor nestructurate prin Object Tables.
- Document AI: Serviciul de procesare inteligentă a documentelor (IDP) pentru extragerea entităților cheie.
- Vertex AI: Pentru antrenarea modelelor de credit scoring bazate pe date unificate.
Faza 1: Designul Arhitecturii și Ingestia
Primul pas pentru a construi un data lakehouse google cloud eficient este structurarea corectă a nivelului de ingestie. Nu încărcăm pur și simplu fișiere; pregătim terenul pentru analiză.
Configurarea Object Tables în BigQuery
Începând cu actualizările recente ale GCP, BigQuery permite crearea de Object Tables. Acestea sunt tabele doar pentru citire care mapează fișierele prezente într-un bucket GCS. Acest lucru ne permite să vedem PDF-urile fluturașilor de salariu direct în BigQuery fără a le muta.
CREATE OR REPLACE EXTERNAL TABLE `fintech_lakehouse.raw_documents`
WITH CONNECTION `us.my-connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://mutui-docs-bucket/*.pdf']
);Cu această singură instrucțiune SQL, am făcut arhiva noastră documentară accesibilă via SQL. Putem interoga metadatele (data creării, dimensiunea, numele fișierului) ca și cum ar fi coloane structurate.
Faza 2: Extragere Inteligentă cu Document AI și Remote Functions

Listarea fișierelor în BigQuery nu este suficientă. Trebuie să le citim conținutul. Aici intervine integrarea dintre BigQuery și Document AI prin intermediul Remote Functions (Funcții la Distanță).
În loc să construim pipeline-uri ETL complexe cu Dataflow sau scripturi Python externe, putem invoca modelul de extragere direct dintr-o interogare SQL. Să ne imaginăm că trebuie să extragem “Venitul Net” și “Angajatorul” din fluturașii de salariu.
1. Crearea Procesorului Document AI
În consola GCP, configurăm un procesor Lending Document Splitter & Parser (specific pentru sectorul ipotecar) sau un procesor Custom Extractor antrenat pe fluturașii de salariu specifici.
2. Implementarea Remote Function
Creăm o Cloud Function (Gen 2) care acționează ca o punte. Această funcție primește URI-ul fișierului din BigQuery, apelează API-ul Document AI și returnează un obiect JSON cu entitățile extrase.
3. Extragere via SQL
Acum putem îmbogăți datele noastre brute transformându-le în informații structurate:
CREATE OR REPLACE TABLE `fintech_lakehouse.extracted_income_data` AS
SELECT
uri,
remote_functions.extract_entities(uri) AS json_data
FROM
`fintech_lakehouse.raw_documents`
WHERE
content_type = 'application/pdf';Rezultatul este un tabel care conține link-ul către documentul original și o coloană JSON cu datele extrase. Aceasta este adevărata putere a data lakehouse google cloud: date nestructurate convertite în structurate on-the-fly.
Faza 3: Modelarea Datelor și Optimizarea Schemei
Odată extrase datele, cum trebuie să le stocăm? În contextul creditelor ipotecare, flexibilitatea este fundamentală, dar performanța interogărilor este prioritară.
Abordare Hibridă: Coloane Structurate + JSON
Nu recomandăm aplatizarea completă a fiecărui câmp extras într-o coloană dedicată, deoarece formatele documentelor se schimbă. Cea mai bună abordare este:
- Coloane Core (Structurate): ID Dosar, Cod Fiscal, Venit Lunar, Data Angajării. Aceste coloane trebuie să fie tipizate (INT64, STRING, DATE) pentru a permite join-uri rapide cu tabelele din CRM și pentru a optimiza costurile de stocare (formatul BigQuery Capacitor).
- Coloană Payload (JSON): Tot restul extragerii (detalii minore, note marginale) rămâne într-o coloană de tip
JSON. BigQuery suportă nativ accesul la câmpurile JSON cu o sintaxă eficientă.
Exemplu de interogare analitică unificată:
SELECT
crm.customer_id,
crm.risk_score_preliminare,
docs.reddito_mensile,
SAFE_CAST(docs.json_payload.dettagli_extra.bonus_produzione AS FLOAT64) as bonus
FROM
`fintech_lakehouse.crm_customers` crm
JOIN
`fintech_lakehouse.extracted_income_data` docs
ON
crm.tax_code = docs.codice_fiscale
WHERE
docs.reddito_mensile > 2000;Faza 4: Securitate și Conformitate GDPR (Row-Level Security)
Tratând date sensibile precum veniturile și evaluările, securitatea nu este opțională. GDPR impune ca accesul la datele personale să fie limitat la personalul strict necesar.
Într-un data lakehouse google cloud, nu este necesar să creăm vizualizări separate pentru fiecare grup de utilizatori. Utilizăm Row-Level Security (RLS) din BigQuery.
Implementarea Politicilor de Acces
Să presupunem că avem două grupuri de utilizatori: Analiști de Risc (acces complet) și Agenți Comerciali (acces limitat doar la propriile dosare).
CREATE ROW ACCESS POLICY commercial_filter
ON `fintech_lakehouse.extracted_income_data`
GRANT TO ('group:agenti-commerciali@banca.it')
FILTER USING (agente_id = SESSION_USER());Cu această politică, atunci când un agent execută un SELECT *, BigQuery va filtra automat rezultatele, afișând doar rândurile unde agente_id corespunde utilizatorului logat. Datele sensibile ale celorlalți clienți rămân invizibile, garantând conformitatea normativă fără a duplica datele.
Faza 5: Credit Scoring Predictiv cu Vertex AI
Ultima etapă a Lakehouse-ului nostru este activarea datelor. Acum că am unit datele comportamentale (istoricul plăților din CRM) cu datele reale privind veniturile (extrase din fluturașii de salariu), putem antrena modele de Machine Learning superioare.
Utilizând Vertex AI integrat cu BigQuery, putem crea un model de regresie logistică sau o rețea neuronală pentru a prezice probabilitatea de neplată (PD).
- Feature Engineering: Creăm o vizualizare în BigQuery care unește tabelele CRM și Documentare.
- Training: Folosim
CREATE MODELdirect în SQL (BigQuery ML) sau exportăm setul de date în Vertex AI pentru AutoML. - Prediction: Modelul antrenat poate fi apelat în batch în fiecare noapte pentru a recalcula scorul de risc al tuturor dosarelor deschise, semnalând anomalii între venitul declarat și cel extras din documente.
Concluzii

Implementarea unui data lakehouse google cloud în sectorul ipotecar transformă radical operativitatea. Nu este vorba doar de tehnologie, ci de viteza de business: trecerea de la zile la minute pentru pre-aprobarea unui credit ipotecar.
Arhitectura prezentată, bazată pe integrarea strânsă dintre BigQuery, GCS și Document AI, oferă trei avantaje competitive imediate:
- Unificare: O singură sursă de adevăr pentru date structurate și nestructurate.
- Automatizare: Reducerea intervenției umane în extragerea datelor (Data Entry).
- Conformitate: Control granular al accesului nativ în baza de date.
Pentru instituțiile financiare care privesc spre 2026 și dincolo de acesta, această convergență între gestionarea documentară și analiza datelor reprezintă standardul de facto pentru a rămâne competitive într-o piață tot mai ghidată de algoritmi.
Întrebări frecvente

Un Data Lakehouse pe Google Cloud este o arhitectură hibridă care combină flexibilitatea de stocare economică a Data Lake-urilor cu performanțele de analiză ale Data Warehouse-urilor. În sectorul financiar, această abordare permite eliminarea silozurilor dintre datele structurate și documentele nestructurate, precum PDF-urile, permițând interogări SQL unificate. Avantajele principale includ reducerea duplicării datelor, scăderea costurilor de stocare și capacitatea de a obține insight-uri în timp real pentru procese precum aprobarea creditelor ipotecare.
Analiza PDF-urilor în BigQuery se realizează prin utilizarea Object Tables, care mapează fișierele prezente în Google Cloud Storage ca tabele doar pentru citire. Pentru a extrage datele conținute în documente, se integrează Remote Functions care conectează BigQuery la serviciile Document AI. Acest lucru permite invocarea modelelor de extragere inteligentă direct prin interogări SQL, transformând informații nestructurate, cum ar fi venitul net de pe un fluturaș de salariu, în date structurate gata pentru analiză.
Securitatea datelor sensibile și conformitatea cu GDPR sunt gestionate prin Row-Level Security (RLS) nativă din BigQuery. În loc să se creeze copii multiple ale datelor pentru diverse echipe, RLS permite definirea unor politici de acces granulare care filtrează rândurile vizibile în funcție de utilizatorul conectat. De exemplu, un analist de risc poate vedea toate datele, în timp ce un agent comercial va vizualiza doar dosarele propriilor clienți, garantând confidențialitatea fără duplicări.
Vertex AI potențează credit scoring-ul utilizând datele unificate din Lakehouse pentru a antrena modele de Machine Learning avansate. Unind istoricul plăților prezent în CRM cu datele reale privind veniturile extrase din documente prin Document AI, este posibilă crearea unor modele predictive mai precise. Acești algoritmi pot calcula probabilitatea de neplată și pot detecta anomalii între venitul declarat și cel efectiv, automatizând și făcând mai sigură evaluarea riscului.
Pilonii acestei arhitecturi includ Google Cloud Storage pentru stocarea fizică a fișierelor brute și BigQuery ca motor central pentru analiza datelor structurate și a metadatelor. La acestea se adaugă Document AI pentru procesarea inteligentă a documentelor (IDP) și extragerea entităților, și Vertex AI pentru aplicarea modelelor predictive pe datele consolidate. Această combinație transformă o simplă arhivă într-o platformă analitică activă și automatizată.
Surse și Aprofundare


Ați găsit acest articol util? Există un alt subiect pe care ați dori să-l tratez?
Scrieți-l în comentariile de mai jos! Mă inspir direct din sugestiile voastre.