Kurz gesagt (TL;DR)
Das Data-Lakehouse-Paradigma modernisiert das Credit Scoring, indem es das Management strukturierter und unstrukturierter Daten in einer einzigen skalierbaren Infrastruktur vereint.
Die Wertschöpfung aus heterogenen Quellen wie Dokumenten und Logs erfolgt durch fortschrittliche NLP-Pipelines, die Rohinformationen in prädiktive Features transformieren.
Die integrierte Schichtenarchitektur mit Feature Store gewährleistet die Datengovernance und die Abstimmung zwischen Modelltraining und Echtzeit-Inferenz.
Der Teufel steckt im Detail. 👇 Lesen Sie weiter, um die kritischen Schritte und praktischen Tipps zu entdecken, um keine Fehler zu machen.
In der Fintech-Landschaft des Jahres 2026 hängt die Fähigkeit zur Bewertung des Kreditrisikos nicht mehr nur von der Zahlungshistorie oder dem Kontostand ab. Die moderne Grenze ist das Data Lakehouse Credit Scoring, ein architektonischer Ansatz, der die Dichotomie zwischen Data Warehouses (hervorragend für strukturierte Daten) und Data Lakes (notwendig für unstrukturierte Daten) überwindet. Dieser technische Leitfaden untersucht, wie eine Infrastruktur entworfen wird, die in der Lage ist, heterogene Daten aufzunehmen, zu verarbeiten und bereitzustellen, um Machine-Learning-Modelle der nächsten Generation zu speisen.

Die Evolution des Credit Scoring: Jenseits tabellarischer Daten
Traditionell basierte das Credit Scoring auf logistischen Regressionsmodellen, die mit starr strukturierten Daten aus den Core-Banking-Systemen gefüttert wurden. Dieser Ansatz ignoriert jedoch eine Goldgrube an Informationen: unstrukturierte Daten. Support-E-Mails, Chat-Logs, PDF-Dokumente von Bilanzen und sogar Navigations-Metadaten bieten entscheidende prädiktive Signale über die finanzielle Stabilität eines Kunden oder seine Abwanderungsneigung (Churn).
Das Paradigma des Data Lakehouse erweist sich als die definitive Lösung. Durch die Verbindung der Flexibilität kostengünstiger Speicher (wie Amazon S3 oder Google Cloud Storage) mit den Transaktionsfähigkeiten und dem Metadatenmanagement, die für Warehouses typisch sind (durch Technologien wie Delta Lake, Apache Iceberg oder Apache Hudi), ist es möglich, eine Single Source of Truth für fortgeschrittenes Credit Scoring zu schaffen.
Referenzarchitektur für Credit Scoring 2.0
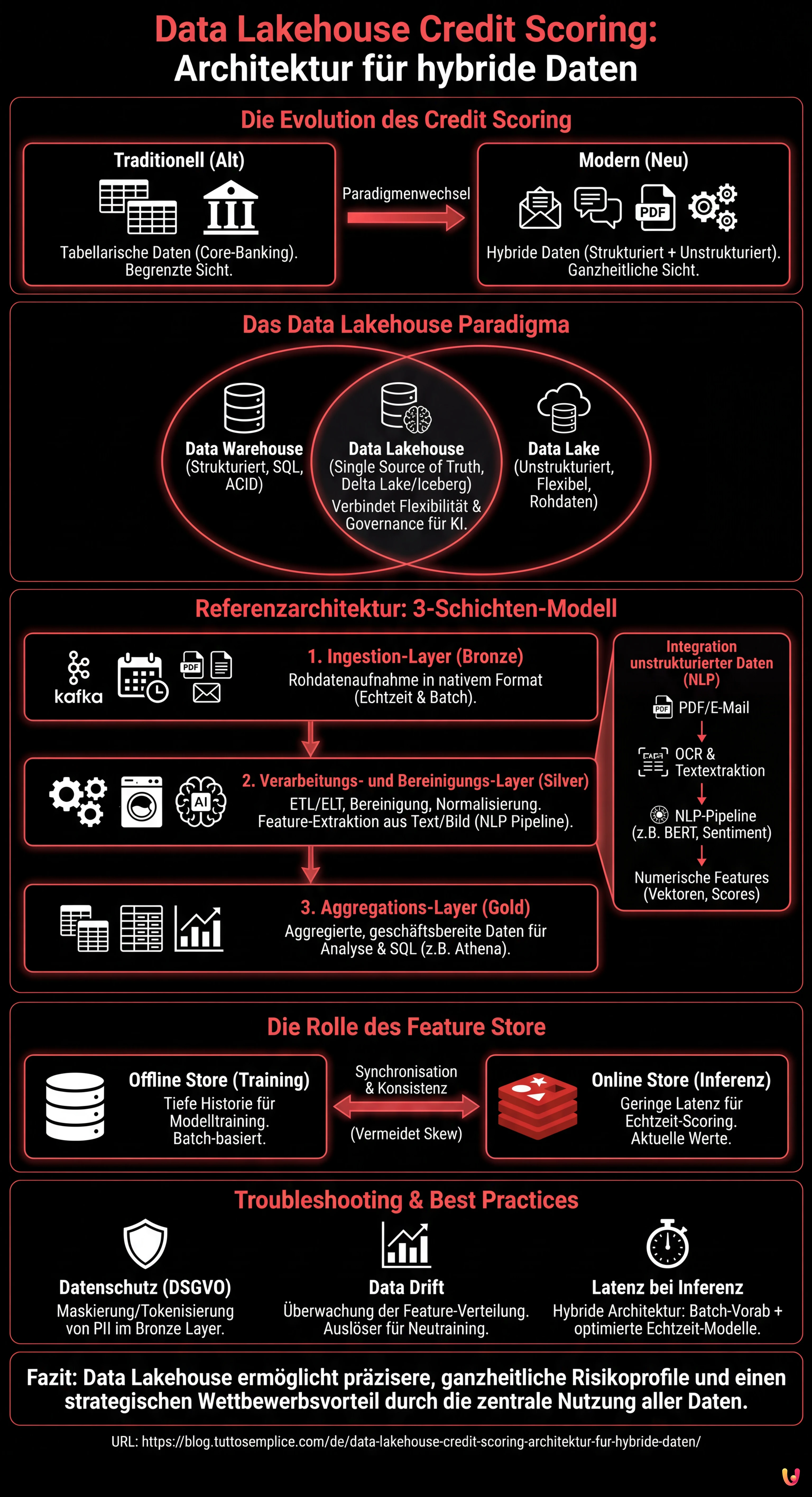
Um ein effektives System aufzubauen, müssen wir eine Schichtenarchitektur skizzieren, die Skalierbarkeit und Governance gewährleistet. Hier sind die grundlegenden Komponenten:
1. Ingestion-Layer (Bronze Layer)
Die Daten landen in ihrem nativen Format im Lakehouse. In einem Credit-Scoring-Szenario haben wir:
- Echtzeit-Streams: POS-Transaktionen, Clickstream der mobilen App (via Apache Kafka oder Amazon Kinesis).
- Batch: Tägliche CRM-Dumps, Berichte externer Kreditauskunfteien.
- Unstrukturiert: Gehaltsabrechnungs-PDFs, E-Mails, Aufzeichnungen aus dem Callcenter.
2. Verarbeitungs- und Bereinigungs-Layer (Silver Layer)
Hier geschieht die Magie von ETL/ELT. Unter Verwendung verteilter Engines wie Apache Spark oder verwalteter Dienste wie AWS Glue werden die Daten bereinigt, dedupliziert und normalisiert. In dieser Phase werden unstrukturierte Daten in nutzbare Features transformiert.
3. Aggregations-Layer (Gold Layer)
Die Daten sind bereit für den geschäftlichen Konsum und die Analyse, organisiert in aggregierten Tabellen pro Kunde, bereit für SQL-Abfragen (z. B. Athena, BigQuery oder Databricks SQL).
Integration unstrukturierter Daten: Die NLP-Herausforderung

Die wahre Innovation im Data Lakehouse Credit Scoring liegt in der Extraktion von Features aus Text und Bildern. Wir können kein PDF in ein XGBoost-Modell einspeisen, daher müssen wir es im Silver Layer verarbeiten.
Angenommen, wir möchten E-Mails analysieren, die mit dem Kundenservice ausgetauscht wurden, um Anzeichen finanzieller Belastung zu erkennen. Der Prozess umfasst:
- OCR und Textextraktion: Verwendung von Bibliotheken wie Tesseract oder Cloud-Diensten (AWS Textract) zur Konvertierung von PDFs/Bildern in Text.
- NLP-Pipeline: Anwendung von Transformer-Modellen (z. B. BERT, feinabgestimmt auf den Finanzbereich), um Entitäten zu extrahieren (NER) oder das Sentiment zu analysieren.
- Feature-Vektorisierung: Konvertierung des Ergebnisses in numerische Vektoren oder kategorische Scores (z. B. “Sentiment_Score_Last_30_Days”).
Die entscheidende Rolle des Feature Store
Eines der häufigsten Probleme im MLOps ist der Training-Serving Skew: Die während des Modelltrainings berechneten Features unterscheiden sich von denen, die in Echtzeit während der Inferenz berechnet werden (wenn der Kunde über die App einen Kredit beantragt). Um dieses Problem zu lösen, muss die Lakehouse-Architektur einen Feature Store integrieren (wie Feast, Hopsworks oder SageMaker Feature Store).
Der Feature Store verwaltet zwei Ansichten:
- Offline Store: Basiert auf dem Data Lakehouse und enthält die tiefe Historie für das Training der Modelle.
- Online Store: Eine Datenbank mit geringer Latenz (z. B. Redis oder DynamoDB), die den letzten bekannten Wert der Features für die Echtzeit-Inferenz bereitstellt.
Praktisches Beispiel: ETL-Pipeline mit PySpark
Nachfolgend ein konzeptionelles Beispiel, wie ein Spark-Job strukturierte Transaktionsdaten mit Sentiment-Scores aus unstrukturierten Daten innerhalb einer Delta-Lake-Architektur verbinden könnte.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, current_timestamp
# Spark-Initialisierung mit Delta Lake-Unterstützung
spark = SparkSession.builder
.appName("CreditScoringETL")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
# 1. Laden strukturierter Daten (Transaktionen)
df_transactions = spark.read.format("delta").load("s3://datalake/silver/transactions")
# Feature Engineering: Durchschnittsausgaben der letzten 30 Tage
feat_avg_spend = df_transactions.groupBy("customer_id")
.agg(avg("amount").alias("avg_monthly_spend"))
# 2. Laden verarbeiteter unstrukturierter Daten (Chat-Logs/E-Mails)
# Wir nehmen an, dass eine vorherige NLP-Pipeline die Sentiment-Scores gespeichert hat
df_sentiment = spark.read.format("delta").load("s3://datalake/silver/customer_sentiment")
# Feature Engineering: Durchschnittliches Sentiment
feat_sentiment = df_sentiment.groupBy("customer_id")
.agg(avg("sentiment_score").alias("avg_sentiment_risk"))
# 3. Join zur Erstellung des vereinheitlichten Feature-Sets
final_features = feat_avg_spend.join(feat_sentiment, "customer_id", "left_outer")
.fillna({"avg_sentiment_risk": 0.5}) # Behandlung von Nullwerten
# 4. Schreiben in den Feature Store (Offline Layer)
final_features.write.format("delta")
.mode("overwrite")
.save("s3://datalake/gold/credit_scoring_features")
print("Pipeline abgeschlossen: Feature Store aktualisiert.")
Troubleshooting und Best Practices
Bei der Implementierung eines Data Lakehouse Credit Scoring-Systems stößt man häufig auf spezifische Hindernisse. Hier erfahren Sie, wie Sie diese abmildern können:
Datenschutzmanagement (DSGVO/CCPA)
Unstrukturierte Daten enthalten oft sensible PII (Personally Identifiable Information). Es ist zwingend erforderlich, Maskierungs- oder Tokenisierungstechniken im Bronze Layer zu implementieren, bevor die Daten für Data Scientists zugänglich werden. Tools wie Presidio von Microsoft können die Anonymisierung von Text automatisieren.
Data Drift
Das Verhalten der Kunden ändert sich. Ein Modell, das auf Daten von 2024 trainiert wurde, ist 2026 möglicherweise nicht mehr gültig. Die Überwachung der statistischen Verteilung der Features im Feature Store ist unerlässlich, um das automatische Neutraining der Modelle auszulösen.
Latenz bei der Inferenz
Wenn die Berechnung unstrukturierter Features (z. B. Analyse eines gerade hochgeladenen PDFs) zu langsam ist, leidet die Benutzererfahrung. In diesen Fällen wird eine hybride Architektur empfohlen: Alles Mögliche im Batch (Historie) vorberechnen und leichte, optimierte NLP-Modelle (z. B. DistilBERT auf ONNX) für die Echtzeitverarbeitung verwenden.
Fazit

Die Einführung eines Data-Lakehouse-Ansatzes für das Credit Scoring ist nicht nur ein technologisches Update, sondern ein strategischer Wettbewerbsvorteil. Durch die Zentralisierung strukturierter und unstrukturierter Daten und die Gewährleistung ihrer Konsistenz durch einen Feature Store können Finanzinstitute ganzheitliche Risikoprofile erstellen, Zahlungsausfälle reduzieren und das Angebot für den Kunden personalisieren. Der Schlüssel zum Erfolg liegt in der Qualität der Data-Engineering-Pipeline: Ein KI-Modell ist nur so gut wie die Daten, die es speisen.
Häufig gestellte Fragen

Data Lakehouse Credit Scoring ist ein hybrides Architekturmodell, das die Grenzen traditioneller Data Warehouses überwindet, indem es das Management strukturierter Daten mit der Flexibilität von Data Lakes verbindet. Dieser Ansatz ermöglicht es Fintechs, unstrukturierte Quellen wie E-Mails und Dokumente zu nutzen, um das Kreditrisiko präziser zu berechnen und die Abhängigkeit von reinen Zahlungshistorien zu verringern.
Unstrukturierte Daten wie PDFs oder Chat-Logs werden im Silver Layer durch NLP- und OCR-Pipelines verarbeitet. Diese Technologien konvertieren Text und Bilder in numerische Vektoren oder Sentiment-Scores und transformieren so qualitative Informationen in quantitative Features, die prädiktive Modelle analysieren können, um die Zuverlässigkeit des Kunden zu bewerten.
Der Feature Store fungiert als zentrales System, um die Datenkonsistenz zwischen der Trainings- und der Inferenzphase zu gewährleisten. Er eliminiert die als Training-Serving Skew bekannte Diskrepanz, indem er zwei synchronisierte Ansichten aufrechterhält: einen Offline Store für die tiefe Historie und einen Online Store mit geringer Latenz, um aktualisierte Daten in Echtzeit während Kreditanfragen bereitzustellen.
Die Infrastruktur gliedert sich in drei Hauptstadien: den Bronze Layer für die Ingestion der Rohdaten, den Silver Layer für die Bereinigung und Anreicherung durch Verarbeitungsalgorithmen und den Gold Layer, wo die Daten aggregiert und bereit für den geschäftlichen Einsatz sind. Diese Schichtenstruktur sichert Skalierbarkeit, Governance und Datenqualität über den gesamten Lebenszyklus.
Der Schutz persönlicher Informationen erfolgt durch die Implementierung von Maskierungs- und Tokenisierungstechniken direkt auf der Ingestion-Ebene, dem Bronze Layer. Durch den Einsatz spezifischer Tools zur automatischen Anonymisierung ist es möglich, Verhaltensweisen und Trends aus unstrukturierten Daten zu analysieren, ohne die Identität der Kunden offenzulegen oder gegen Vorschriften wie die DSGVO zu verstoßen.
Quellen und Vertiefung


Fanden Sie diesen Artikel hilfreich? Gibt es ein anderes Thema, das Sie von mir behandelt sehen möchten?
Schreiben Sie es in die Kommentare unten! Ich lasse mich direkt von Ihren Vorschlägen inspirieren.