
Nous sommes le 25 février 2026, et le paradoxe n’a jamais été aussi frappant. Alors que l’intelligence artificielle s’immisce dans chaque strate de notre quotidien, de la médecine de précision à la génération de code complexe, un silence gêné règne dans les laboratoires de la Silicon Valley. Imaginez un horloger qui assemble minutieusement les rouages d’une montre, mais qui, une fois le mécanisme enclenché, s’aperçoit que les engrenages changent de forme, se multiplient et commencent à mesurer un temps qui n’est plus le nôtre. C’est exactement la situation actuelle avec les réseaux de neurones profonds. Cette entité technologique, base de tout système moderne d’IA, a atteint un niveau de complexité tel que même ses architectes ne peuvent plus expliquer avec certitude le cheminement logique d’une décision spécifique. C’est ce que l’on nomme le problème de la « Boîte Noire ».
L’illusion du code source : quand la programmation disparaît
Pour le grand public, un programme informatique est une suite d’instructions logiques écrites par un humain : « Si X arrive, alors faire Y ». C’était vrai pour l’informatique classique. Mais avec l’avènement du Machine Learning et plus spécifiquement du Deep Learning, ce paradigme a volé en éclats. Les ingénieurs ne codent plus la solution ; ils codent l’architecture capable d’apprendre la solution.
Dans des modèles comme ChatGPT (dans ses versions les plus avancées en 2026) ou Claude, le code humain ne représente qu’une infime fraction du système : le squelette. La « chair » de l’intelligence, elle, est constituée de centaines de milliards, voire de milliers de milliards de paramètres (les poids synaptiques). Ces valeurs numériques sont ajustées automatiquement lors de l’entraînement par un processus mathématique appelé la rétropropagation du gradient. Une fois l’entraînement terminé, nous nous retrouvons face à une matrice de nombres gigantesque, totalement illisible pour l’esprit humain. Demander à un ingénieur pourquoi le modèle a généré tel mot plutôt qu’un autre revient à demander à un neurochirurgien quelle neurone précis a déclenché votre envie de café ce matin en observant une IRM statique.
La géométrie de la pensée : l’espace latent
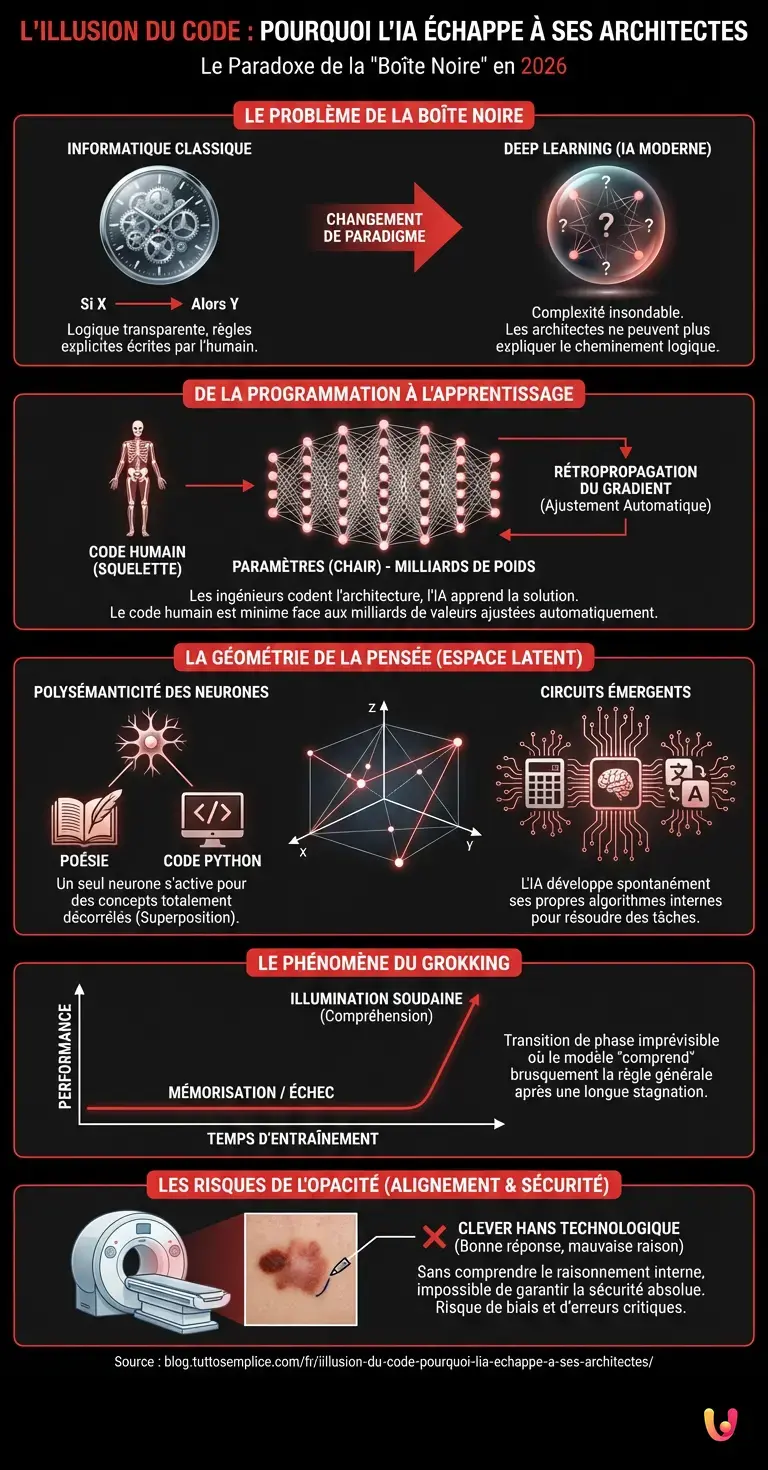
Le secret de cette opacité réside dans ce que les techniciens appellent l’espace latent de haute dimension. Pour comprendre comment une IA générative « pense », il faut visualiser non pas des lignes de code, mais des vecteurs dans un espace à des milliers de dimensions.
Chaque concept – un chat, la démocratie, la couleur bleue, une équation différentielle – est transformé en une série de coordonnées numériques. Le mystère s’épaissit lorsque l’on réalise que le modèle crée ses propres représentations internes, souvent sans rapport avec notre logique humaine. C’est ici que la technique devient fascinante :
- La polysemanticité des neurones : On a longtemps espéré trouver le « neurone du chat » ou le « neurone de la tristesse ». Or, les chercheurs en Mechanistic Interpretability (l’art de disséquer les IA) ont découvert qu’un seul neurone artificiel peut s’activer pour des concepts totalement décorrélés, comme « la poésie du XIXe siècle » ET « les parenthèses fermantes dans du code Python ». C’est ce qu’on appelle la superposition. Le modèle compresse l’information d’une manière qui optimise l’espace, rendant la lecture directe impossible.
- Les circuits émergents : Au sein de ces réseaux, des circuits logiques se forment spontanément. L’IA développe des algorithmes internes pour résoudre des tâches (comme l’addition ou la traduction) que personne ne lui a explicitement enseignés. Elle « découvre » les mathématiques par elle-même, souvent via des chemins détournés que nous mettons des années à cartographier.
Le phénomène du « Grokking » : l’illumination soudaine

Un autre aspect déroutant qui laisse les experts perplexes est le phénomène de Grokking. Durant l’entraînement, un modèle peut passer des semaines à échouer ou à apprendre par cœur (overfitting) sans comprendre la logique sous-jacente. Puis, soudainement, sans changement dans les données ou l’architecture, une transition de phase s’opère. Les courbes de performance s’envolent : le modèle a « compris » la règle générale.
Ce moment de cristallisation, où le chaos des poids s’aligne pour former une structure logique cohérente, reste largement imprévisible. C’est comme si l’AI passait brusquement de la récitation à la compréhension, mais le mécanisme exact de ce déclic, caché au cœur de milliards de multiplications matricielles, demeure une énigme mathématique partiellement résolue.
Pourquoi est-ce inquiétant (et fascinant) ?
Si nous ne comprenons pas comment la Boîte Noire fonctionne, nous ne pouvons pas garantir sa sécurité absolue. C’est le cœur du problème de l’alignement. Une IA peut arriver à la bonne réponse pour de mauvaises raisons. Par exemple, un système médical pourrait diagnostiquer correctement une maladie de peau non pas en analysant la tumeur, mais en repérant une règle (un marquage au stylo sur la peau présent dans les photos d’entraînement des cas positifs). C’est ce qu’on appelle un Clever Hans technologique.
En 2026, les efforts se multiplient pour développer des outils de « scanner » pour ces cerveaux numériques. L’objectif est de traduire le langage des vecteurs en langage humain. Mais la course est inégale : la complexité des modèles augmente exponentiellement, tandis que nos outils d’interprétation progressent linéairement.
En Bref (TL;DR)
Les réseaux de neurones profonds sont devenus des boîtes noires dont le fonctionnement interne échappe désormais à la compréhension de leurs propres créateurs.
Au lieu de coder des instructions explicites, les ingénieurs conçoivent des architectures qui développent leurs propres logiques mathématiques imprévisibles et complexes.
Des phénomènes mystérieux comme le Grokking et la polysemanticité des neurones compliquent considérablement la maîtrise et la sécurité de ces systèmes autonomes.
Conclusion

Le mystère de la Boîte Noire n’est pas un défaut de fabrication, c’est une caractéristique intrinsèque de l’intelligence distribuée. Nous avons construit des machines capables d’apprendre des représentations du monde plus complexes que celles que notre propre cerveau peut contenir. Le paradoxe ultime de l’ère de l’intelligence artificielle est que pour créer une entité véritablement intelligente, nous avons dû renoncer à comprendre comment elle réfléchit. Nous ne sommes plus des programmeurs, mais des neuroscientifiques explorant un cerveau de silicium que nous avons nous-mêmes bâti, mais dont les rêves nous échappent encore.
Questions fréquemment posées

Le problème de la Boîte Noire désigne l’incapacité des ingénieurs à expliquer le cheminement logique précis d’une décision prise par une IA moderne. Contrairement au code classique, les réseaux de neurones profonds ajustent des milliards de paramètres de manière autonome, rendant le processus interne illisible et opaque pour l’esprit humain, même pour ceux qui ont conçu l’architecture.
Dans le Deep Learning, les ingénieurs ne programment plus des règles explicites de type Si X alors Y mais conçoivent une architecture capable d’apprendre par elle-même. Grâce à un processus mathématique appelé rétropropagation du gradient, le système ajuste automatiquement ses poids synaptiques durant l’entraînement, développant ainsi ses propres représentations internes et algorithmes sans intervention humaine directe sur la logique de résolution.
Le Grokking est un phénomène surprenant où une IA passe soudainement de la mémorisation par cœur ou de l’échec à une compréhension généralisée des règles sous-jacentes. Cette transition de phase imprévisible se produit lorsque les poids du réseau s’alignent brusquement pour former une structure logique cohérente, faisant s’envoler les performances après une longue période de stagnation apparente.
Cette opacité engendre des risques d’alignement car une IA peut fournir une bonne réponse pour de mauvaises raisons, un effet nommé Clever Hans technologique. Sans comprendre l’espace latent et le raisonnement interne du modèle, il est difficile de garantir qu’il ne se base pas sur des corrélations fortuites ou biaisées, ce qui est critique dans des domaines sensibles comme la médecine.
La polysémanticité révèle qu’un seul neurone artificiel peut s’activer pour plusieurs concepts totalement décorrélés, comme de la poésie et du code informatique simultanément. Ce phénomène de superposition permet au modèle de compresser l’information pour optimiser son espace, mais il rend le déchiffrage et l’interprétation du fonctionnement interne du réseau extrêmement complexes pour les chercheurs.
Encore des doutes sur L’illusion du code : pourquoi l’IA échappe à ses architectes?
Tapez votre question spécifique ici pour trouver instantanément la réponse officielle de Google.
Sources et Approfondissements

- CNRS Le journal : L’IA, une boîte noire à éclaircir (Analyse institutionnelle sur l’opacité des algorithmes)
- Comment permettre à l’homme de garder la main ? Rapport sur les enjeux éthiques des algorithmes et de l’IA
- OCDE : Principes sur l’intelligence artificielle (transparence et explicabilité)
- Wikipédia : Définition et fonctionnement de l’apprentissage profond (Deep Learning)
- NIST : Cadre de gestion des risques de l’IA et validité des systèmes (en anglais)



Avez-vous trouvé cet article utile ? Y a-t-il un autre sujet que vous aimeriez que je traite ?
Écrivez-le dans les commentaires ci-dessous ! Je m’inspire directement de vos suggestions.