En Bref (TL;DR)
La migration des systèmes legacy dans le secteur bancaire nécessite des stratégies évoluées pour décoder des stratifications logiques complexes et souvent sans documentation.
L’utilisation avancée du Prompt Engineering et des LLM permet de transformer le reverse engineering en une extraction précise des règles métier.
Des méthodologies comme le Chain-of-Thought assurent la parité fonctionnelle en décompilant la sémantique des algorithmes critiques au lieu de simplement traduire leur syntaxe.
Le diable est dans les détails. 👇 Continuez à lire pour découvrir les étapes critiques et les conseils pratiques pour ne pas vous tromper.
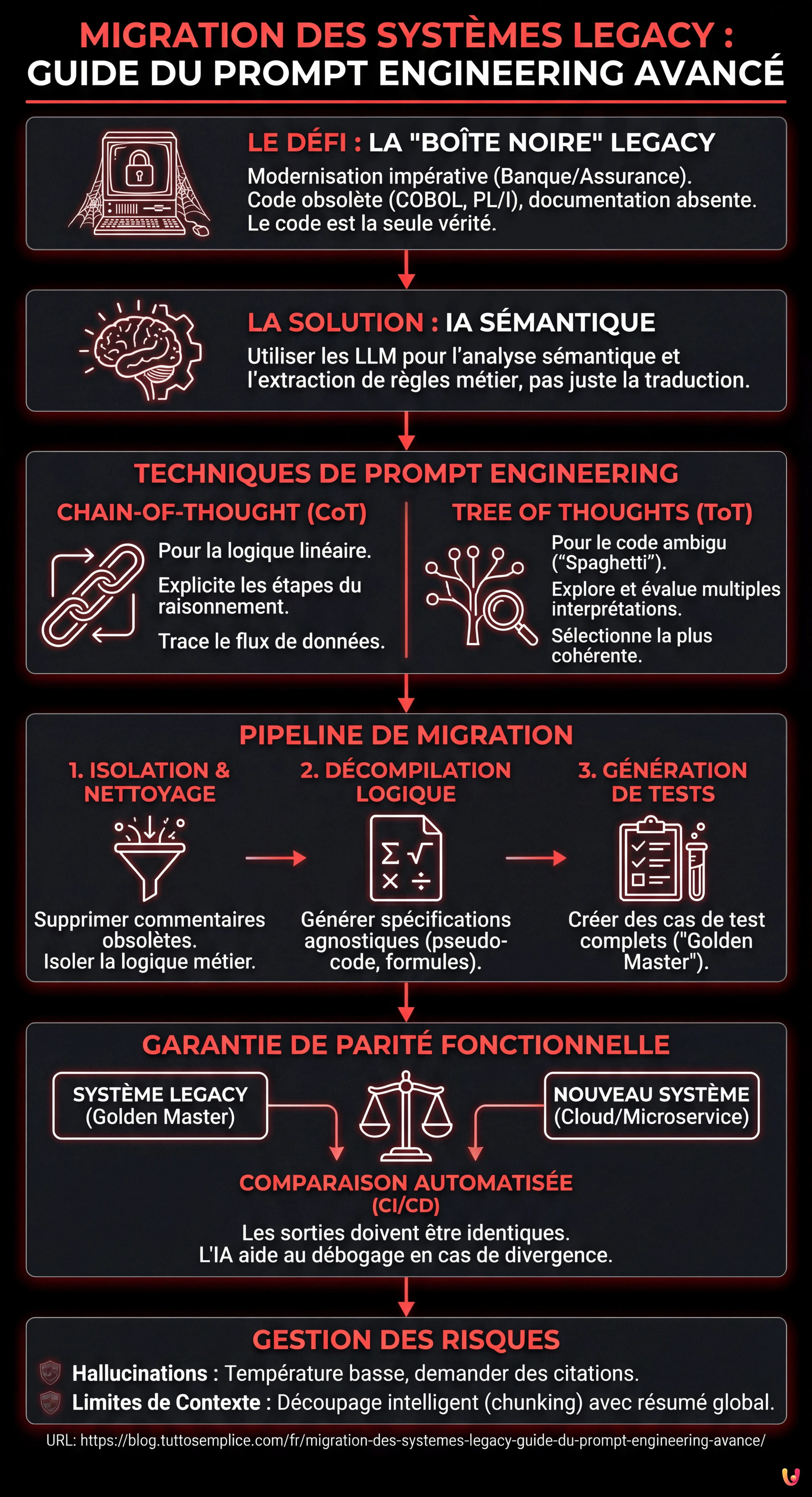
Nous sommes en 2026 et la modernisation des infrastructures IT n’est plus une option, mais un impératif de survie, en particulier dans le secteur bancaire et des assurances. La migration des systèmes legacy vers le cloud représente l’un des défis les plus complexes pour les DSI et les Architectes Logiciels. Il ne s’agit pas simplement de déplacer du code d’un mainframe vers un conteneur Kubernetes ; le véritable défi réside dans la compréhension profonde de décennies de stratifications logiques, souvent non documentées.
Dans cette analyse technique approfondie, nous explorerons comment l’utilisation avancée des Grands Modèles de Langage (LLM) et du Prompt Engineering peut transformer le processus de reverse engineering. Nous ne parlerons pas de simple génération de code (comme ‘traduis ce COBOL en Python’), mais d’une approche méthodique de l’extraction de la logique métier (Business Rules Extraction) et de la garantie de la parité fonctionnelle via des tests automatisés.

Le Problème de la Boîte Noire dans les Systèmes Bancaires
De nombreux systèmes critiques fonctionnent sur des bases de code écrites en COBOL, PL/I ou Fortran dans les années 80 ou 90. Le problème principal dans la migration des systèmes legacy n’est pas la syntaxe, mais la sémantique. Souvent, la documentation est absente ou désalignée par rapport au code en production. Les développeurs d’origine sont partis à la retraite et le code lui-même est devenu la seule source de vérité.
L’approche traditionnelle prévoit une analyse manuelle, coûteuse et sujette aux erreurs humaines. L’approche moderne, renforcée par l’IA, utilise les LLM comme moteurs de raisonnement pour exécuter une analyse statique sémantique. L’objectif est de décompiler l’algorithme, pas seulement de le traduire.
Prérequis et Outils
Pour suivre ce guide, il est nécessaire de disposer de :
- Accès à des LLM avec de grandes fenêtres de contexte (ex. GPT-4o, Claude 3.5 Sonnet ou des modèles open source comme Llama 4 optimisés pour le code).
- Accès en lecture à la base de code legacy (extraits COBOL/JCL).
- Un environnement d’orchestration (Python/LangChain) pour automatiser les pipelines de prompt.
Techniques de Prompt Engineering pour l’Analyse du Code

Pour extraire des règles métier complexes, comme le calcul d’un plan d’amortissement à la française avec des exceptions spécifiques par devise, un prompt zero-shot ne suffit pas. Nous devons guider le modèle à travers des processus cognitifs structurés.
1. Chain-of-Thought (CoT) pour la Linéarisation de la Logique
La technique Chain-of-Thought pousse le modèle à expliciter les étapes intermédiaires du raisonnement. Dans la migration des systèmes legacy, c’est crucial pour tracer le flux des données à travers des variables globales obscures.
Exemple de Prompt CoT :
SYSTEM: Tu es un Analyste Mainframe Senior spécialisé en COBOL et logique bancaire. USER: Analyse le paragraphe COBOL 'CALC-RATA' suivant. Ne le traduis pas encore. Utilise une approche Chain-of-Thought pour : 1. Identifier toutes les variables d'entrée et de sortie. 2. Tracer comment la variable 'WS-INT-RATE' est modifiée ligne par ligne. 3. Expliquer la logique mathématique sous-jacente en langage naturel. 4. Mettre en évidence les éventuels 'nombres magiques' ou constantes codées en dur. CODE : [Insérer Extrait COBOL]
2. Tree of Thoughts (ToT) pour la Désambiguïsation
Le code legacy est souvent riche en instructions GO TO et logiques conditionnelles imbriquées (Code Spaghetti). Ici, la technique Tree of Thoughts est supérieure. Elle permet au modèle d’explorer différentes interprétations possibles d’un bloc de code ambigu, de les évaluer et d’écarter celles qui sont illogiques.
Stratégie ToT appliquée :
- Génération : Demander au modèle de proposer 3 interprétations fonctionnelles différentes d’un bloc
PERFORM VARYINGcomplexe. - Évaluation : Demander au modèle d’agir comme un “Critique” et d’évaluer laquelle des 3 interprétations est la plus cohérente avec le contexte bancaire standard (ex. règles Bâle III).
- Sélection : Conserver l’interprétation gagnante comme base pour la spécification fonctionnelle.
Pipeline d’Extraction : Étape par Étape
Voici comment structurer un pipeline opérationnel pour soutenir la migration des systèmes legacy :
Phase 1 : Isolation et Assainissement
Avant d’envoyer le code au LLM, supprimez les commentaires obsolètes qui pourraient causer des hallucinations (ex. “TODO: fix this in 1998”). Isolez les routines de calcul (Logique Métier) de celles d’E/S ou de gestion de base de données.
Phase 2 : Décompilation Logique (Le Prompt “Architecte”)
Utilisez un prompt structuré pour générer un pseudo-code agnostique. L’objectif est d’obtenir une spécification qu’un humain puisse lire.
PROMPT : Analyse le code fourni. Extrais EXCLUSIVEMENT les règles métier. Sortie requise au format Markdown : - Nom de la Règle - Préconditions - Formule Mathématique (au format LaTeX) - Postconditions - Exceptions gérées
Phase 3 : Génération des Cas de Test (Le “Golden Master”)
C’est l’étape critique pour la sécurité. Nous utilisons le LLM pour générer des entrées de test qui couvrent toutes les branches conditionnelles (Branch Coverage) identifiées lors de la phase précédente.
Intégration CI/CD et Tests de Parité
Une migration des systèmes legacy réussie ne se termine pas avec la réécriture du code, mais avec la preuve que le nouveau système (ex. en Java ou Go) se comporte exactement comme l’ancien.
Automatisation des Tests de Parité
Nous pouvons intégrer les LLM dans le pipeline CI/CD (ex. Jenkins ou GitLab CI) pour créer des tests unitaires dynamiques :
- Génération d’Entrées : Le LLM analyse la logique extraite et génère un fichier JSON avec 100 cas de test (cas limites inclus, comme taux négatifs ou années bissextiles).
- Exécution Legacy : Exécuter ces entrées contre le système legacy (ou un émulateur) et enregistrer les sorties. Cela devient notre “Golden Master”.
- Exécution Nouveau Système : Exécuter les mêmes entrées contre le nouveau microservice.
- Comparaison : Si les sorties divergent, le pipeline échoue.
L’IA peut également être utilisée en phase de débogage : si le test échoue, on peut fournir au LLM le code legacy, le nouveau code et le diff de la sortie, en demandant : “Pourquoi ces deux algorithmes produisent-ils des résultats différents pour l’entrée X ?”.
Dépannage et Risques
Gestion des Hallucinations
Les LLM peuvent inventer des logiques si le code est trop cryptique. Pour atténuer ce risque :
- Régler la
temperatureà 0 ou des valeurs très basses (0.1/0.2) pour maximiser le déterminisme. - Toujours demander des références aux lignes de code originales dans l’explication (Citations).
Limites de la Fenêtre de Contexte
Ne tentez pas d’analyser des programmes monolithiques entiers en un seul prompt. Utilisez des techniques de chunking intelligent, en divisant le code par paragraphes ou sections logiques, tout en maintenant un résumé du contexte global (Global State Summary) qui est passé dans chaque prompt successif.
Conclusions

L’utilisation du Prompt Engineering avancé transforme la migration des systèmes legacy d’une opération d’”archéologie informatique” en un processus d’ingénierie contrôlé. Des techniques comme Chain-of-Thought et Tree of Thoughts nous permettent d’extraire la valeur intellectuelle piégée dans le code obsolète, garantissant que la logique métier qui soutient l’institution financière soit préservée intacte lors du passage au cloud. Nous ne faisons pas que réécrire du code ; nous sauvegardons la connaissance de l’entreprise.
Foire aux questions

L’utilisation de techniques avancées de Prompt Engineering, comme le Chain-of-Thought et le Tree of Thoughts, transforme la migration d’une simple traduction syntaxique en un processus d’ingénierie sémantique. Au lieu de se limiter à convertir du code obsolète comme le COBOL vers des langages modernes, les LLM agissent comme des moteurs de raisonnement pour extraire la logique métier stratifiée et souvent non documentée. Cette approche permet de décompiler les algorithmes, d’identifier les règles d’entreprise critiques et de générer des spécifications fonctionnelles claires, réduisant drastiquement les erreurs humaines et préservant la valeur intellectuelle du logiciel original.
La technique Chain-of-Thought (CoT) guide le modèle pour expliciter les étapes intermédiaires du raisonnement, ce qui est essentiel pour linéariser la logique et tracer le flux des données à travers des variables globales dans des codes linéaires. À l’inverse, le Tree of Thoughts (ToT) est supérieur dans la gestion de code ambigu ou riche en instructions conditionnelles imbriquées, typique du code spaghetti. Le ToT permet au modèle d’explorer différentes interprétations fonctionnelles simultanément, de les évaluer comme un critique expert et de sélectionner celle qui est la plus cohérente avec le contexte bancaire ou les normes en vigueur, en écartant les hypothèses illogiques.
La parité fonctionnelle est obtenue grâce à un pipeline rigoureux de tests automatisés, souvent défini comme l’approche Golden Master. Les LLM sont utilisés pour générer une vaste gamme de cas de test, y compris des scénarios limites, en se basant sur la logique extraite. Ces entrées sont exécutées à la fois sur le système legacy original et sur le nouveau microservice. Les résultats sont comparés automatiquement : si les sorties divergent, le pipeline d’intégration continue signale l’erreur. Cette méthode assure que le nouveau système, écrit dans des langages modernes comme Java ou Go, réplique exactement le comportement mathématique et logique de son prédécesseur.
Le risque principal est représenté par les hallucinations, c’est-à-dire la tendance du modèle à inventer des logiques inexistantes lorsque le code est trop cryptique. Une autre limite est la taille de la fenêtre de contexte qui empêche l’analyse de programmes monolithiques entiers. Pour atténuer ces problèmes, il est fondamental de régler la température du modèle à des valeurs proches de zéro pour maximiser le déterminisme et de toujours demander des citations des lignes de code originales. De plus, on adopte une stratégie de découpage intelligent (chunking), en divisant le code en sections logiques et en maintenant un résumé de l’état global pour préserver le contexte durant l’analyse.
Dans les systèmes critiques développés il y a des décennies, la documentation est souvent absente, incomplète ou, pire, désalignée par rapport au code effectivement en production. Avec le départ à la retraite des développeurs originaux, le code source est devenu la seule source de vérité fiable. Se fier à la documentation papier ou aux commentaires dans le code, qui pourraient faire référence à des modifications datant de plusieurs années, peut conduire à de graves erreurs d’interprétation. L’analyse statique sémantique via IA permet d’ignorer ces artefacts obsolètes et de se concentrer exclusivement sur la logique opérationnelle actuelle.
Sources et Approfondissements

- Commission Européenne : Stratégie de finance numérique pour l’UE
- Wikipedia : Définition et enjeux des Systèmes Hérités (Legacy Systems)
- NIST : Standards et définitions du Cloud Computing (Gouvernement US)
- Wikipedia : Principes et techniques du Prompt Engineering
- Banque des Règlements Internationaux : Cadre réglementaire Bâle III

Avez-vous trouvé cet article utile ? Y a-t-il un autre sujet que vous aimeriez que je traite ?
Écrivez-le dans les commentaires ci-dessous ! Je m'inspire directement de vos suggestions.