En Bref (TL;DR)
L’approche FinOps transforme l’infrastructure cloud d’un centre de coûts en une ressource stratégique, en se concentrant sur la durabilité économique des transactions individuelles.
L’utilisation d’instances Spot et l’auto-scaling basé sur des métriques personnalisées garantissent des performances élevées tout en réduisant considérablement les dépenses de calcul.
Une gestion rigoureuse du trafic de données et des tags permet d’identifier les coûts invisibles et d’optimiser la marge de l’entreprise.
Le diable est dans les détails. 👇 Continuez à lire pour découvrir les étapes critiques et les conseils pratiques pour ne pas vous tromper.
Dans le paysage technologique de 2026, pour un entrepreneur technique ou un CTO d’une entreprise Fintech, l’infrastructure n’est plus seulement un centre de coûts, mais un actif stratégique qui détermine la marge de l’entreprise. L’optimisation des coûts cloud ne concerne plus simplement la réduction de la facture à la fin du mois ; c’est une discipline d’ingénierie complexe qui nécessite une approche culturelle connue sous le nom de FinOps. Dans des environnements à forte charge, où la scalabilité doit garantir la continuité opérationnelle financière (pensez au trading haute fréquence ou à la gestion des prêts hypothécaires en temps réel), réduire les coûts sans discernement est un risque inacceptable.
Ce guide technique explore comment appliquer des méthodologies FinOps avancées sur des plateformes comme AWS et Google Cloud, en dépassant le concept basique de rightsizing pour adopter des architectures élastiques, un tiering intelligent du stockage et une gestion granulaire du trafic de données.

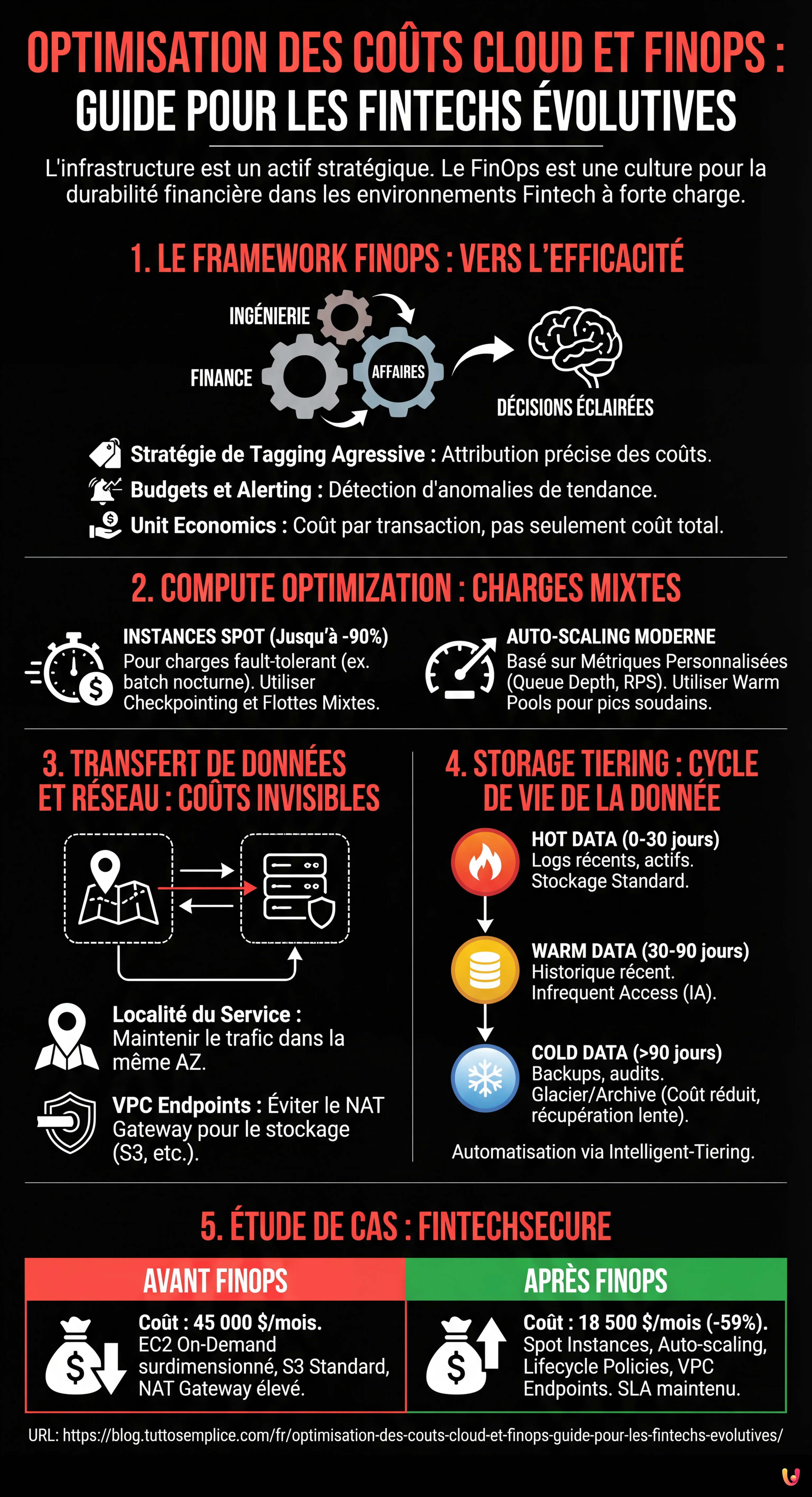
1. Le Framework FinOps : Au-delà des Économies, vers l’Efficacité
Selon la FinOps Foundation, le FinOps est un modèle opérationnel pour le cloud qui combine systèmes, meilleures pratiques et culture pour augmenter la capacité d’une organisation à comprendre les coûts du cloud et à prendre des décisions commerciales éclairées. Dans une Fintech, cela signifie que chaque ingénieur doit être conscient de l’impact économique d’une ligne de code ou d’un choix architectural.
Prérequis pour l’Optimisation
Avant de mettre en œuvre des modifications techniques, il est nécessaire d’établir une base d’observabilité :
- Stratégie de Tagging Agressive : Chaque ressource doit avoir des tags obligatoires (ex.
CostCenter,Environment,ServiceOwner). Sans cela, l’attribution des coûts est impossible. - Budgets et Alerting : Configuration d’AWS Budgets ou de GCP Budget Alerts non seulement sur des seuils fixes, mais sur des anomalies de tendance (ex. un pic soudain d’appels API).
- Unit Economics : Définir le coût par transaction ou par utilisateur actif. L’objectif n’est pas de baisser le coût total si l’entreprise croît, mais de baisser le coût unitaire.
2. Compute Optimization : Stratégies pour Charges de Travail Mixtes
Le poste de dépense le plus important est souvent lié aux ressources de calcul (EC2 sur AWS, Compute Engine sur GCP). Voici comment optimiser dans des scénarios à forte charge.
Utilisation Stratégique des Instances Spot
Les Instances Spot (ou Preemptible VMs sur GCP) offrent des réductions allant jusqu’à 90 %, mais peuvent être terminées par le fournisseur avec peu de préavis. Dans le domaine Fintech, l’utilisation des Spot est souvent redoutée en raison de la criticité des données, mais c’est une peur infondée si elle est gérée architecturalement.
Scénario d’Application : Traitement par Lots Nocturne.
Considérons le calcul des intérêts sur les prêts hypothécaires ou la génération de rapports réglementaires qui a lieu chaque nuit. C’est une charge de travail fault-tolerant (tolérante aux pannes).
- Stratégie : Utiliser des flottes d’instances Spot pour les nœuds worker qui traitent les données, en maintenant les instances On-Demand uniquement pour l’orchestration (ex. le nœud maître d’un cluster Kubernetes ou EMR).
- Mise en œuvre : Configurer l’application pour gérer le “checkpointing”. Si une instance Spot est terminée, le job doit reprendre à partir du dernier point de contrôle sauvegardé sur une base de données ou sur S3/GCS, sans perte de données.
- Diversification : Ne pas miser sur un seul type d’instance. Utiliser des Spot Fleets qui demandent différentes familles d’instances (ex. m5.large, c5.large, r5.large) pour minimiser le risque d’indisponibilité simultanée.
Auto-scaling Basé sur des Métriques Personnalisées
L’auto-scaling basé sur le CPU est obsolète pour les applications modernes. Souvent, un CPU à 40 % cache une latence inacceptable pour l’utilisateur final.
Pour une plateforme Fintech évolutive, les politiques de scaling doivent être agressives et prédictives :
- Métriques de File d’Attente (Queue Depth) : Si vous utilisez Kafka ou SQS/PubSub, scalez en fonction du nombre de messages en file d’attente ou du consumer lag. Il est inutile d’ajouter des serveurs si la file est vide, mais il est vital de les ajouter instantanément si la file dépasse les 1000 messages, indépendamment du CPU.
- Requêtes par Seconde (RPS) : Pour les API Gateway, scalez en fonction du débit des requêtes.
- Warm Pools : Maintenir un pool d’instances pré-initialisées (en état stopped ou hibernate) pour réduire les temps de démarrage lors des pics de trafic de marché (ex. ouverture de la bourse).
3. Transfert de Données et Réseau : Les Coûts Invisibles

De nombreuses entreprises se concentrent sur le calcul et ignorent le coût du mouvement des données, qui peut représenter 20 à 30 % de la facture dans les architectures de microservices.
Optimisation du Trafic Inter-AZ et Inter-Region
Dans une architecture à haute disponibilité, les données voyagent entre différentes Zones de Disponibilité (AZ). AWS et GCP facturent ce trafic.
- Localité du Service : Essayez de maintenir le trafic à l’intérieur de la même AZ lorsque c’est possible. Par exemple, assurez-vous que le microservice A dans l’AZ-1 appelle de préférence l’instance du microservice B dans l’AZ-1.
- VPC Endpoints (PrivateLink) : Évitez de passer par le NAT Gateway pour atteindre des services comme S3 ou DynamoDB. L’utilisation de VPC Endpoints maintient le trafic sur le réseau privé du fournisseur, réduisant les coûts de traitement des données du NAT Gateway (qui sont significatifs pour les volumes élevés) et améliorant la sécurité.
4. Storage Tiering : Gestion du Cycle de Vie de la Donnée Financière
Les réglementations financières (RGPD, PCI-DSS, MiFID II) imposent la conservation des données pendant des années. Tout garder sur un stockage haute performance (ex. S3 Standard) est un gaspillage énorme.
Intelligent Tiering et Politiques de Cycle de Vie
L’optimisation des coûts cloud passe par l’automatisation du cycle de vie de la donnée :
- Hot Data (0-30 jours) : Logs transactionnels récents, données actives. Stockage Standard.
- Warm Data (30-90 jours) : Historique récent pour le service client. Infrequent Access (IA).
- Cold Data (90 jours – 10 ans) : Backups historiques, logs d’audit. Utiliser des classes comme S3 Glacier Deep Archive ou GCP Archive. Le coût est une fraction du standard, mais le temps de récupération est de plusieurs heures (acceptable pour un audit).
- Automatisation : Utiliser S3 Intelligent-Tiering pour déplacer automatiquement les données entre les tiers en fonction des modèles d’accès réels, sans avoir à écrire des scripts complexes.
5. Étude de Cas : Optimisation de l’Infrastructure “FinTechSecure”
Analysons un cas théorique basé sur des scénarios réels de migration et d’optimisation.
Situation Initiale :
La startup “FinTechSecure” gère des paiements P2P. L’infrastructure est sur AWS, entièrement basée sur des instances EC2 On-Demand surdimensionnées pour gérer les pics du Black Friday, avec une base de données RDS Multi-AZ. Coût mensuel : 45 000 $.
Analyse FinOps :
1. Les instances EC2 ont une moyenne d’utilisation CPU de 15 %.
2. Les logs d’accès sont conservés sur S3 Standard indéfiniment.
3. Le trafic de données à travers le NAT Gateway est très élevé à cause des backups vers S3.
Interventions Exécutées :
- Compute : Migration des charges stateless sur conteneurs (EKS) en utilisant des Spot Instances pour 70 % des nœuds et des Savings Plans pour les 30 % restants (nœuds de base). Mise en œuvre de l’auto-scaling basé sur des métriques personnalisées (nombre de transactions en file d’attente).
- Stockage : Activation de la Lifecycle Policy pour déplacer les logs sur Glacier après 30 jours et les supprimer après 7 ans (conformité).
- Réseau : Mise en œuvre de S3 Gateway Endpoint pour éliminer les coûts de NAT Gateway pour le trafic vers le stockage.
Résultat Final :
Le coût mensuel est descendu à 18 500 $ (-59 %), tout en maintenant le même SLA de disponibilité (99,99 %) et en améliorant la vitesse de scaling lors des pics imprévus.
Conclusions

L’optimisation des coûts cloud dans le domaine Fintech n’est pas une activité ponctuelle, mais un processus continu. Elle nécessite d’équilibrer trois variables : coût, vitesse et qualité (redondance/sécurité). Des outils comme les Instances Spot, les politiques de Cycle de Vie et une surveillance granulaire permettent de construire des infrastructures résilientes qui évoluent économiquement avec l’entreprise. Pour l’entrepreneur technique, maîtriser le FinOps signifie libérer des ressources financières à réinvestir dans l’innovation et le développement produit.
Foire aux questions

Le FinOps est un modèle opérationnel culturel qui unit ingénierie, finance et affaires pour optimiser les dépenses cloud. Dans les entreprises Fintech, cette approche est cruciale car elle transforme l infrastructure de simple centre de coûts en actif stratégique, permettant de calculer l impact économique de chaque choix technique (Unit Economics) et garantissant que la scalabilité technologique soit financièrement durable même durant les pics de marché à forte charge.
Bien que les Instances Spot puissent être terminées avec peu de préavis, elles peuvent être utilisées en toute sécurité dans le domaine financier pour des charges de travail tolérantes aux pannes, comme le calcul nocturne des intérêts ou le reporting. La stratégie correcte prévoit la mise en œuvre du checkpointing pour sauvegarder les progrès, l utilisation de flottes mixtes d instances pour diversifier le risque et le maintien de nœuds On-Demand pour l orchestration du cluster.
L auto-scaling basé sur le seul pourcentage de CPU est souvent obsolète pour les plateformes Fintech modernes. Il est préférable d adopter des stratégies agressives basées sur des métriques personnalisées comme la profondeur des files d attente (Queue Depth) des systèmes de messagerie ou le nombre de requêtes par seconde (RPS). De plus, l utilisation de Warm Pools avec des instances pré-initialisées aide à gérer des latences nulles durant l ouverture des marchés ou des événements de trafic soudain.
Les coûts de réseau peuvent représenter jusqu à 30 % de la facture cloud. Pour les réduire, il est nécessaire d optimiser la Localité du Service en maintenant le trafic entre microservices à l intérieur de la même Zone de Disponibilité. De plus, il est fondamental d utiliser des VPC Endpoints (PrivateLink) pour se connecter aux services gérés comme le stockage, évitant ainsi les coûteux frais de traitement de données associés à l utilisation des NAT Gateways publics.
Pour respecter des réglementations comme le RGPD ou PCI-DSS sans gaspiller de budget, il est essentiel de mettre en œuvre le tiering intelligent du stockage. Les données actives (Hot) restent sur le stockage standard, tandis que les logs historiques et les backups (Cold) sont déplacés automatiquement via des Lifecycle Policies sur des classes d archivage profond comme Glacier ou Archive, qui ont des coûts extrêmement réduits mais des temps de récupération plus longs, idéaux pour des audits rares.


Avez-vous trouvé cet article utile ? Y a-t-il un autre sujet que vous aimeriez que je traite ?
Écrivez-le dans les commentaires ci-dessous ! Je m'inspire directement de vos suggestions.