En Bref (TL;DR)
L’adoption du modèle ELT garantit aux institutions Fintech une auditabilité complète et une vitesse de calcul essentielles pour la conformité réglementaire.
L’intégration de Google BigQuery et Apache Airflow assure une ingestion de données évolutive tout en maintenant l’historique des transactions financières inaltéré.
L’utilisation de dbt élève les transformations de données au rang de code logiciel, optimisant la gouvernance et la précision dans le calcul des KPI.
Le diable est dans les détails. 👇 Continuez à lire pour découvrir les étapes critiques et les conseils pratiques pour ne pas vous tromper.
Dans le paysage de l’ingénierie des données de 2026, le choix de l’architecture correcte pour le mouvement des données n’est pas seulement une question de performance, mais de conformité réglementaire, en particulier dans le secteur financier. Lors de la conception d’un pipeline etl vs elt pour une institution Fintech, les enjeux incluent la précision décimale, l’auditabilité complète (Lineage) et la capacité de calculer le risque en temps quasi réel. Ce guide technique explore pourquoi l’approche ELT (Extract, Load, Transform) est devenue la norme de facto par rapport à l’ETL traditionnel, en utilisant une stack moderne composée de Google BigQuery, dbt (data build tool) et Apache Airflow.

ETL vs ELT : Le Changement de Paradigme dans la Fintech
Pendant des années, l’approche ETL (Extract, Transform, Load) a été dominante. Les données étaient extraites des systèmes transactionnels (ex. bases de données de prêts hypothécaires), transformées sur un serveur intermédiaire (staging area) et enfin chargées dans le Data Warehouse. Cette approche, bien que sécurisée, présentait des goulots d’étranglement importants : la puissance de calcul du serveur de transformation limitait la vitesse et chaque modification de la logique métier nécessitait des mises à jour complexes du pipeline avant même que la donnée n’atterrisse dans l’entrepôt.
Avec l’avènement des Cloud Data Warehouses comme Google BigQuery et AWS Redshift, le paradigme s’est déplacé vers l’ELT (Extract, Load, Transform). Dans ce modèle :
- Extract : Les données sont extraites des systèmes sources (CRM, Core Banking).
- Load : Les données sont chargées immédiatement dans le Data Warehouse au format brut (Raw Data).
- Transform : Les transformations ont lieu directement à l’intérieur du Warehouse en exploitant sa puissance de calcul massive (MPP).
Pour la Fintech, l’ELT offre un avantage crucial : l’auditabilité. Puisque les données brutes sont toujours disponibles dans le Warehouse, il est possible de reconstruire l’historique de n’importe quelle transaction ou de recalculer les KPI rétroactivement sans avoir à réexécuter l’extraction.
Architecture de la Solution : La Stack Moderne
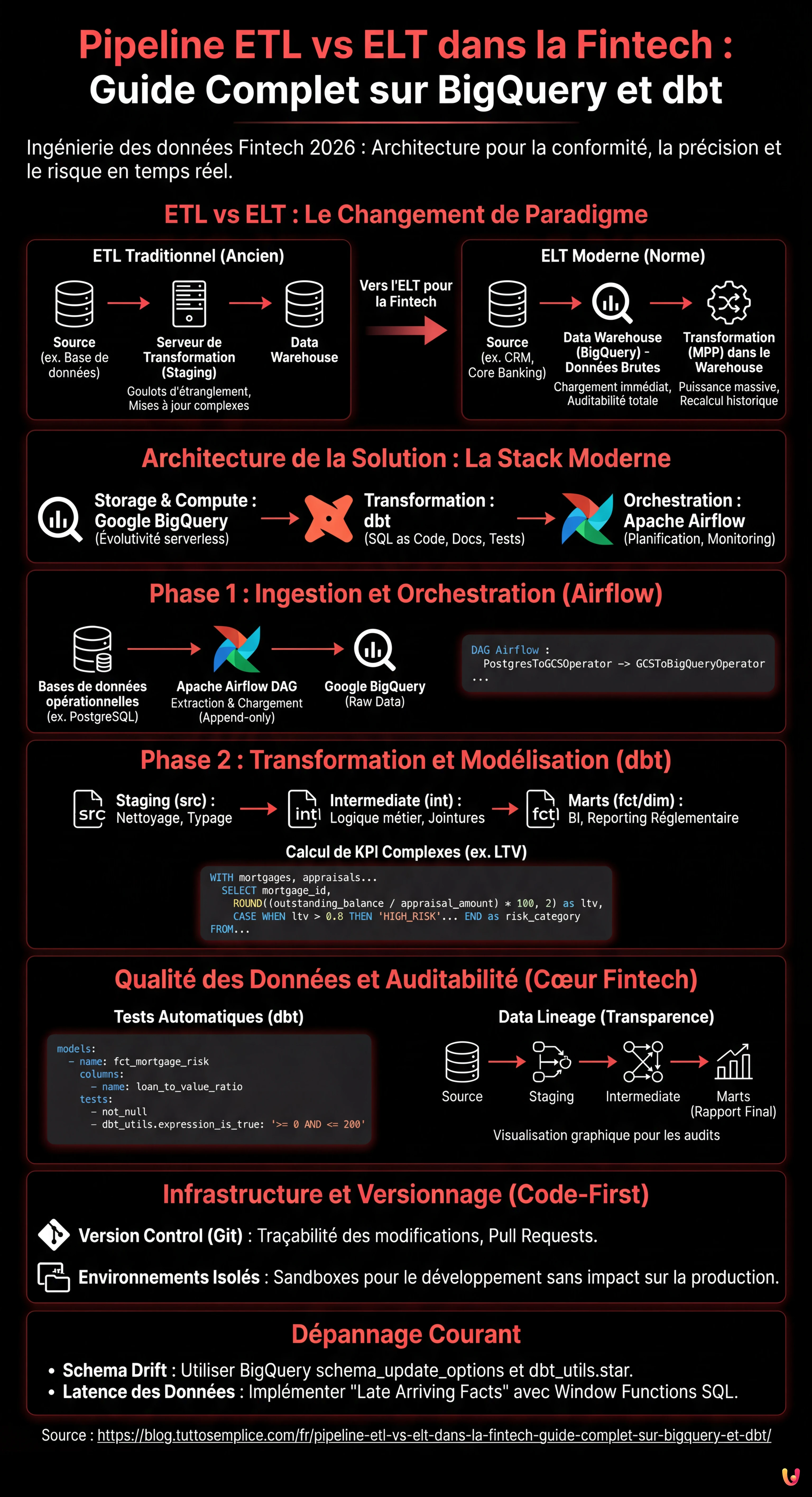
Pour construire un pipeline robuste pour la gestion des prêts hypothécaires, nous utiliserons la stack technologique suivante, considérée comme une bonne pratique en 2026 :
- Storage & Compute : Google BigQuery (pour l’évolutivité serverless).
- Transformation : dbt (pour gérer les transformations SQL, la documentation et les tests).
- Orchestration : Apache Airflow (pour planifier et surveiller les jobs).
Phase 1 : Ingestion et Orchestration avec Apache Airflow

La première étape consiste à amener les données dans le Data Lake/Warehouse. Dans un contexte Fintech, la rapidité est fondamentale. Nous utilisons Apache Airflow pour orchestrer l’extraction depuis les bases de données opérationnelles (ex. PostgreSQL) vers BigQuery.
Exemple de DAG Airflow pour l’Ingestion
L’extrait conceptuel suivant montre comment configurer une tâche pour charger les données des prêts en mode “append-only” afin de conserver l’historique complet.
from airflow import DAG
from airflow.providers.google.cloud.transfers.postgres_to_gcs import PostgresToGCSOperator
from airflow.providers.google.cloud.transfers.gcs_to_bigquery import GCSToBigQueryOperator
from airflow.utils.dates import days_ago
with DAG('fintech_mortgage_ingestion', start_date=days_ago(1), schedule_interval='@hourly') as dag:
extract_mortgages = PostgresToGCSOperator(
task_id='extract_mortgages_raw',
postgres_conn_id='core_banking_db',
sql='SELECT * FROM mortgages WHERE updated_at > {{ prev_execution_date }}',
bucket='fintech-datalake-raw',
filename='mortgages/{{ ds }}/mortgages.json',
)
load_to_bq = GCSToBigQueryOperator(
task_id='load_mortgages_bq',
bucket='fintech-datalake-raw',
source_objects=['mortgages/{{ ds }}/mortgages.json'],
destination_project_dataset_table='fintech_warehouse.raw_mortgages',
write_disposition='WRITE_APPEND', # Crucial pour l'historique
source_format='NEWLINE_DELIMITED_JSON',
)
extract_mortgages >> load_to_bq
Phase 2 : Transformation et Modélisation avec dbt
Une fois les données dans BigQuery, dbt entre en jeu. Contrairement aux procédures stockées traditionnelles, dbt permet de traiter les transformations de données comme du code logiciel (bonnes pratiques de génie logiciel), incluant le versionnage (Git), les tests et le CI/CD.
Structure du Projet dbt
Nous organisons les modèles en trois couches logiques :
- Staging (src) : Nettoyage léger, renommage des colonnes, typage des données.
- Intermediate (int) : Logique métier complexe, jointures entre tables.
- Marts (fct/dim) : Tables finales prêtes pour la BI et le reporting réglementaire.
Calcul de KPI Complexes : Loan-to-Value (LTV) en SQL
Dans le secteur des prêts hypothécaires, le LTV est un indicateur de risque critique. Voici à quoi ressemble un modèle dbt (fichier .sql) qui calcule le LTV mis à jour et classe le risque, en unissant les données clients et les évaluations immobilières.
-- models/marts/risk/fct_mortgage_risk.sql
WITH mortgages AS (
SELECT * FROM {{ ref('stg_core_mortgages') }}
),
appraisals AS (
-- Nous prenons la dernière évaluation disponible pour le bien
SELECT
property_id,
appraisal_amount,
appraisal_date,
ROW_NUMBER() OVER (PARTITION BY property_id ORDER BY appraisal_date DESC) as rn
FROM {{ ref('stg_external_appraisals') }}
)
SELECT
m.mortgage_id,
m.customer_id,
m.outstanding_balance,
a.appraisal_amount,
-- Calcul LTV : (Solde Restant / Valeur Bien) * 100
ROUND((m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) * 100, 2) as loan_to_value_ratio,
CASE
WHEN (m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) > 0.80 THEN 'HIGH_RISK'
WHEN (m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) BETWEEN 0.50 AND 0.80 THEN 'MEDIUM_RISK'
ELSE 'LOW_RISK'
END as risk_category,
CURRENT_TIMESTAMP() as calculated_at
FROM mortgages m
LEFT JOIN appraisals a ON m.property_id = a.property_id AND a.rn = 1
WHERE m.status = 'ACTIVE'
Qualité des Données et Auditabilité : Le Cœur de la Fintech
Dans le domaine financier, une donnée erronée peut entraîner des sanctions. L’approche ELT avec dbt excelle dans la Data Quality grâce aux tests intégrés.
Mise en œuvre des Tests Automatiques
Dans le fichier schema.yml de dbt, nous définissons les assertions que les données doivent satisfaire. Si un test échoue, le pipeline s’arrête ou envoie une alerte, empêchant la propagation de données corrompues.
version: 2
models:
- name: fct_mortgage_risk
description: "Table de faits pour le risque hypothécaire"
columns:
- name: mortgage_id
tests:
- unique
- not_null
- name: loan_to_value_ratio
tests:
- not_null
# Test personnalisé : Le LTV ne peut pas être négatif ou absurdement élevé (>200%)
- dbt_utils.expression_is_true:
expression: ">= 0 AND <= 200"
Data Lineage
dbt génère automatiquement un graphe de dépendances (DAG). Pour un auditeur, cela signifie pouvoir visualiser graphiquement comment la donnée “Risque Élevé” d’un client a été dérivée : de la table brute, à travers les transformations intermédiaires, jusqu’au rapport final. Ce niveau de transparence est souvent obligatoire lors des inspections bancaires.
Gestion de l’Infrastructure et Versionnage
Contrairement aux pipelines ETL hérités basés sur des GUI (interfaces graphiques drag-and-drop), l’approche moderne est Code-First.
- Version Control (Git) : Chaque modification de la logique de calcul du LTV est un commit sur Git. Nous pouvons savoir qui a changé la formule, quand et pourquoi (via la Pull Request).
- Environnements Isolés : Grâce à dbt, chaque développeur peut exécuter le pipeline dans un environnement sandbox (ex.
dbt run --target dev) sur un sous-ensemble de données BigQuery, sans impacter la production.
Dépannage Courant
1. Schema Drift (Changement du schéma source)
Problème : Le Core Banking ajoute une colonne à la table des prêts et le pipeline se casse.
Solution : Dans BigQuery, utiliser l’option schema_update_options=['ALLOW_FIELD_ADDITION'] lors du chargement. Dans dbt, utiliser des paquets comme dbt_utils.star pour sélectionner dynamiquement les colonnes ou implémenter des tests de schéma rigoureux qui avertissent du changement sans rompre le flux critique.
2. Latence des Données
Problème : Les données des évaluations immobilières arrivent en retard par rapport aux soldes des prêts.
Solution : Implémenter la logique de “Late Arriving Facts”. Utiliser les Window Functions SQL (comme vu dans l’exemple ci-dessus avec ROW_NUMBER) pour prendre toujours la dernière donnée valide disponible au moment de l’exécution, ou modéliser des tables snapshot pour historiser l’état exact en fin de mois.
Conclusions

La transition d’un pipeline etl vs elt dans le secteur Fintech n’est pas une mode, mais une nécessité opérationnelle. L’utilisation de BigQuery pour le stockage à faible coût et la haute capacité de calcul, combinée à dbt pour la gouvernance des transformations, permet aux entreprises financières d’avoir des données fiables, auditables et opportunes. Mettre en œuvre cette architecture nécessite des compétences en génie logiciel appliquées aux données, mais le retour sur investissement en termes de conformité et d’agilité commerciale est incalculable.
Foire aux questions

La distinction principale concerne le moment de la transformation des données. Dans le modèle ETL, les données sont traitées avant le chargement, tandis que dans le paradigme ELT, les données brutes sont chargées immédiatement dans le Data Warehouse et transformées par la suite. Dans la Fintech, la méthode ELT est préférée car elle garantit une auditabilité totale et permet de recalculer les KPI historiques sans réexécuter l’extraction depuis les systèmes sources.
Cette combinaison constitue la norme actuelle grâce à l’évolutivité serverless de Google BigQuery et à la capacité de dbt à gérer les transformations SQL comme du code logiciel. Leur utilisation conjointe permet d’exploiter la puissance de calcul du cloud pour traiter des volumes massifs de données financières, tout en assurant le versionnage, les tests automatiques et une documentation claire de la logique métier.
Le modèle ELT facilite la conformité en conservant les données brutes originales dans le Data Warehouse, rendant possible la reconstruction de l’historique de chaque transaction à tout moment. De plus, des outils comme dbt génèrent automatiquement un graphe de dépendances, connu sous le nom de Data Lineage, qui permet aux auditeurs de visualiser exactement comment une donnée finale a été dérivée de la source lors des inspections réglementaires.
L’intégrité de la donnée est assurée par des tests automatiques intégrés dans le code de transformation, qui vérifient l’unicité et la cohérence des valeurs. En définissant des règles spécifiques dans le fichier de configuration, le pipeline peut bloquer le processus ou envoyer des alertes immédiates s’il détecte des anomalies, prévenant la propagation d’erreurs dans les rapports décisionnels ou réglementaires.
Le calcul des indicateurs de risque est géré par des modèles SQL modulaires au sein du Data Warehouse, unissant les données clients et les évaluations immobilières. Grâce à la méthode ELT, il est possible d’implémenter des logiques qui historisent le risque et gèrent les retards de données, assurant que le calcul reflète toujours l’information la plus valide et à jour disponible au moment de l’exécution.
Sources et Approfondissements

- Définition et fonctionnement de l’architecture ELT sur Wikipédia
- Banque des Règlements Internationaux : Principes pour l’agrégation des données sur les risques (BCBS 239)
- Site officiel de la Fondation Apache pour l’orchestrateur Airflow
- Guide de la CNIL sur la sécurité et la traçabilité des données personnelles

Avez-vous trouvé cet article utile ? Y a-t-il un autre sujet que vous aimeriez que je traite ?
Écrivez-le dans les commentaires ci-dessous ! Je m'inspire directement de vos suggestions.