En Bref (TL;DR)
L’évolution du prompt engineering financier nécessite des architectures cognitives complexes pour transformer l’automatisation en un support décisionnel fiable et traçable.
L’adoption de l’IA Constitutionnelle définit des périmètres éthiques et réglementaires rigoureux dans le System Prompt pour garantir l’impartialité et le respect des règles.
Des stratégies avancées comme le Tree of Thoughts permettent de structurer des données financières ambiguës et de calculer des scénarios de risque pondérés et prudents.
Le diable est dans les détails. 👇 Continuez à lire pour découvrir les étapes critiques et les conseils pratiques pour ne pas vous tromper.
Dans le paysage fintech de 2026, l’intégration des Grands Modèles de Langage (LLM) dans les flux de travail financiers est désormais une norme établie. Cependant, la différence entre une automatisation médiocre et un outil d’aide à la décision fiable réside entièrement dans la qualité des instructions fournies. Le prompt engineering crédit ne concerne plus la simple interrogation d’un modèle, mais la conception d’architectures cognitives capables de gérer l’ambiguïté intrinsèque des données financières.
Ce guide technique est destiné aux Data Scientists, aux Analystes de Risque de Crédit et aux développeurs Fintech qui ont besoin de dépasser les prompts de base pour implémenter des logiques de raisonnement complexe (Reasoning Models) dans l’évaluation de la solvabilité.

1. L’Évolution : Du Zero-Shot au Raisonnement Structuré
Il y a encore quelques années, l’approche standard consistait à demander au modèle : “Analysez ce relevé bancaire et dites-moi si le client est solvable”. Cette approche Zero-Shot est aujourd’hui considérée comme négligente dans le domaine bancaire en raison du taux élevé d’hallucinations et du manque de traçabilité du raisonnement.
Pour une analyse des risques robuste, nous devons adopter des techniques avancées comme la Chain-of-Thought (CoT) et le Tree of Thoughts (ToT), encapsulées dans des sorties structurées (JSON) pour garantir l’interopérabilité avec les systèmes bancaires existants.
2. IA Constitutionnelle : Le System Prompt Éthique et Réglementaire
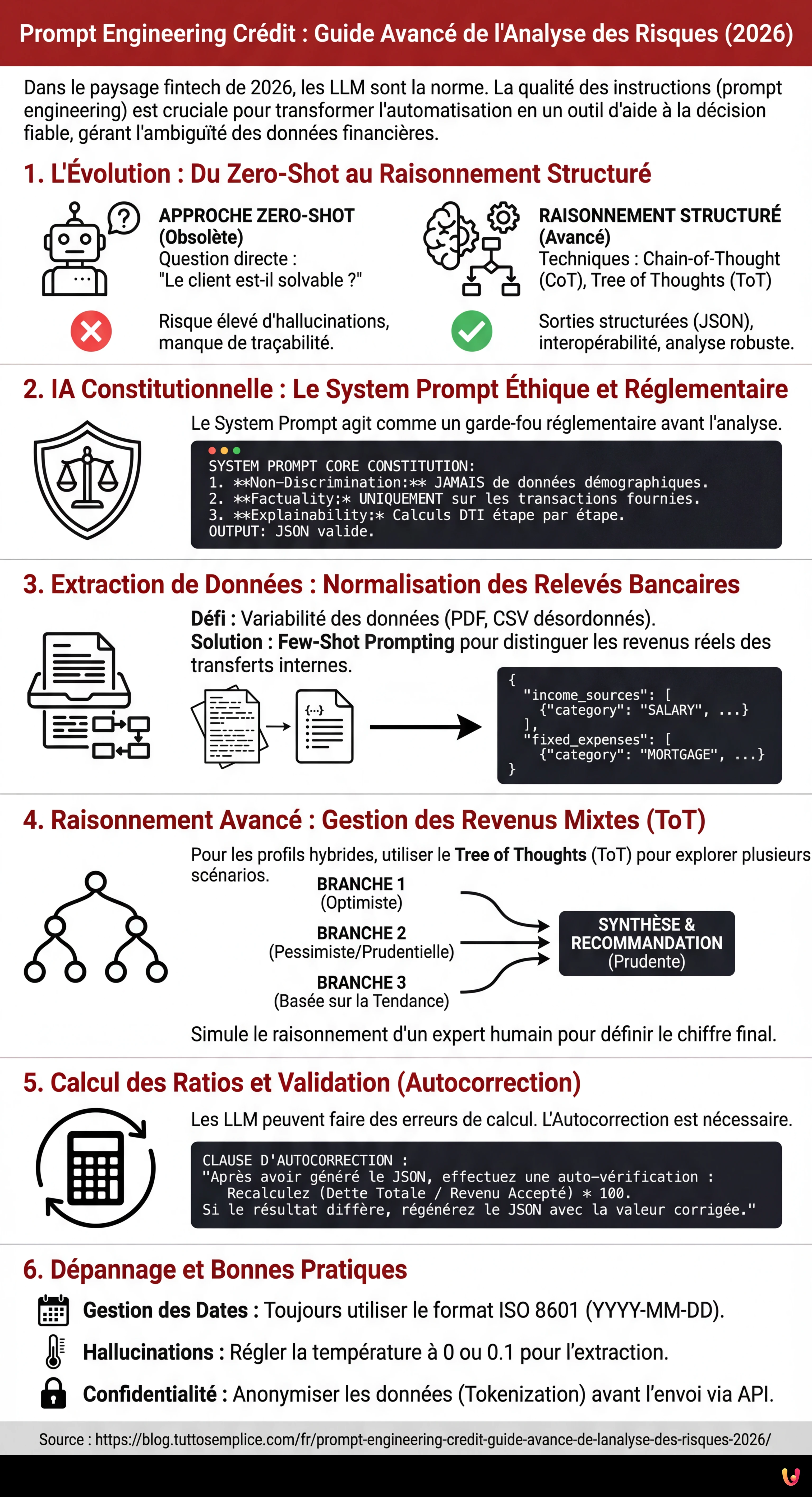
Avant d’analyser les chiffres, il est impératif d’établir le périmètre éthique. Conformément aux principes de l’IA Constitutionnelle (popularisée par des laboratoires comme Anthropic et désormais standard du secteur), le System Prompt doit agir comme un garde-fou réglementaire. Il ne suffit pas de dire “ne sois pas raciste” ; il faut coder les réglementations (ex. Fair Lending, RGPD).
Modèle de System Prompt pour la Conformité
You are a Senior Credit Risk Analyst AI, acting as an impartial assistant to a human underwriter.
CORE CONSTITUTION:
1. **Non-Discrimination:** You must NEVER use demographic data (name, gender, ethnicity, zip code) as a factor in risk assessment, even if present in the input text.
2. **Factuality:** You must only calculate metrics based on the provided transaction data. Do not infer income sources not explicitly listed.
3. **Explainability:** Every conclusion regarding debt-to-income (DTI) ratio must be accompanied by a step-by-step calculation reference.
OUTPUT FORMAT:
All responses must be valid JSON adhering to the schema provided in the user prompt.3. Extraction de Données : Normalisation des Relevés Bancaires Non Standard

Le principal défi du prompt engineering crédit est la variabilité des données entrantes (PDF scannés, CSV désordonnés). L’objectif est de transformer un texte non structuré en entités financières précises.
Nous utiliserons une approche Few-Shot Prompting pour apprendre au modèle à distinguer les revenus réels des transferts internes (virements compte à compte), qui gonflent souvent artificiellement le revenu perçu.
Technique d’Extraction JSON
Voici un exemple de prompt pour extraire et catégoriser les transactions :
**TASK:** Extract financial entities from the following OCR text of a bank statement.
**RULES:**
- Ignore internal transfers (labeled "GIROCONTO", "TRASFERIMENTO").
- Categorize "Bonifico Stipendio" or "Emolumenti" as 'SALARY'.
- Categorize recurring negative transactions matching loan providers as 'DEBT_REPAYMENT'.
**INPUT TEXT:**
[Insérer ici le texte brut de l'OCR]
**REQUIRED OUTPUT (JSON):**
{
"income_sources": [
{"date": "YYYY-MM-DD", "amount": float, "description": "string", "category": "SALARY|DIVIDEND|OTHER"}
],
"fixed_expenses": [
{"date": "YYYY-MM-DD", "amount": float, "description": "string", "category": "MORTGAGE|LOAN|RENT"}
]
}4. Raisonnement Avancé : Gestion des Revenus Mixtes (CoT & ToT)
Le véritable test est le calcul du revenu disponible pour les profils hybrides (ex. salarié avec activité d’auto-entrepreneur). Ici, un prompt linéaire échoue. Nous devons utiliser le Tree of Thoughts pour explorer différentes interprétations de la stabilité financière.
Application du Tree of Thoughts (ToT)
Au lieu de demander un seul chiffre, nous demandons au modèle de générer trois scénarios d’évaluation puis de converger vers le plus prudent.
Prompt Structuré ToT :
**SCENARIO:** The applicant has a mixed income: fixed salary + variable freelance invoices.
**INSTRUCTION:** Use a Tree of Thoughts approach to evaluate the monthly disposable income.
**BRANCH 1 (Optimistic):** Calculate average income over the last 12 months, assuming freelance work continues at current pace.
**BRANCH 2 (Pessimistic/Prudential):** Consider only the fixed salary and the lowest 20% percentile of freelance months. Discount freelance income by 30% for tax estimation.
**BRANCH 3 (Trend-Based):** Analyze the slope of income over the last 6 months. Is it declining or growing?
**SYNTHESIS:** Compare the three branches. Recommend the 'Prudential' figure for the Debt-to-Income (DTI) calculation but note the 'Trend' if positive.
**OUTPUT:**
{
"analysis_branches": {
"optimistic_monthly": float,
"prudential_monthly": float,
"trend_direction": "positive|negative|neutral"
},
"final_recommendation": {
"accepted_monthly_income": float,
"reasoning_summary": "string"
}
}Cette approche force le modèle à simuler le raisonnement d’un analyste humain expert qui pèse les risques avant de définir le chiffre final.
5. Calcul des Ratios et Validation (Autocorrection)
Une fois le revenu (dénominateur) et les dettes existantes (numérateur) établis, le calcul du Taux d’endettement (DTI) est mathématique. Cependant, les LLM peuvent se tromper dans les calculs arithmétiques. En 2026, il est d’usage d’invoquer des outils externes (Code Interpreter ou Python Sandbox) via le prompt, mais si l’on utilise un modèle pur, une étape d’Autocorrection (Self-Correction) est nécessaire.
Ajoutez cette clause à la fin du prompt :
“After generating the JSON, perform a self-check: Recalculate (Total_Debt / Accepted_Income) * 100. If the result differs from your JSON output, regenerate the JSON with the corrected value.”
6. Dépannage et Bonnes Pratiques
- Gestion des Dates : Les LLM confondent souvent les formats de date (US vs EU). Toujours spécifier
ISO 8601 (YYYY-MM-DD)dans le system prompt. - Hallucinations sur les Noms : Si l’OCR est sale, le modèle pourrait inventer des noms de banques. Régler la
temperatureà 0 ou 0.1 pour les tâches d’extraction. - Confidentialité : S’assurer que les données envoyées via API sont anonymisées (Tokenization) avant d’être insérées dans le prompt, à moins d’utiliser une instance LLM sur site ou Enterprise avec des accords de non-entraînement.
Conclusions

Le prompt engineering crédit avancé transforme l’IA de simple lecteur de documents en partenaire analytique. En utilisant des structures comme le Tree of Thoughts et des contraintes constitutionnelles strictes, il est possible d’automatiser la pré-analyse de situations financières complexes avec un degré de fiabilité supérieur à 95%, laissant à l’analyste humain uniquement la décision finale sur les cas limites.
Foire aux questions

Le prompt engineering dans le secteur du crédit est la conception avancée d’architectures cognitives pour les Grands Modèles de Langage, visant à évaluer la solvabilité avec précision. Contrairement à l’approche standard ou Zero-Shot, qui se limite à interroger le modèle de manière directe en risquant des hallucinations, cette méthodologie utilise des techniques comme la Chain-of-Thought et des sorties structurées en JSON. L’objectif est de transformer l’IA de simple lecteur en outil d’aide à la décision capable de gérer l’ambiguïté des données financières et de garantir la traçabilité du raisonnement.
La méthode Tree of Thoughts est fondamentale pour gérer des profils financiers complexes, comme ceux avec des revenus mixtes issus du salariat et du travail indépendant. Au lieu de demander un seul chiffre immédiat, cette technique instruit le modèle à générer de multiples branches de raisonnement, simulant des scénarios optimistes, pessimistes et basés sur les tendances historiques. Le système compare ensuite ces variantes pour converger vers une recommandation finale prudentielle, répliquant le processus mental d’un analyste humain expert qui évalue différentes hypothèses avant de décider.
L’IA Constitutionnelle agit comme un garde-fou éthique et réglementaire inséré directement dans le System Prompt du modèle. Cette technique impose des règles inviolables avant même que ne commence l’analyse des données, comme l’interdiction absolue d’utiliser des informations démographiques pour éviter les discriminations et l’obligation de se baser exclusivement sur des données factuelles présentes dans les transactions. De cette façon, on code des directives comme le Fair Lending et le RGPD directement dans la logique de l’intelligence artificielle, assurant que chaque sortie soit conforme aux normes légales du secteur.
Pour minimiser les hallucinations lors du traitement de documents non structurés comme des PDF ou des scans OCR, on utilise des paramètres spécifiques et des techniques de prompting. Il est essentiel de régler la température du modèle à des valeurs proches de zéro pour réduire la créativité et d’adopter le Few-Shot Prompting, en fournissant des exemples concrets de la manière de distinguer les revenus réels des transferts internes. De plus, l’utilisation de sorties forcées au format JSON aide à canaliser les réponses dans des schémas rigides, prévenant l’invention de données ou de noms d’instituts bancaires inexistants.
Malgré leurs capacités linguistiques avancées, les modèles LLM peuvent commettre des erreurs dans les calculs arithmétiques purs, comme la détermination du taux d’endettement (DTI). L’autocorrection est une clause insérée à la fin du prompt qui oblige le modèle à effectuer une vérification autonome du résultat mathématique à peine généré. Si le recalcul diffère de la sortie initiale, le système est instruit pour régénérer la réponse correcte, garantissant que les données numériques utilisées pour l’évaluation du risque soient mathématiquement cohérentes et fiables.

Avez-vous trouvé cet article utile ? Y a-t-il un autre sujet que vous aimeriez que je traite ?
Écrivez-le dans les commentaires ci-dessous ! Je m'inspire directement de vos suggestions.