En Bref (TL;DR)
La transformation de documents non structurés en données exploitables via le prompt engineering constitue désormais le pilier d’un credit scoring performant.
L’utilisation de stratégies comme le Chain-of-Thought et le Few-Shot garantit une extraction précise des données financières malgré l’ambiguïté des formats.
Des pipelines robustes combinant OCR intelligent et validation stricte permettent de minimiser les hallucinations et d’automatiser l’évaluation des risques bancaires.
Le diable est dans les détails. 👇 Continuez à lire pour découvrir les étapes critiques et les conseils pratiques pour ne pas vous tromper.
Dans le paysage fintech de 2026, la capacité à transformer des documents non structurés en données exploitables est devenue le principal facteur discriminant entre un processus de credit scoring efficace et un processus obsolète. Le prompt engineering financier n’est plus une simple compétence accessoire, mais une composante critique de l’architecture logicielle bancaire. Ce guide technique explore comment concevoir des pipelines IA robustes pour l’extraction de données à partir de fiches de paie, de bilans XBRL/PDF et de relevés bancaires, en minimisant les risques opérationnels.

Le Problème des Données Non Structurées dans le Credit Scoring
Malgré l’évolution des normes numériques, une part significative de la documentation nécessaire à l’instruction d’un crédit (notamment pour les PME et les particuliers) arrive encore sous des formats non structurés : PDF scannés, images ou fichiers texte désordonnés. L’objectif est de convertir ce chaos en un objet JSON validé pouvant alimenter directement les algorithmes d’évaluation des risques.
Les principaux défis incluent :
- Ambiguïté Sémantique : Distinguer entre « Revenu Brut » et « Revenu Imposable » dans des fiches de paie aux mises en page propriétaires.
- Hallucinations Numériques : La tendance des LLM à inventer des chiffres ou à se tromper dans les calculs s’ils ne sont pas correctement instruits.
- Bruit de l’OCR : Erreurs de lecture (ex. confondre un ‘0’ avec un ‘O’ ou un ‘8’ avec un ‘B’).
Architecture du Pipeline d’Extraction
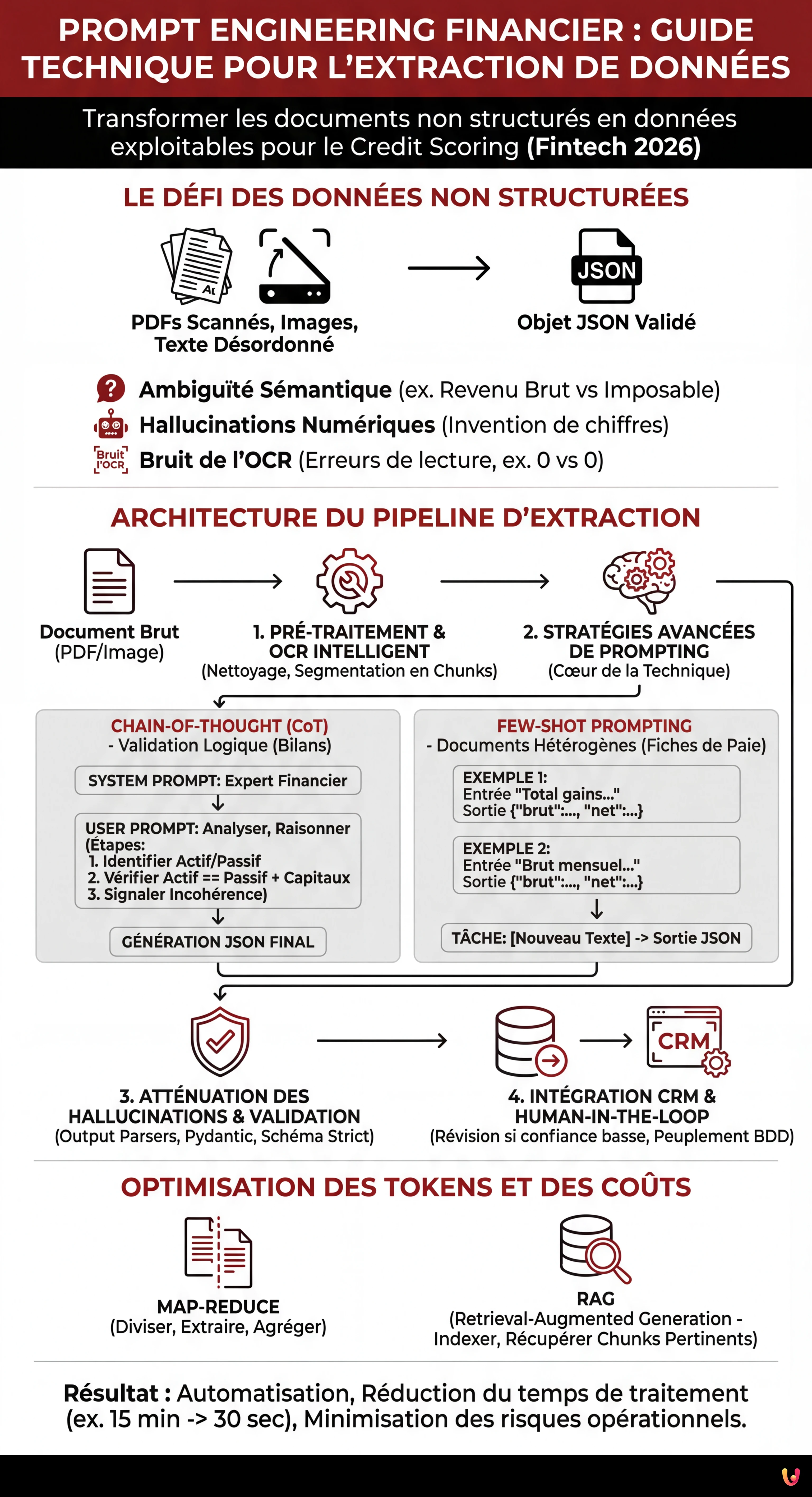
Pour construire un système fiable, il ne suffit pas d’envoyer un PDF à un modèle comme GPT-4o ou Claude. Une orchestration complexe est nécessaire, généralement gérée via des frameworks comme LangChain ou LlamaIndex.
1. Pré-traitement et OCR Intelligent
Avant d’appliquer toute technique de prompt engineering financier, le document doit être « nettoyé ». L’utilisation d’OCR avancés est obligatoire. À ce stade, il est utile de segmenter le document en chunks logiques (ex. « En-tête », « Corps du Tableau », « Totaux ») pour éviter de saturer la fenêtre contextuelle du modèle avec du bruit inutile.
2. Stratégies Avancées de Prompting
C’est ici que réside le cœur de la technique. Un prompt générique comme « Extrais les données » échouera dans 90 % des cas complexes. Voici les méthodologies gagnantes :
Chain-of-Thought (CoT) pour la Validation Logique
Pour les bilans d’entreprise, il est fondamental que le modèle « raisonne » avant de répondre. En utilisant le CoT, nous forçons le LLM à expliciter les étapes intermédiaires.
SYSTEM PROMPT:
Vous êtes un expert en analyse financière. Votre tâche est d'extraire les données du bilan.
USER PROMPT:
Analysez le texte fourni. Avant de générer le JSON final, effectuez ces étapes :
1. Identifiez le Total Actif et le Total Passif.
2. Vérifiez si Actif == Passif + Capitaux Propres.
3. Si les comptes ne correspondent pas, signalez l'incohérence dans le champ 'warning'.
4. Ce n'est qu'à la fin que vous générez la sortie JSON.Few-Shot Prompting pour Fiches de Paie Hétérogènes
Les fiches de paie varient énormément d’un employeur à l’autre. Le Few-Shot Prompting consiste à fournir au modèle des exemples d’entrée (texte brut) et de sortie souhaitée (JSON) au sein même du prompt. Cela « entraîne » le modèle in-context à reconnaître des modèles spécifiques sans nécessiter de fine-tuning.
EXEMPLE 1:
Entrée : "Total gains : 2.500,00 euros. Net dans l'enveloppe : 1.850,00."
Sortie : {"brut": 2500.00, "net": 1850.00}
EXEMPLE 2:
Entrée : "Brut mensuel : € 3.000. Retenues totales : € 800. Net à payer : € 2.200."
Sortie : {"brut": 3000.00, "net": 2200.00}
TÂCHE:
Entrée : [Nouveau Texte Fiche de Paie]...Atténuation des Hallucinations et Validation

Dans le domaine financier, une hallucination (inventer un nombre) est inacceptable. Pour atténuer ce risque, nous implémentons une validation stricte en post-traitement.
Output Parsers et Pydantic
En utilisant des bibliothèques comme Pydantic en Python, nous pouvons définir un schéma strict que le modèle doit respecter. Si le LLM génère un champ « date » dans un format incorrect ou une chaîne au lieu d’un flottant, le validateur lève une exception et, via un mécanisme de retry, demande au modèle de se corriger.
Intégration CRM : L’Expérience BOMA
L’application pratique de ces techniques trouve sa plus haute expression dans l’intégration avec des systèmes propriétaires. Dans le contexte du projet BOMA (Back Office Management Automation), l’intégration du pipeline IA a suivi ces étapes :
- Ingestion : Le CRM reçoit le document par e-mail ou téléchargement.
- Orchestration : Un webhook active le pipeline LangChain.
- Extraction & Validation : Le LLM extrait les données et Pydantic les valide.
- Human-in-the-loop : Si le score de confiance est bas, le système crée une tâche dans le CRM pour une révision manuelle, en mettant en évidence les champs suspects.
- Peuplement : Les données validées remplissent automatiquement les champs de la BDD, réduisant le temps de saisie de 15 minutes à 30 secondes par dossier.
Optimisation des Tokens et des Coûts
Gérer la fenêtre de tokens est essentiel pour maintenir les coûts des API à un niveau durable, surtout avec des bilans de centaines de pages.
- Map-Reduce : Au lieu de passer tout le document en une fois, on divise le texte en sections, on extrait les données partielles et on demande à un second prompt de les agréger.
- RAG (Retrieval-Augmented Generation) : Pour les documents très étendus, on indexe le texte dans une base de données vectorielle et on ne récupère que les chunks pertinents (ex. uniquement les pages relatives au « Compte de Résultat ») à passer au modèle.
Conclusions

Le prompt engineering financier est une discipline qui exige de la rigueur. Il ne s’agit pas seulement de savoir « parler » à l’IA, mais de construire une infrastructure de contrôle autour d’elle. Grâce à l’utilisation combinée du Chain-of-Thought, du Few-Shot Prompting et des validateurs de schéma, il est possible d’automatiser l’analyse du risque de crédit avec un niveau de précision qui, en 2026, rivalise avec, et dépasse souvent, la précision humaine.
Foire aux questions

Le prompt engineering financier est une discipline technique axée sur la conception d instructions précises pour les modèles d intelligence artificielle, visant à transformer des documents non structurés comme les fiches de paie et les bilans en données structurées. Dans le secteur fintech, cette compétence est devenue cruciale pour automatiser le credit scoring, permettant de convertir des formats chaotiques comme les PDF et les scans en objets JSON validés, réduisant ainsi considérablement les temps de traitement et les risques opérationnels.
Pour empêcher les modèles linguistiques d inventer des chiffres ou de commettre des erreurs de calcul, il est nécessaire d implémenter une validation stricte en post-traitement à l aide de bibliothèques comme Pydantic, qui imposent un schéma fixe à la sortie. De plus, l utilisation de stratégies de prompting comme le Chain-of-Thought oblige le modèle à expliciter les étapes logiques intermédiaires, comme vérifier que le total actif correspond au passif plus les capitaux propres, avant de générer le résultat final.
Les techniques varient selon le type de document. Pour les bilans d entreprise, qui exigent une cohérence logique, le Chain-of-Thought est préférable car il guide le raisonnement du modèle. Pour des documents hétérogènes comme les fiches de paie, le Few-Shot Prompting est plus efficace ; il consiste à fournir au modèle des exemples concrets d entrée et de sortie souhaitée au sein même du prompt, l aidant à reconnaître des modèles spécifiques sans nécessiter de nouvel entraînement.
Pour les documents étendus qui risquent de saturer la mémoire du modèle ou d augmenter les coûts, on utilise des techniques d optimisation des tokens. L approche Map-Reduce divise le document en sections plus petites pour des extractions partielles ensuite agrégées. Alternativement, la technique RAG (Retrieval-Augmented Generation) permet de récupérer et d analyser uniquement les fragments de texte réellement pertinents, comme les tableaux spécifiques d un bilan, en ignorant les parties inutiles.
L OCR intelligent représente la première étape fondamentale pour nettoyer le document avant l analyse IA. Comme de nombreux documents arrivent sous forme de scans ou d images, un OCR avancé est nécessaire pour convertir ces fichiers en texte lisible et les segmenter en blocs logiques. Cela réduit le bruit causé par les erreurs de lecture et prépare le terrain pour un prompt engineering efficace, évitant que le modèle ne soit confus par des données désordonnées.
Sources et Approfondissements

- ACPR (Banque de France) : L’intelligence artificielle dans le secteur financier
- Commission européenne : Le cadre juridique sur l’IA et le credit scoring (Haut Risque)
- Wikipedia : Comprendre le standard XBRL pour les rapports financiers
- CNIL : Intelligence artificielle et protection des données personnelles
- Wikipedia : Définition et concepts du Prompt Engineering

Avez-vous trouvé cet article utile ? Y a-t-il un autre sujet que vous aimeriez que je traite ?
Écrivez-le dans les commentaires ci-dessous ! Je m'inspire directement de vos suggestions.