Em Resumo (TL;DR)
A arquitetura RAG revoluciona a análise financeira transformando políticas complexas em conhecimento imediato, reduzindo os tempos de verificação de horas para segundos.
Uma pipeline robusta necessita de chunking semântico avançado para gerir tabelas e estruturas legais típicas dos documentos bancários não estruturados.
A precisão das respostas é assegurada por prompts que previnem alucinações e impõem referências verificáveis às fontes normativas originais.
O diabo está nos detalhes. 👇 Continue lendo para descobrir os passos críticos e as dicas práticas para não errar.
No panorama financeiro atual, a velocidade de processamento da informação tornou-se uma vantagem competitiva crucial. Para as sociedades de mediação de crédito e bancos, o principal desafio não é a falta de dados, mas a sua fragmentação em documentos não estruturados. A implementação de uma arquitetura RAG fintech (Retrieval-Augmented Generation) representa a solução definitiva para transformar manuais operacionais e políticas de concessão de crédito habitação em conhecimento acionável.
Imaginem um cenário comum: um intermediário deve verificar a viabilidade de um crédito habitação para um cliente com rendimentos estrangeiros consultando as políticas de 20 instituições diferentes. Manualmente, isto requer horas. Com um sistema RAG bem concebido, como demonstrado pela evolução de plataformas CRM avançadas tipo BOMA, o tempo reduz-se a poucos segundos. Contudo, o setor financeiro não tolera erros: uma alucinação do modelo de linguagem (LLM) pode levar a uma deliberação errada e riscos de compliance.
Este guia técnico explora como construir uma pipeline RAG robusta, focando-se nas especificidades do domínio bancário: desde a gestão de PDFs complexos à citação rigorosa das fontes.

Pipeline de Ingestão: Do PDF ao Vetor
O coração de uma arquitetura RAG fintech eficaz reside na qualidade dos dados de entrada. As políticas bancárias são frequentemente distribuídas em formato PDF, ricas em tabelas (ex: grelhas LTV/Rendimento), notas de rodapé e cláusulas legais interdependentes. Um simples parser de texto falharia em preservar a estrutura lógica necessária.
Estratégias de Chunking Semântico
Dividir o texto em segmentos (chunking) é um passo crítico. No contexto creditício, cortar um parágrafo ao meio pode alterar o significado de uma regra de exclusão. Segundo as best practices atuais para o processamento documental:
- Chunking Hierárquico: Em vez de dividir por número fixo de tokens, é essencial respeitar a estrutura do documento (Título, Artigo, Alínea). Utilizar bibliotecas como LangChain ou LlamaIndex permite configurar splitters que reconhecem os cabeçalhos dos documentos legais.
- Overlap Contextual: É aconselhável manter uma sobreposição (overlap) de 15-20% entre os chunks para garantir que o contexto não se perca nas margens do corte.
- Gestão de Tabelas: As tabelas devem ser extraídas, linearizadas em formato markdown ou JSON e incorporadas como unidades semânticas únicas. Se uma tabela for quebrada, o modelo não será capaz de associar corretamente linhas e colunas durante a fase de retrieval.
Escolha da Base de Dados Vetorial: Pinecone vs pgvector
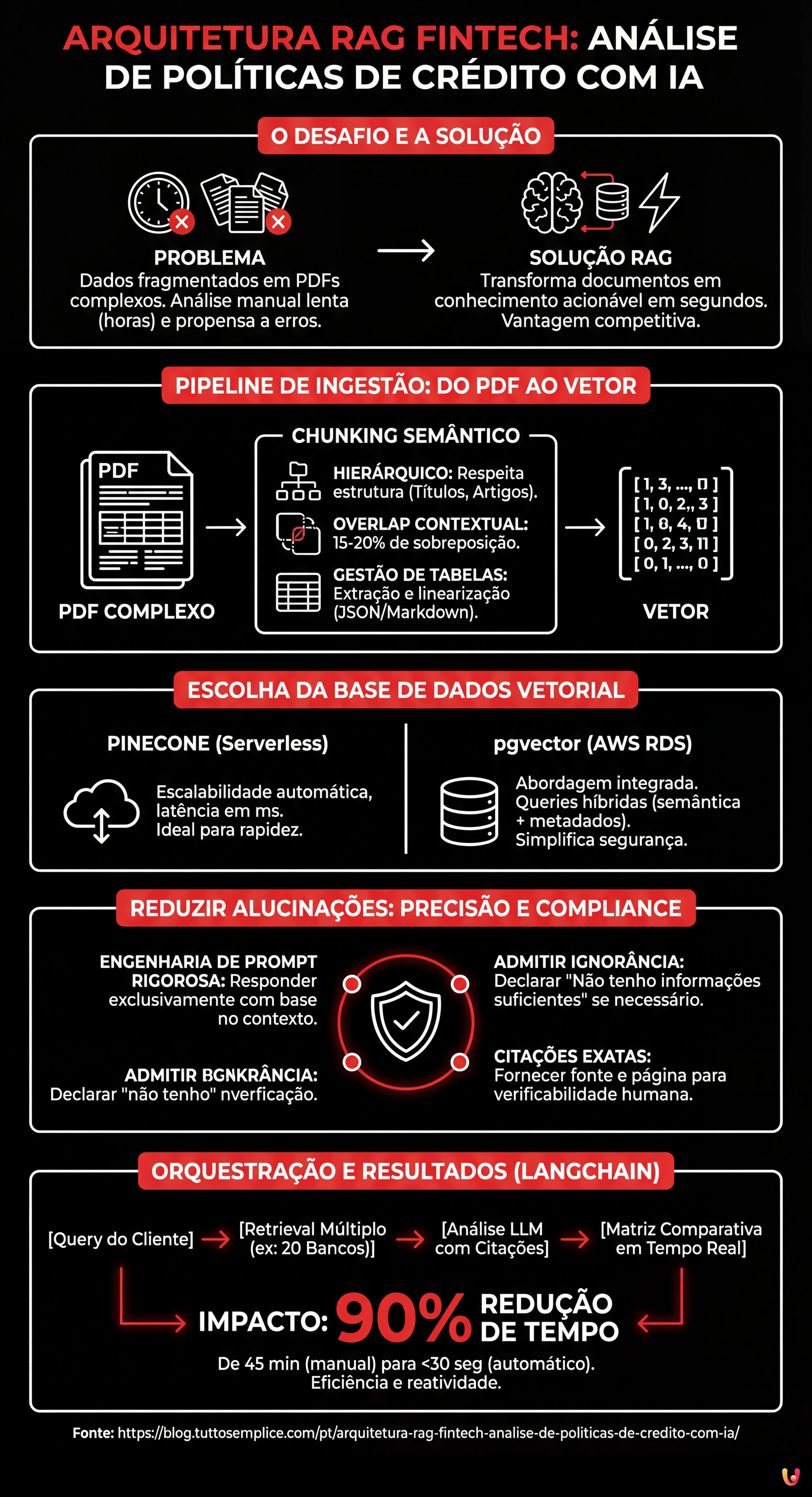
Uma vez transformados os chunks em vetores numéricos (embedding), é necessário arquivá-los numa base de dados vetorial. A escolha da infraestrutura impacta a latência e os custos.
Pinecone: Escalabilidade Serverless
Para projetos que requerem uma rápida colocação em produção e escalabilidade automática, o Pinecone permanece um padrão de referência. A sua arquitetura serverless gere automaticamente a indexação e oferece tempos de resposta na ordem dos milissegundos, essenciais para uma experiência de utilizador fluida num CRM.
pgvector na AWS RDS: A Abordagem Integrada
Contudo, para as instituições financeiras que já utilizam PostgreSQL na AWS RDS para os dados transacionais, a extensão pgvector oferece vantagens significativas. Manter os vetores na mesma base de dados dos dados dos clientes simplifica a gestão da segurança e permite queries híbridas (ex: filtrar os vetores não só por similaridade semântica, mas também por metadados relacionais como “ID Banco” ou “Data Validade Política”). Isto reduz a complexidade da infraestrutura e os custos de data egress.
Reduzir as Alucinações: Prompt Engineering e Citações

No âmbito fintech, a precisão não é negociável. Uma arquitetura RAG fintech deve ser concebida para admitir a ignorância em vez de inventar uma resposta. A engenharia de prompt desempenha aqui um papel fundamental.
É necessário implementar um System Prompt rigoroso que instrua o modelo a:
- Responder exclusivamente baseando-se no contexto fornecido (os chunks recuperados).
- Declarar “Não tenho informações suficientes” se a política não cobrir o caso específico.
- Fornecer a citação exata (ex: “Página 12, Artigo 4.2”).
Tecnicamente, isto obtém-se estruturando o output do LLM não como texto livre, mas como objeto estruturado (JSON) que deve conter campos separados para a resposta e para as referências à fonte. Isto permite ao frontend da aplicação mostrar ao operador o link direto para o PDF original, garantindo a verificabilidade humana do dado.
Orquestração com LangChain: O Caso de Uso Prático
A orquestração final ocorre através de frameworks como LangChain, que ligam o retrieval ao modelo generativo. Num caso de uso real para a pré-qualificação de crédito habitação, o fluxo operacional é o seguinte:
O utilizador insere os dados do cliente (ex: “Trabalhador independente, regime simplificado, LTV 80%”). O sistema converte esta query num vetor e interroga simultaneamente os índices vetoriais de 20 instituições de crédito. O sistema recupera os top-3 chunks mais relevantes para cada banco.
Posteriormente, o LLM analisa os chunks recuperados para determinar a elegibilidade. O resultado é uma matriz comparativa gerada em tempo real, que destaca quais os bancos que aceitariam o processo e com que limitações. Segundo os dados recolhidos no desenvolvimento de soluções semelhantes, esta abordagem reduz os tempos de pré-qualificação em 90%, passando de uma análise manual de 45 minutos para um output automático em menos de 30 segundos.
Conclusões

A implementação de uma arquitetura RAG fintech para a análise das políticas de crédito não é apenas um exercício tecnológico, mas uma alavanca estratégica para a eficiência operacional. A chave do sucesso não reside no modelo de linguagem mais potente, mas no cuidado com a pipeline de ingestão de dados e na gestão rigorosa do contexto. Utilizando estratégias de chunking semântico e bases de dados vetoriais otimizadas, é possível criar assistentes virtuais que não só compreendem a linguagem bancária, mas agem como garantes da compliance, oferecendo respostas precisas, verificadas e rastreáveis.
Perguntas frequentes

Uma arquitetura RAG fintech, acrónimo de Retrieval-Augmented Generation, é uma tecnologia que combina a pesquisa de informações em bases de dados documentais com a capacidade generativa da inteligência artificial. No setor financeiro, serve para transformar documentos não estruturados, como manuais operacionais e políticas de crédito em formato PDF, em conhecimento imediatamente acessível. Isto permite a bancos e intermediários interrogar rapidamente enormes volumes de dados para verificar a viabilidade de créditos habitação e empréstimos, reduzindo os tempos de análise manual de horas para poucos segundos.
Para garantir a precisão necessária na banca e evitar respostas inventadas pelo modelo, é fundamental implementar um System Prompt rigoroso. Este instrui a inteligência artificial a responder exclusivamente baseando-se nos segmentos de texto recuperados dos documentos oficiais e a admitir a ignorância se a informação faltar. Além disso, o sistema deve ser configurado para fornecer citações exatas das fontes, permitindo aos operadores humanos verificar diretamente o artigo ou a página do documento original de onde provém a informação.
A gestão eficaz de documentos ricos em tabelas e notas legais requer o uso de estratégias de chunking semântico em vez de uma simples divisão por número de caracteres. É essencial respeitar a estrutura hierárquica do documento, mantendo íntegros artigos e alíneas, e utilizar um overlap contextual entre os segmentos. As tabelas, em particular aquelas com grelhas LTV ou rendimento, devem ser extraídas e linearizadas em formatos estruturados como JSON ou markdown para que o modelo possa interpretar corretamente as relações entre os dados durante a recuperação.
A escolha da base de dados vetorial depende das prioridades infraestruturais da instituição financeira. O Pinecone é frequentemente a melhor escolha para quem necessita de escalabilidade serverless imediata e latência mínima sem gestão complexa. Pelo contrário, o pgvector na AWS RDS é ideal para as entidades que já utilizam PostgreSQL para os dados transacionais, pois permite executar queries híbridas filtrando os resultados tanto por similaridade semântica como por metadados relacionais, simplificando a segurança e reduzindo os custos de movimentação de dados.
A implementação de uma pipeline RAG bem concebida pode reduzir drasticamente os tempos operacionais. Segundo os dados recolhidos no desenvolvimento de soluções semelhantes, o tempo necessário para a pré-qualificação de um processo pode diminuir em 90 por cento. Passa-se, de facto, de uma análise manual que poderia requerer cerca de 45 minutos para consultar diversas políticas bancárias, para um output automático e comparativo gerado em menos de 30 segundos, melhorando significativamente a eficiência e a reatividade para com o cliente final.
Fontes e Aprofundamento

- Definição técnica de Retrieval-Augmented Generation (RAG) – Wikipedia
- Banco de Portugal – Enquadramento legal para Intermediários de Crédito
- Comissão Europeia – Lei da Inteligência Artificial (AI Act) e impacto no setor financeiro
- Bank for International Settlements (BIS) – Regulação e supervisão de IA no setor bancário
- OCDE – Princípios e análise da Inteligência Artificial nas Finanças

Achou este artigo útil? Há outro assunto que gostaria de me ver abordar?
Escreva nos comentários aqui em baixo! Inspiro-me diretamente nas vossas sugestões.