Em Resumo (TL;DR)
A arquitetura ELT substitui o ETL tradicional nas Fintechs para garantir conformidade regulamentar, auditoria completa e cálculo de riscos em tempo real.
A combinação de Google BigQuery, dbt e Apache Airflow cria uma stack moderna que otimiza o processamento e a governança de dados financeiros.
Manter dados brutos no warehouse permite auditoria retroativa precisa, enquanto o dbt estrutura as transformações seguindo as melhores práticas de engenharia de software.
O diabo está nos detalhes. 👇 Continue lendo para descobrir os passos críticos e as dicas práticas para não errar.
No panorama da engenharia de dados de 2026, a escolha da arquitetura correta para a movimentação de dados não é apenas uma questão de desempenho, mas de conformidade regulamentar, especialmente no setor financeiro. Ao projetar uma pipeline etl vs elt para uma instituição Fintech, o que está em jogo inclui a precisão decimal, a auditabilidade completa (Lineage) e a capacidade de calcular o risco em tempo quase real. Este guia técnico explora por que a abordagem ELT (Extract, Load, Transform) se tornou o padrão de facto em relação ao tradicional ETL, utilizando uma stack moderna composta por Google BigQuery, dbt (data build tool) e Apache Airflow.

ETL vs ELT: A Mudança de Paradigma na Fintech
Durante anos, a abordagem ETL (Extract, Transform, Load) foi dominante. Os dados eram extraídos dos sistemas transacionais (ex: bases de dados de hipotecas), transformados num servidor intermédio (staging area) e, finalmente, carregados no Data Warehouse. Esta abordagem, embora segura, apresentava estrangulamentos significativos: a potência de cálculo do servidor de transformação limitava a velocidade e cada alteração na lógica de negócio exigia atualizações complexas da pipeline antes mesmo de o dado aterrar no warehouse.
Com o advento dos Cloud Data Warehouses como Google BigQuery e AWS Redshift, o paradigma mudou para o ELT (Extract, Load, Transform). Neste modelo:
- Extract: Os dados são extraídos dos sistemas de origem (CRM, Core Banking).
- Load: Os dados são carregados imediatamente no Data Warehouse em formato bruto (Raw Data).
- Transform: As transformações ocorrem diretamente dentro do Warehouse aproveitando a sua potência de cálculo massiva (MPP).
Para a Fintech, o ELT oferece uma vantagem crucial: a auditabilidade. Como os dados brutos estão sempre disponíveis no Warehouse, é possível reconstruir o histórico de qualquer transação ou recalcular os KPI retroativamente sem ter de reexecutar a extração.
Arquitetura da Solução: A Stack Moderna
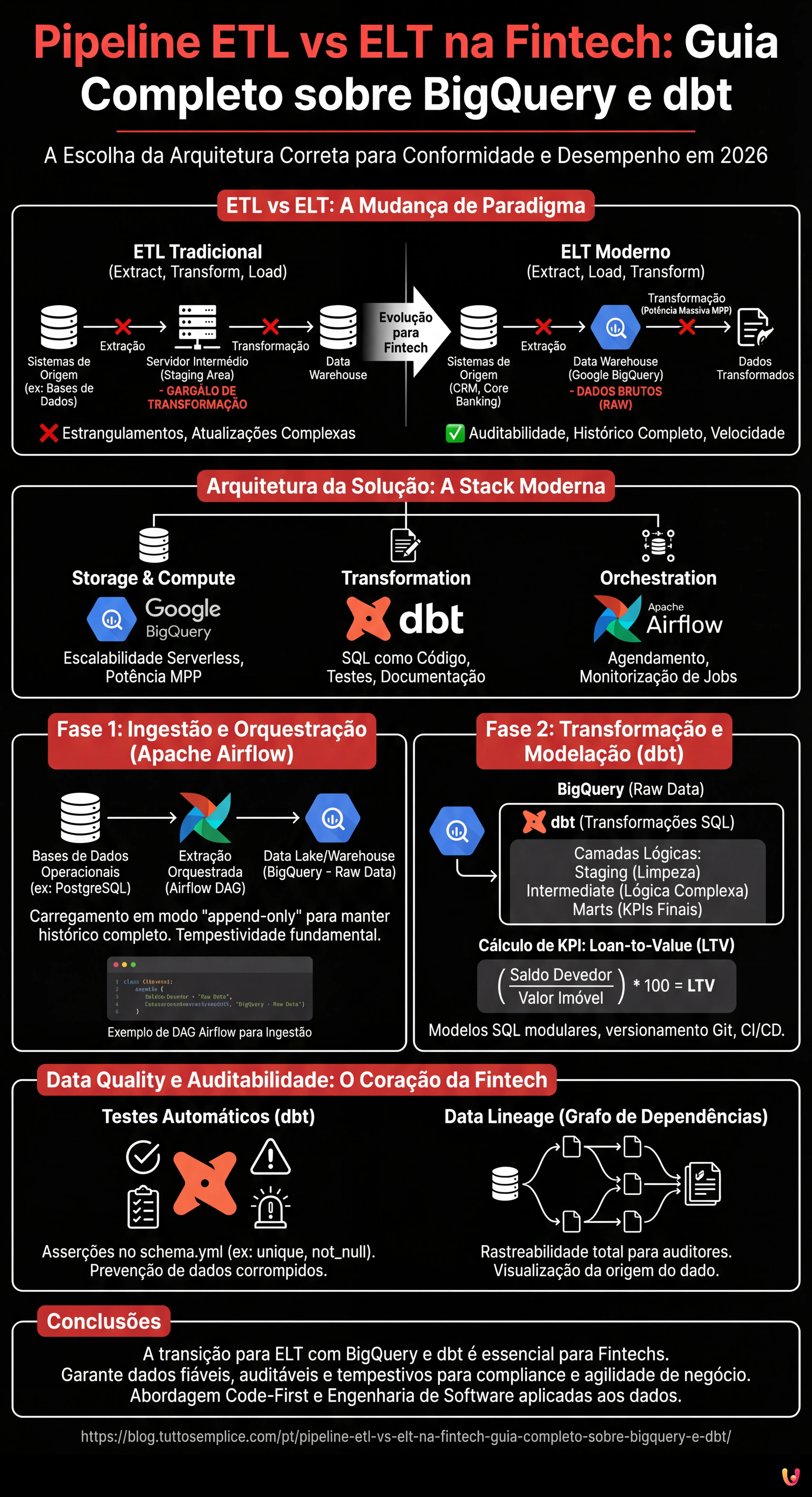
Para construir uma pipeline robusta para a gestão de hipotecas, utilizaremos a seguinte stack tecnológica, considerada best-practice em 2026:
- Storage & Compute: Google BigQuery (para a escalabilidade serverless).
- Transformation: dbt (para gerir as transformações SQL, a documentação e os testes).
- Orchestration: Apache Airflow (para agendar e monitorizar os jobs).
Fase 1: Ingestão e Orquestração com Apache Airflow

O primeiro passo é trazer os dados para o Data Lake/Warehouse. Num contexto Fintech, a tempestividade é fundamental. Utilizamos Apache Airflow para orquestrar a extração das bases de dados operacionais (ex: PostgreSQL) para o BigQuery.
Exemplo de DAG Airflow para a Ingestão
O seguinte snippet conceptual mostra como configurar uma tarefa para carregar os dados das hipotecas em modo “append-only” para manter o histórico completo.
from airflow import DAG
from airflow.providers.google.cloud.transfers.postgres_to_gcs import PostgresToGCSOperator
from airflow.providers.google.cloud.transfers.gcs_to_bigquery import GCSToBigQueryOperator
from airflow.utils.dates import days_ago
with DAG('fintech_mortgage_ingestion', start_date=days_ago(1), schedule_interval='@hourly') as dag:
extract_mortgages = PostgresToGCSOperator(
task_id='extract_mortgages_raw',
postgres_conn_id='core_banking_db',
sql='SELECT * FROM mortgages WHERE updated_at > {{ prev_execution_date }}',
bucket='fintech-datalake-raw',
filename='mortgages/{{ ds }}/mortgages.json',
)
load_to_bq = GCSToBigQueryOperator(
task_id='load_mortgages_bq',
bucket='fintech-datalake-raw',
source_objects=['mortgages/{{ ds }}/mortgages.json'],
destination_project_dataset_table='fintech_warehouse.raw_mortgages',
write_disposition='WRITE_APPEND', # Crucial para o histórico
source_format='NEWLINE_DELIMITED_JSON',
)
extract_mortgages >> load_to_bq
Fase 2: Transformação e Modelação com dbt
Uma vez que os dados estão no BigQuery, entra em jogo o dbt. Ao contrário dos stored procedures tradicionais, o dbt permite tratar as transformações de dados como código de software (software engineering best practices), incluindo versionamento (Git), testes e CI/CD.
Estrutura do Projeto dbt
Organizamos os modelos em três camadas lógicas:
- Staging (src): Limpeza ligeira, renomeação de colunas, casting dos tipos de dados.
- Intermediate (int): Lógica de negócio complexa, junções (joins) entre tabelas.
- Marts (fct/dim): Tabelas finais prontas para BI e relatórios regulamentares.
Cálculo de KPI Complexos: Loan-to-Value (LTV) em SQL
No setor das hipotecas, o LTV é um indicador de risco crítico. Eis como aparece um modelo dbt (ficheiro .sql) que calcula o LTV atualizado e classifica o risco, unindo dados de registo e avaliações imobiliárias.
-- models/marts/risk/fct_mortgage_risk.sql
WITH mortgages AS (
SELECT * FROM {{ ref('stg_core_mortgages') }}
),
appraisals AS (
-- Obtemos a última avaliação disponível para o imóvel
SELECT
property_id,
appraisal_amount,
appraisal_date,
ROW_NUMBER() OVER (PARTITION BY property_id ORDER BY appraisal_date DESC) as rn
FROM {{ ref('stg_external_appraisals') }}
)
SELECT
m.mortgage_id,
m.customer_id,
m.outstanding_balance,
a.appraisal_amount,
-- Cálculo LTV: (Saldo Devedor / Valor Imóvel) * 100
ROUND((m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) * 100, 2) as loan_to_value_ratio,
CASE
WHEN (m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) > 0.80 THEN 'HIGH_RISK'
WHEN (m.outstanding_balance / NULLIF(a.appraisal_amount, 0)) BETWEEN 0.50 AND 0.80 THEN 'MEDIUM_RISK'
ELSE 'LOW_RISK'
END as risk_category,
CURRENT_TIMESTAMP() as calculated_at
FROM mortgages m
LEFT JOIN appraisals a ON m.property_id = a.property_id AND a.rn = 1
WHERE m.status = 'ACTIVE'
Data Quality e Auditabilidade: O Coração da Fintech
No âmbito financeiro, um dado errado pode levar a sanções. A abordagem ELT com dbt destaca-se na Data Quality graças aos testes integrados.
Implementação de Testes Automáticos
No ficheiro schema.yml do dbt, definimos as asserções que os dados devem satisfazer. Se um teste falhar, a pipeline bloqueia ou envia um alerta, prevenindo a propagação de dados corrompidos.
version: 2
models:
- name: fct_mortgage_risk
description: "Tabela de factos para o risco de hipotecas"
columns:
- name: mortgage_id
tests:
- unique
- not_null
- name: loan_to_value_ratio
tests:
- not_null
# Teste personalizado: LTV não pode ser negativo ou absurdamente alto (>200%)
- dbt_utils.expression_is_true:
expression: ">= 0 AND <= 200"
Data Lineage
O dbt gera automaticamente um grafo de dependências (DAG). Para um auditor, isto significa poder visualizar graficamente como o dado “Risco Alto” de um cliente foi derivado: desde a tabela raw, através das transformações intermédias, até ao relatório final. Este nível de transparência é frequentemente obrigatório nas inspeções bancárias.
Gestão da Infraestrutura e Versionamento
Ao contrário das pipelines ETL legacy baseadas em GUI (interfaces gráficas drag-and-drop), a abordagem moderna é Code-First.
- Version Control (Git): Cada alteração à lógica de cálculo do LTV é um commit no Git. Podemos saber quem alterou a fórmula, quando e porquê (através do Pull Request).
- Ambientes Isolados: Graças ao dbt, cada programador pode executar a pipeline num ambiente sandbox (ex:
dbt run --target dev) num subconjunto de dados BigQuery, sem impactar a produção.
Troubleshooting Comum
1. Schema Drift (Mudança do esquema de origem)
Problema: O Core Banking adiciona uma coluna à tabela de hipotecas e a pipeline quebra.
Solução: No BigQuery, utilizar a opção schema_update_options=['ALLOW_FIELD_ADDITION'] durante o carregamento. No dbt, utilizar pacotes como dbt_utils.star para selecionar dinamicamente as colunas ou implementar testes de esquema rigorosos que avisam da mudança sem quebrar o fluxo crítico.
2. Latência dos Dados
Problema: Os dados das avaliações imobiliárias chegam com atraso em relação aos saldos das hipotecas.
Solução: Implementar a lógica de “Late Arriving Facts”. Utilizar as Window Functions de SQL (como visto no exemplo acima com ROW_NUMBER) para obter sempre o último dado válido disponível no momento da execução, ou modelar tabelas snapshot para historicizar o estado exato no final do mês.
Conclusões

A transição de uma pipeline etl vs elt no setor Fintech não é uma moda, mas uma necessidade operacional. A utilização do BigQuery para o armazenamento a baixo custo e a alta capacidade computacional, combinada com o dbt para a governação das transformações, permite às empresas financeiras ter dados fiáveis, auditáveis e tempestivos. Implementar esta arquitetura requer competências de engenharia de software aplicadas aos dados, mas o retorno do investimento em termos de compliance e agilidade de negócio é incalculável.
Perguntas frequentes

A distinção principal diz respeito ao momento da transformação dos dados. No modelo ETL os dados são processados antes do carregamento, enquanto no paradigma ELT os dados brutos são carregados imediatamente no Data Warehouse e transformados posteriormente. Na Fintech o método ELT é preferido pois garante a total auditabilidade e permite recalcular os KPI históricos sem reexecutar a extração dos sistemas de origem.
Esta combinação constitui o padrão atual graças à escalabilidade serverless do Google BigQuery e à capacidade do dbt de gerir as transformações SQL como código de software. A sua utilização conjunta permite aproveitar a potência de cálculo da cloud para processar volumes massivos de dados financeiros, assegurando ao mesmo tempo versionamento, testes automáticos e uma documentação clara da lógica de negócio.
O modelo ELT facilita a compliance conservando os dados brutos originais no Data Warehouse, tornando possível reconstruir a história de cada transação em qualquer momento. Além disso, ferramentas como o dbt geram automaticamente um grafo de dependências, conhecido como Data Lineage, que permite aos auditores visualizar exatamente como um dado final foi derivado da fonte durante as inspeções normativas.
A integridade do dado é assegurada através de testes automáticos integrados no código de transformação, os quais verificam a unicidade e coerência dos valores. Ao definir regras específicas no ficheiro de configuração, a pipeline pode bloquear o processo ou enviar avisos imediatos se detetar anomalias, prevenindo a propagação de erros nos relatórios de decisão ou regulamentares.
O cálculo de indicadores de risco é gerido através de modelos SQL modulares dentro do Data Warehouse, unindo dados de registo e avaliações imobiliárias. Graças ao método ELT é possível implementar lógicas que historicizam o risco e gerem os atrasos dos dados, assegurando que o cálculo reflita sempre a informação mais válida e atualizada disponível no momento da execução.
Fontes e Aprofundamento

- Definição de Extract, Transform, Load (ETL) e suas variantes na Wikipedia
- Banco Central do Brasil: Padrões de dados e infraestrutura do Open Finance
- Regulamento (UE) 2022/2554 (DORA) relativo à resiliência operacional digital do setor financeiro
- NIST Big Data Interoperability Framework: Arquitetura de Referência de Dados (Governo dos EUA)

Achou este artigo útil? Há outro assunto que gostaria de me ver abordar?
Escreva nos comentários aqui em baixo! Inspiro-me diretamente nas vossas sugestões.