Em Resumo (TL;DR)
O SEO programático fintech supera os limites dos CMS tradicionais gerindo milhões de páginas dinâmicas essenciais para adquirir tráfego orgânico em grande escala.
A arquitetura baseada em Next.js e AWS utiliza a Incremental Static Regeneration para garantir desempenho elevado e dados atualizados sem tempos de build infinitos.
Otimizar o Crawl Budget requer uma estrutura de internal linking em grafo e sitemaps segmentados para assegurar a indexação de cada página individual.
O diabo está nos detalhes. 👇 Continue lendo para descobrir os passos críticos e as dicas práticas para não errar.
No panorama digital atual, o seo programático fintech representa a fronteira definitiva para a aquisição orgânica em grande escala. Para os portais de comparação de crédito habitação, créditos pessoais e seguros, o desafio não é apenas posicionar-se para keywords de alto volume como “melhor crédito habitação”, mas dominar a long tail composta por milhões de combinações específicas (ex: “crédito habitação taxa fixa 200k 20 anos santander”).
Estamos em 2026 e as regras do jogo mudaram: a Google exige não apenas velocidade, mas uma experiência de utilizador impecável e conteúdos únicos, mesmo quando se geram milhões de URLs. Este guia técnico explora a arquitetura necessária na AWS (Amazon Web Services) para gerir uma infraestrutura de SEO programático capaz de escalar para além de um milhão de páginas sem sacrificar o desempenho ou o Crawl Budget.

1. O Problema da Escala na Fintech: Porque a Abordagem Tradicional Falha
No setor Fintech, a precisão dos dados é crítica (YMYL – Your Money Your Life). Uma abordagem tradicional baseada em CMS monolíticos (como WordPress) colapsa sob o peso de milhões de registos dinâmicos. Os problemas principais são três:
- Tempos de Build Insustentáveis: Gerar estaticamente (SSG) 1 milhão de páginas exigiria horas, tornando as taxas de juro obsoletas antes mesmo da publicação.
- Crawl Budget Desperdiçado: Sem uma estratégia de linking interno cirúrgica, o Googlebot abandonará o rastreio antes de alcançar as páginas profundas.
- Thin Content: Páginas que diferem apenas por um número (ex: duração 20 anos vs 21 anos) correm o risco de ser desindexadas como duplicados.
A solução reside numa arquitetura Headless e Serverless, tirando partido de Next.js para a renderização e AWS para a infraestrutura global.
2. Arquitetura Técnica: Next.js e AWS Amplify
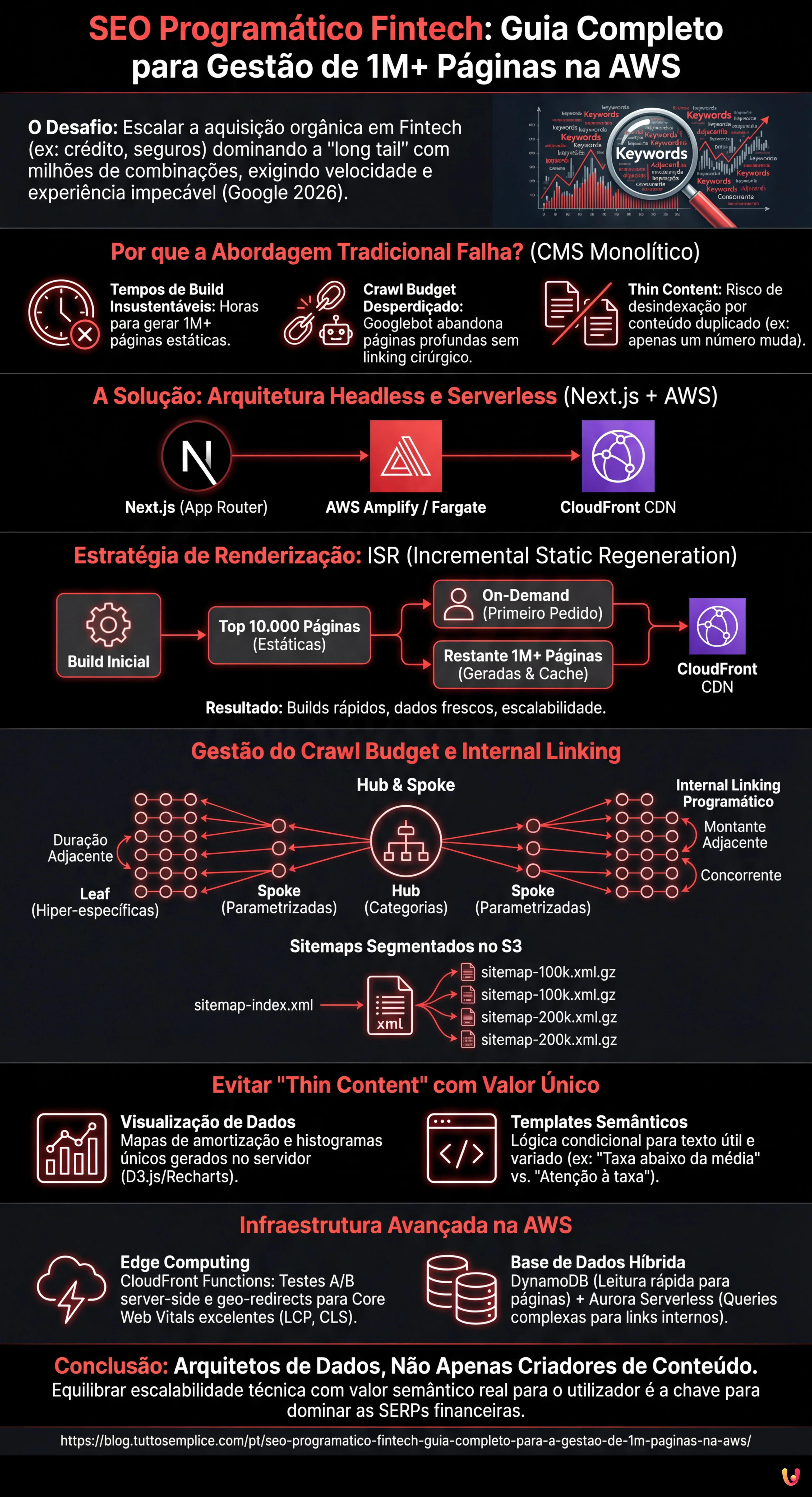
Para gerir esta complexidade, a escolha da stack tecnológica é fundamental. A combinação vencedora para 2026 prevê Next.js (App Router) implementado no AWS Amplify Gen 2 ou contentorizado via AWS Fargate, com uma CDN CloudFront à frente.
Incremental Static Regeneration (ISR) como Standard
Não podemos usar o Server-Side Rendering (SSR) puro para todas as páginas devido ao Time to First Byte (TTFB) elevado, nem o SSG puro devido aos tempos de build. A solução é o ISR (Incremental Static Regeneration).
Com o ISR, podemos gerar estaticamente apenas as “Top 10.000” páginas (aquelas com mais tráfego) durante a build. O restante milhão de páginas será gerado on-demand no primeiro pedido do utilizador e depois armazenado em cache na CDN do CloudFront.
// Exemplo conceptual de configuração ISR em Next.js
export const revalidate = 3600; // Regenera a página no máximo a cada hora
export async function generateStaticParams() {
// Recupera apenas as combinações mais populares para a build inicial
const topCombinations = await getTopMortgageCombinations();
return topCombinations.map((combo) => ({
amount: combo.amount.toString(),
duration: combo.duration.toString(),
}));
}
Esta estratégia reduz os tempos de build de horas para minutos, garantindo que as páginas menos frequentadas existam na mesma e sejam indexáveis.
3. Gestão do Crawl Budget e Internal Linking Graph

Ter 1 milhão de páginas é inútil se a Google indexar apenas 50.000. A gestão do Crawl Budget é a prioridade número um no seo programático fintech.
A Estratégia “Hub & Spoke” Dinâmica
Não podemos ligar tudo a tudo. Devemos criar clusters semânticos. Imaginemos uma estrutura em grafo:
- Hub (Nível 1): Páginas de categoria (ex: “Crédito Habitação Taxa Fixa”).
- Spoke (Nível 2): Páginas parametrizadas por montante (ex: “Crédito Habitação 100k”, “Crédito Habitação 200k”).
- Leaf (Nível 3): Páginas hiper-específicas (ex: “Crédito Habitação 200k a 20 anos”).
O segredo é o Internal Linking Programático. Na página “Crédito Habitação 200k a 20 anos”, não devemos colocar links ao acaso. Devemos inserir links para:
- A duração adjacente (+/- 5 anos): “Ver prestação para 15 anos” e “Ver prestação para 25 anos”.
- O montante adjacente (+/- 20k): “Calcular prestação para 180k”.
- O banco concorrente com oferta semelhante.
Isto cria um percurso de rastreio natural para o bot e útil para o utilizador, distribuindo o PageRank das páginas Hub (frequentemente linkadas externamente) para as páginas Leaf (que convertem mas recebem poucos backlinks).
Segmentação dos Sitemaps
Não envie um único sitemap. No AWS S3, gere sitemaps segmentados e comprimidos (Gzip):
sitemap-index.xmlsitemap-amount-100k.xml.gzsitemap-amount-200k.xml.gz
Isto permite monitorizar na Google Search Console quais os segmentos que têm problemas de indexação específicos.
4. Canonicalization e Gestão de Parâmetros
Um erro comum é gerir os filtros como parâmetros de URL (?duration=20&amount=200000) sem uma estratégia de canonicalização. No SEO programático, queremos que estes parâmetros se tornem URLs estáticos (/credito-habitacao/200000-euros/20-anos).
No entanto, as combinações são infinitas. É essencial definir uma Lógica Canónica rigorosa:
- Self-Referencing Canonical: Cada página gerada programaticamente deve ter um canonical que aponta para si mesma, a menos que seja uma variante quase idêntica.
- Gestão da Ordenação: O URL
/credito/200k/20-anospoderia mostrar os bancos ordenados por TAEG ou por Prestação. O conteúdo é o mesmo, a ordem muda. Neste caso, o URL com ordenação (ex:?sort=taeg) DEVE ter o canonical para a versão limpa do URL.
5. Evitar o “Thin Content”: Injeção Dinâmica e Templates Semânticos
A Google penaliza os sites que geram milhões de páginas “chapa 5” (padronizadas). Como tornar única a página “Crédito 150k” em relação à “Crédito 160k”?
Visualização de Dados como Conteúdo Único
Em vez de confiar apenas no texto gerado por IA (que pode tornar-se repetitivo), utilizamos os dados para criar valor único. Utilizando bibliotecas como D3.js ou Recharts do lado do servidor, podemos gerar:
- Mapas de Amortização: Únicos para aquela combinação específica de montante/duração.
- Histogramas de Comparação: “Como se posiciona esta prestação em relação à média nacional?”.
A Google é capaz de interpretar o DOM e reconhecer que os dados numéricos e as estruturas SVG/Canvas são diferentes, validando a página como única e útil.
Templates Semânticos Avançados
Não se limite a substituir {montante} no texto. Crie lógicas condicionais no template:
{taeg < 2.5 ?
Este é um momento histórico excecional para solicitar este montante, com taxas abaixo da média de 3%.
:
Atenção: a taxa para esta combinação é superior à média. Recomendamos avaliar uma duração inferior.
}Estas variações lógicas tornam o texto realmente útil e diferente para cada cluster de páginas.
6. Edge Computing: CloudFront Functions e Lambda@Edge
Para manter os Core Web Vitals (em particular LCP e CLS) excelentes, devemos mover a lógica o mais próximo possível do utilizador. Na AWS, utilizamos CloudFront Functions (mais rápidas e económicas que as Lambda@Edge) para:
Testes A/B do Lado do Servidor
Evite ferramentas de testes A/B client-side que causam flickering e layout shift. Com uma CloudFront Function, pode intercetar o pedido, atribuir um cookie ao utilizador e servir a versão A ou B da página estática diretamente da Edge. Isto garante um CLS igual a zero.
Geo-Redirect e Personalização
Se o portal opera em vários países, use a Edge para detetar o header CloudFront-Viewer-Country e reencaminhar o utilizador para a subpasta correta (ex: /pt/ ou /es/) antes mesmo que o pedido toque no servidor Next.js.
7. Gestão da Base de Dados: DynamoDB vs Aurora Serverless
Para alimentar 1 milhão de páginas, a base de dados é o gargalo. Num contexto de seo programático fintech, a latência de leitura é tudo.
- DynamoDB (NoSQL): Ideal para armazenar os dados pré-calculados das ofertas. É milimétrico na latência e escala infinitamente. Estruture a Partition Key como
PK=MORTGAGE#200000#20para acessos O(1). - Aurora Serverless v2 (SQL): Necessário se precisar de queries relacionais complexas para gerar os links internos (ex: “encontrar todos os créditos com TAEG < 3% a 15 anos").
Uma estratégia híbrida funciona frequentemente melhor: use SQL para a lógica de build/regeneração e DynamoDB para servir os dados às páginas ISR a alta velocidade.
8. Troubleshooting e Monitorização
Uma vez live, como monitorizamos a saúde de 1M+ páginas?
Análise de Logs com Amazon Athena
Não confie apenas na Search Console (que tem um atraso de dias). Configure os logs do CloudFront para serem enviados para o S3. Use o Amazon Athena para queries SQL nos logs e descobrir em tempo real:
- Quais as páginas que o Googlebot está a rastrear (filtragem por User-Agent).
- Códigos de estado 5xx (erros de servidor) ou 429 (rate limiting).
- Páginas órfãs que recebem tráfego mas não estão linkadas.
Gestão dos Soft 404
Se uma combinação não produz resultados (ex: “Crédito 500 euros a 40 anos” – nenhum banco o faz), NÃO devolva uma página vazia com status 200 (Soft 404). Implemente uma lógica que:
- Devolva um verdadeiro 404 se a combinação for impossível.
- Ou, melhor, faça um redirect 301 para a combinação válida mais próxima (ex: “Crédito 50.000 euros”), preservando a autoridade.
Conclusões

Implementar uma estratégia de seo programático fintech em 2026 requer uma mudança de paradigma: de “criadores de conteúdos” para “arquitetos de dados”. A utilização de AWS e Next.js permite superar os limites físicos dos CMS tradicionais, mas a verdadeira vitória obtém-se cuidando da qualidade do dado e da experiência do utilizador.
Lembre-se: o objetivo não é enganar a Google com milhões de páginas, mas fornecer a resposta mais precisa e rápida possível a milhões de perguntas específicas dos utilizadores. Apenas quem conseguir equilibrar escalabilidade técnica e valor semântico dominará as SERPs financeiras dos próximos anos.
Perguntas frequentes

A gestão ideal requer uma estratégia de linking interno definida como «Hub and Spoke», onde as páginas de categoria distribuem autoridade para as páginas folha específicas. É fundamental segmentar os sitemaps no AWS S3 e utilizar links programáticos para ofertas adjacentes ou concorrentes, evitando ligar tudo a tudo para guiar o Googlebot de forma eficiente sem desperdiçar recursos de rastreio.
A regeneração estática incremental, ou ISR, resolve o problema dos tempos de build insustentáveis típicos da geração estática pura em milhões de URLs. Esta técnica permite pré-gerar apenas as páginas de alto tráfego durante a build, criando as restantes on-demand no primeiro pedido do visitante e guardando-as na cache do CloudFront para garantir velocidade e frescura dos dados.
Para diferenciar páginas semelhantes e evitar conteúdos duplicados, é necessário integrar visualizações de dados únicas como mapas de amortização gerados do lado do servidor. Além disso, o uso de templates semânticos com lógicas condicionais permite variar o texto descritivo com base nos dados financeiros específicos, oferecendo valor real ao leitor e tornando cada URL único aos olhos dos motores de pesquisa.
Uma estratégia híbrida representa frequentemente a solução vencedora para gerir grandes volumes de dados. O DynamoDB oferece uma latência milimétrica ideal para servir dados pré-calculados às páginas frontend, enquanto o Aurora Serverless gere as queries relacionais complexas necessárias para a lógica de construção dos links internos, eliminando os gargalos na leitura.
Mover a lógica para as CloudFront Functions permite executar operações complexas como testes A/B e reencaminhamentos geográficos diretamente no nó Edge, antes que o pedido chegue ao servidor. Esta abordagem elimina o flickering do lado do cliente e reduz o Cumulative Layout Shift a zero, melhorando significativamente a estabilidade visual e o posicionamento nos motores de pesquisa.
Fontes e Aprofundamento


Achou este artigo útil? Há outro assunto que gostaria de me ver abordar?
Escreva nos comentários aqui em baixo! Inspiro-me diretamente nas vossas sugestões.