In Breve (TL;DR)
L’automazione tramite NLP trasforma la qualificazione dei lead immobiliari, superando i form statici per estrarre dati precisi da conversazioni naturali.
Il fine-tuning di modelli BERT italiani permette di creare sistemi NER customizzati capaci di identificare importi, professioni e tipologie immobiliari.
La normalizzazione dei dati estratti e l’integrazione diretta nel CRM BOMA ottimizzano il calcolo del rating creditizio e la gestione commerciale.
Il diavolo è nei dettagli. 👇 Continua a leggere per scoprire i passaggi critici e i consigli pratici per non sbagliare.
Nel panorama competitivo del 2026, la velocità di risposta non è più l’unico fattore determinante nel settore del credito e del real estate. La vera sfida risiede nella precisione e nella capacità di filtrare il rumore. La qualificazione lead immobiliare è passata dall’essere un compito manuale svolto dai call center a un processo automatizzato guidato da algoritmi di Natural Language Processing (NLP). In questa guida tecnica, esploreremo come costruire un sistema di Named Entity Recognition (NER) customizzato per estrarre dati strutturati da conversazioni non strutturate e integrarli direttamente nel CRM BOMA.

Perché l’Entity Extraction cambia la Qualificazione Lead Immobiliare
I form statici sui siti web (Nome, Cognome, Telefono) hanno tassi di conversione sempre più bassi. Gli utenti preferiscono interagire tramite chat naturali o messaggi vocali. Tuttavia, questo genera dati non strutturati difficili da processare. Qui entra in gioco l’Entity Extraction Semantica.
L’obiettivo non è solo capire l’intento (es. “voglio un mutuo”), ma estrarre slot specifici di informazione necessari per il calcolo del rating creditizio o la fattibilità dell’acquisto. Un sistema ben progettato deve identificare:
- ENT_AMOUNT: L’importo richiesto (es. “mi servono 200k”).
- ENT_LTV: Il Loan-to-Value implicito o il valore dell’immobile.
- ENT_JOB_TYPE: La tipologia contrattuale (es. “indeterminato”, “P.IVA forfettaria”).
- ENT_PROPERTY: Tipologia immobile e classe energetica.
Prerequisiti e Stack Tecnologico
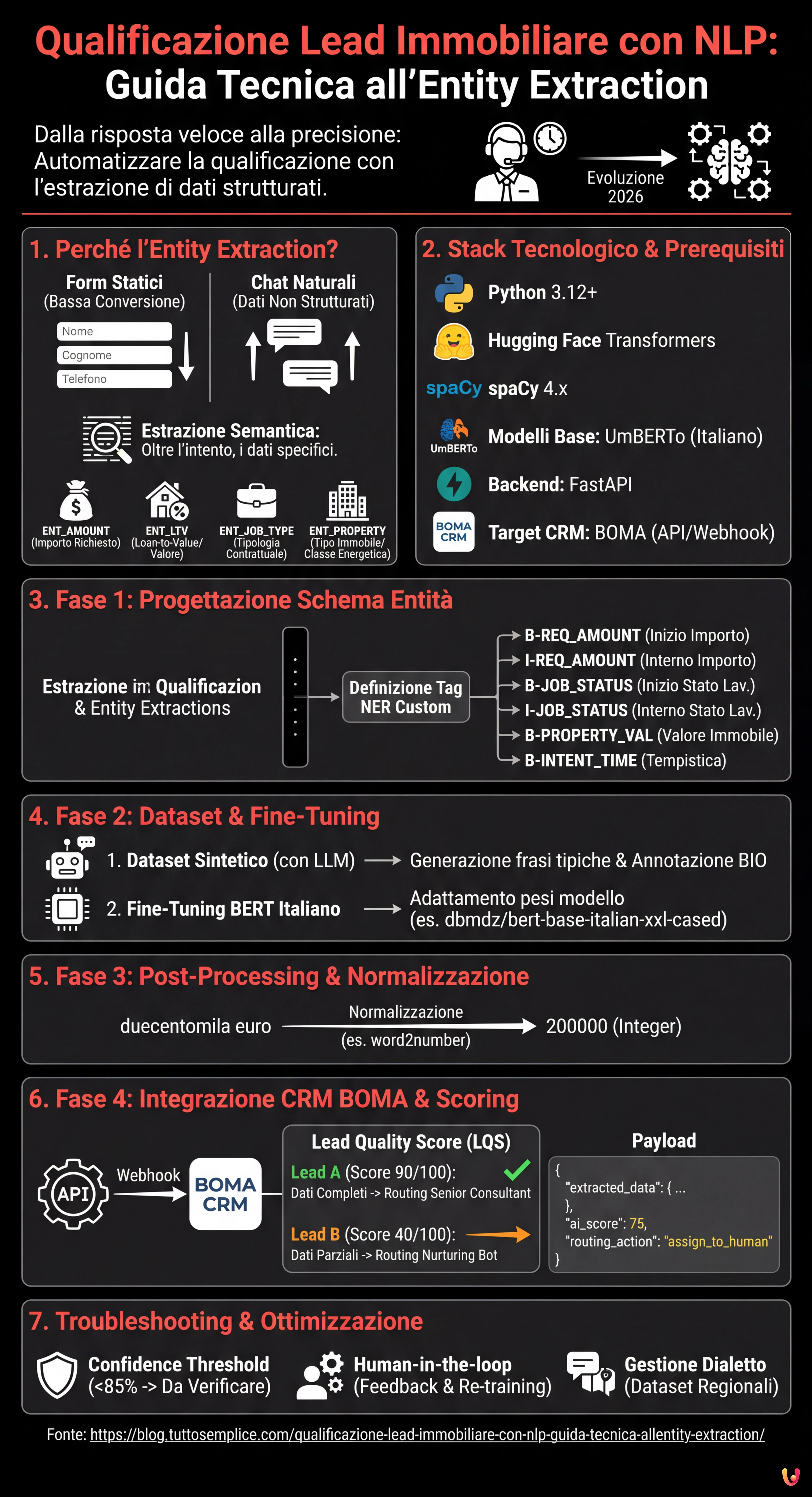
Per seguire questa guida, è necessaria una conoscenza intermedia di Python e dei principi di Machine Learning. Utilizzeremo il seguente stack, standardizzato per il 2026:
- Linguaggio: Python 3.12+
- Framework NLP: Hugging Face Transformers, spaCy 4.x
- Modelli Base:
UmBERTo(per l’italiano) o versioni quantizzate diLlama-3-8B-Instructper task generativi. - Backend: FastAPI per l’esposizione del modello.
- Target CRM: BOMA (tramite API REST/Webhook).
Fase 1: Progettazione dello Schema delle Entità

Prima di scrivere codice, dobbiamo definire cosa il nostro modello deve cercare. Nel contesto italiano dei mutui, il gergo è specifico. Un modello generico fallirebbe nel distinguere tra “anticipo” e “rata”.
Definiamo le etichette per il nostro dataset di training:
NER_TAGS = [
"O", # Outside (nessuna entità)
"B-REQ_AMOUNT", # Inizio importo richiesto
"I-REQ_AMOUNT", # Interno importo richiesto
"B-JOB_STATUS", # Inizio stato lavorativo
"I-JOB_STATUS", # Interno stato lavorativo
"B-PROPERTY_VAL", # Valore immobile
"B-INTENT_TIME" # Tempistica desiderata (es. "rogito entro marzo")
]
Fase 2: Preparazione del Dataset e Fine-Tuning
Per ottenere una qualificazione lead immobiliare precisa, non possiamo affidarci a modelli generalisti zero-shot per l’estrazione massiva, poiché costosi e lenti. La soluzione migliore è il fine-tuning di un modello BERT-based italiano.
1. Creazione del Dataset Sintetico
Se non disponete di storici chat GDPR-compliant, potete generare un dataset sintetico utilizzando un LLM (come Meta AI Llama 3) per creare migliaia di variazioni di frasi tipiche:
“Sono un dipendente statale e cerco un mutuo per una casa da 250.000 euro, ho 50k di anticipo.”
Annotate queste frasi nel formato JSONL standard per l’addestramento (BIO format).
2. Fine-Tuning con Hugging Face
Utilizzeremo dbmdz/bert-base-italian-xxl-cased come base, essendo uno dei modelli più performanti sulla sintassi italiana. Ecco uno snippet semplificato per il training loop:
from transformers import AutoTokenizer, AutoModelForTokenClassification, TrainingArguments, Trainer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=len(NER_TAGS))
args = TrainingArguments(
output_dir="./boma-ner-v1",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
num_train_epochs=5,
weight_decay=0.01,
)
# Supponendo che 'tokenized_datasets' sia già preparato
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
)
trainer.train()
Questo processo adatta i pesi del modello per riconoscere specificamente termini come “surroga”, “tasso fisso” o “consulente” nel contesto della frase.
Fase 3: Post-Processing e Normalizzazione
Il modello NER restituisce token ed etichette. Per la qualificazione lead immobiliare, dobbiamo trasformare "duecentomila euro" in 200000 (Integer). Questa fase di normalizzazione è critica per popolare il database.
Utilizziamo librerie come word2number per l’italiano o regex customizzate per pulire l’output del modello prima dell’invio al CRM.
Fase 4: Integrazione nel CRM BOMA
Una volta che il modello è esposto via API (es. su un container Docker), dobbiamo collegarlo al flusso di ingresso dei lead. L’integrazione con BOMA avviene solitamente tramite webhook che scattano alla ricezione di un nuovo messaggio.
Logica di Scoring e Routing
Non tutti i lead sono uguali. Utilizzando i dati estratti, possiamo calcolare un Lead Quality Score (LQS) in tempo reale:
- Lead A (Score 90/100): Dati completi (Lavoro, Importo, Immobile), LTV Routing immediato al Senior Consultant.
- Lead B (Score 40/100): Dati parziali, LTV > 95%, Contratto Determinato. -> Routing al Nurturing Bot automatico.
Ecco un esempio di payload JSON da inviare alle API di BOMA:
{
"lead_source": "Whatsapp_Business",
"message_body": "Salve, vorrei info per mutuo prima casa, sono infermiere",
"extracted_data": {
"job_type": "infermiere",
"job_category": "pubblico_impiego",
"intent": "acquisto_prima_casa"
},
"ai_score": 75,
"routing_action": "assign_to_human"
}
Troubleshooting: Gestione delle Allucinazioni e Ambiguità
Anche i migliori modelli possono sbagliare. Ecco come mitigare i rischi:
- Confidence Threshold: Se il modello estrae un’entità con una confidenza inferiore al 85%, il sistema deve marcare il campo come “Da verificare” nel CRM BOMA, richiedendo l’intervento umano.
- Human-in-the-loop: Implementare un meccanismo di feedback dove gli agenti immobiliari possono correggere l’etichettatura nel CRM. Questi dati corretti devono rientrare nel dataset di training per il re-training mensile del modello.
- Gestione del Dialetto: Addestrare il modello su dataset che includono espressioni colloquiali regionali spesso usate nelle chat informali.
Conclusioni

L’implementazione di un sistema di Entity Extraction per la qualificazione lead immobiliare non è più un esercizio accademico, ma una necessità operativa. Automatizzando l’estrazione dei dati critici (LTV, lavoro, budget) e integrandoli direttamente in BOMA, le agenzie possono ridurre il tempo di primo contatto da ore a secondi, assegnando le pratiche più complesse ai consulenti migliori e lasciando all’AI la gestione della scrematura iniziale.
Domande frequenti

Si tratta di un processo basato su NLP che identifica ed estrae dati specifici, come importo del mutuo o tipo di contratto, da conversazioni naturali e non strutturate. A differenza dei form statici, questa tecnologia permette di comprendere l intento dell utente e popolare automaticamente i campi necessari per il calcolo del rating creditizio direttamente nel CRM.
Per ottenere alte performance sulla sintassi italiana, la scelta migliore ricade sul fine-tuning di modelli BERT-based come UmBERTo o dbmdz bert-base-italian. Questi modelli sono superiori alle soluzioni generaliste zero-shot perché possono essere addestrati per riconoscere il gergo specifico del settore creditizio, distinguendo termini tecnici come rata, anticipo o surroga.
Integrando un modello di estrazione entità via API o Webhook, BOMA può ricevere dati già puliti e normalizzati. Questo consente di assegnare un punteggio di qualità al lead in tempo reale e di instradare automaticamente i contatti: i profili completi vanno ai consulenti senior, mentre quelli parziali vengono gestiti da bot di nurturing, ottimizzando il tempo del team vendita.
Un sistema ben progettato estrae entità critiche come l importo richiesto, il valore dell immobile per il calcolo del Loan-to-Value, la tipologia contrattuale lavorativa e la classe energetica della casa. Questi dati, definiti come slot informativi, sono essenziali per determinare immediatamente la fattibilità della pratica senza lunghe interviste preliminari.
È necessario implementare una soglia di confidenza, ad esempio all 85 per cento, sotto la quale il sistema segnala il dato come da verificare manualmente. Inoltre, si adotta un approccio human-in-the-loop dove le correzioni apportate dagli agenti immobiliari vengono salvate e riutilizzate per il riaddestramento periodico del modello, migliorandone la precisione nel tempo.
Fonti e Approfondimenti

- Wikipedia – Definizione tecnica di Riconoscimento delle Entità Nominate (NER)
- Banca d’Italia – Sondaggio congiunturale sul mercato delle abitazioni in Italia
- Agenzia delle Entrate – Osservatorio del Mercato Immobiliare (OMI)
- Commissione Europea – Quadro normativo sull’Intelligenza Artificiale (AI Act)

Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.