Pe Scurt (TL;DR)
Regulamentul European privind Inteligența Artificială clasifică scoringul de credit ca sistem cu risc ridicat, impunând obligații riguroase de transparență și explicabilitate.
Data Scientists trebuie să renunțe la modelele black-box, adoptând librării de Explainable AI precum SHAP pentru a garanta decizii interpretabile și consistente matematic.
Integrarea instrumentelor precum AWS SageMaker Clarify în pipeline-urile MLOps permite automatizarea conformității normative prin monitorizarea bias-ului și a explicabilității în producție.
Diavolul se ascunde în detalii. 👇 Continuă să citești pentru a descoperi pașii critici și sfaturile practice pentru a nu greși.
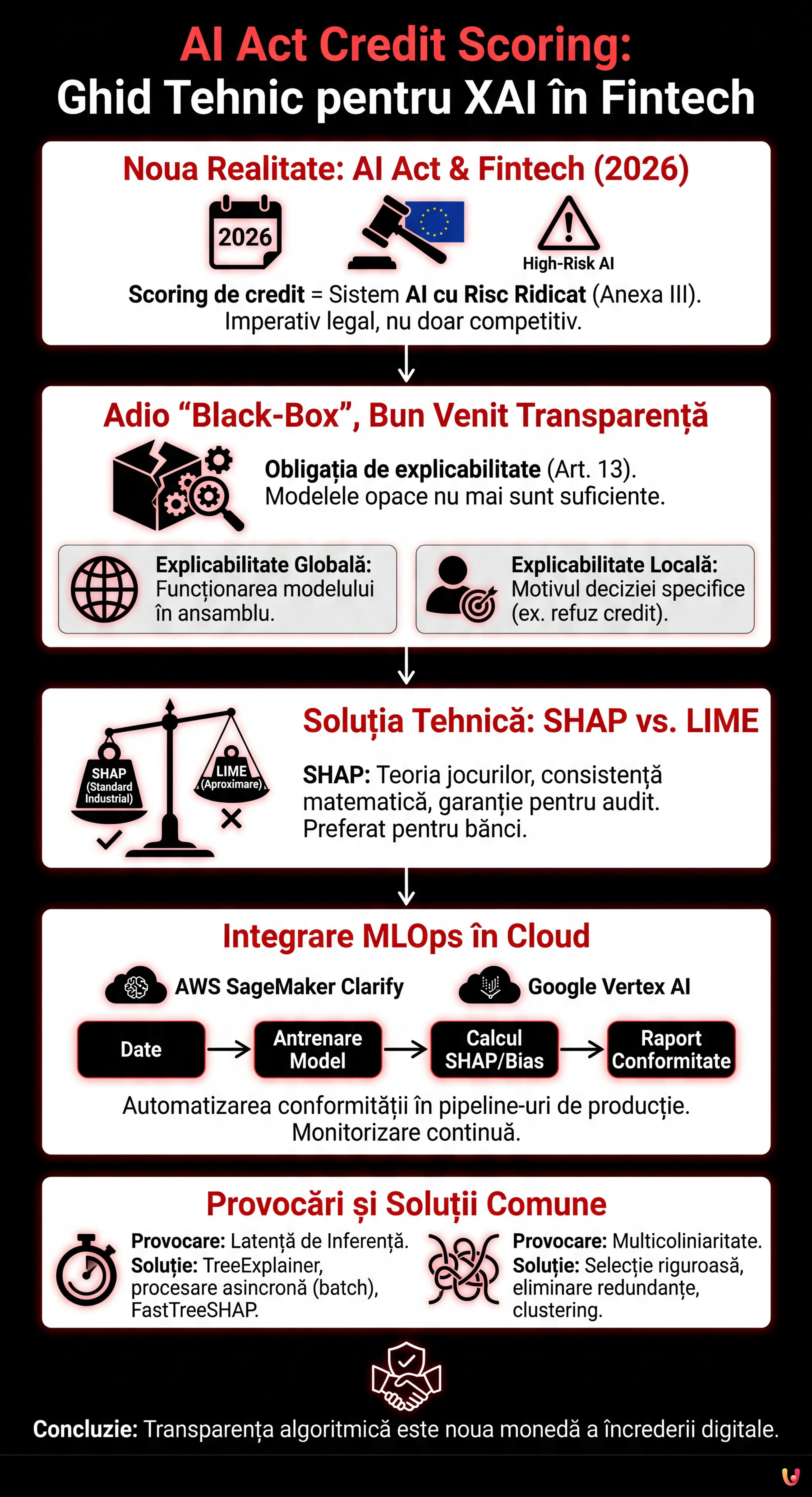
Suntem în 2026 și peisajul Fintech european s-a schimbat radical. Odată cu operaționalizarea deplină a Regulamentului European privind Inteligența Artificială, adaptarea sistemelor de ai act credit scoring nu mai este un diferențiator competitiv, ci un imperativ legal. Sistemele de evaluare a solvabilității sunt clasificate ca High-Risk AI Systems (Sisteme cu Risc Ridicat) conform Anexei III din AI Act. Acest lucru impune obligații riguroase în ceea ce privește transparența și explicabilitatea (Articolul 13).
Pentru CTO, Data Scientists și inginerii MLOps, aceasta înseamnă sfârșitul modelelor „black-box” impenetrabile. Nu mai este suficient ca un model XGBoost sau o Rețea Neuronală să aibă o AUC (Area Under Curve) de 0.95; acestea trebuie să fie capabile să explice de ce un credit ipotecar a fost refuzat unui anumit client. Acest ghid tehnic explorează implementarea Explainable AI (XAI) în pipeline-urile de producție, reducând decalajul dintre conformitatea normativă și ingineria software.

Cerința de Transparență din AI Act pentru Fintech
AI Act stabilește că sistemele cu risc ridicat trebuie proiectate astfel încât funcționarea lor să fie suficient de transparentă pentru a permite utilizatorilor să interpreteze rezultatul sistemului. În contextul scoringului de credit, acest lucru se traduce prin două niveluri de explicabilitate:
- Explicabilitate Globală: Înțelegerea modului în care funcționează modelul în ansamblu (ce caracteristici au cea mai mare greutate în general).
- Explicabilitate Locală: Înțelegerea motivului pentru care modelul a luat o decizie specifică pentru un singur individ (ex. „Creditul ipotecar a fost refuzat deoarece raportul datorie/venit depășește 40%”).
Obiectivul tehnic este transformarea vectorilor matematici complecși în notificări de acțiune adversă (Adverse Action Notices) inteligibile și justificabile legal.
Condiții Preliminare și Stack Tehnologic
Pentru a urmări acest ghid de implementare, se presupune cunoașterea limbajului Python și a principiilor de bază ale Machine Learning. Stack-ul de referință include:
- Librării ML: Scikit-learn, XGBoost sau LightGBM (standard de facto pentru date tabulare în scoringul de credit).
- Librării XAI: SHAP (SHapley Additive exPlanations) și LIME.
- Cloud Provider: AWS SageMaker sau Google Vertex AI (pentru orchestrarea MLOps).
Abandonarea Black-Box: SHAP vs LIME

Deși există modele intrinsec interpretabile (cum ar fi regresiile logistice sau Arborii de Decizie puțin adânci), adesea acestea sacrifică acuratețea predictivă. Soluția modernă este utilizarea modelelor complexe (metode ensemble) combinate cu metode de interpretare model-agnostic.
De ce să alegem SHAP pentru Scoringul de Credit
Dintre diversele opțiuni, SHAP a devenit standardul industrial pentru sectorul bancar. Spre deosebire de LIME, care aproximează modelul local, SHAP se bazează pe teoria jocurilor cooperative și garantează trei proprietăți matematice fundamentale: local accuracy, missingness și consistency. Într-un context reglementat precum cel al ai act credit scoring, consistența matematică a SHAP oferă o garanție mai mare în cazul unui audit.
Implementare Pas cu Pas: De la XGBoost la SHAP
Mai jos, un exemplu practic despre cum să integrăm SHAP într-un model de scoring de risc.
1. Antrenarea Modelului
Să presupunem că am antrenat un clasificator XGBoost pe un set de date de cereri de împrumut.
import xgboost as xgb
import shap
import pandas as pd
# Încărcarea datelor și antrenare (simplificat)
X, y = shap.datasets.adult() # Dataset exemplu
model = xgb.XGBClassifier().fit(X, y)2. Calculul Valorilor SHAP
În loc să ne limităm la predicție, calculăm valorile Shapley pentru fiecare instanță. Aceste valori indică cât de mult a contribuit fiecare caracteristică la deplasarea predicției față de media setului de date (base value).
# Inițializarea explainer-ului
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
# Exemplu: Explicație pentru clientul ID 0
print(f"Base Value: {explainer.expected_value}")
print(f"Valori SHAP Client 0: {shap_values[0]}")Dacă Base Value (probabilitatea medie de default) este 0.20 și predicția pentru client este 0.65, valorile SHAP ne vor spune exact ce variabile au adăugat acel +0.45 de risc (ex. +0.30 pentru întârzieri anterioare, +0.15 pentru vechime în muncă redusă).
Integrare MLOps în Cloud: Automatizarea Conformității
Executarea SHAP într-un notebook este simplă, dar AI Act necesită monitorizare continuă și procese scalabile. Iată cum să integrăm XAI în pipeline-uri cloud.
AWS SageMaker Clarify
AWS oferă SageMaker Clarify, un serviciu nativ care se integrează în ciclul de viață al modelului. Pentru a-l configura:
- Configurarea Procesorului: În timpul definirii jobului de training, se configurează un
SageMakerClarifyProcessor. - Analiza Bias-ului: Clarify calculează metrici de bias pre-training (ex. dezechilibre de clasă) și post-training (ex. disparități de acuratețe între grupuri demografice), esențial pentru echitatea cerută de AI Act.
- Raport de Explicabilitate: Se definește o configurație SHAP (ex.
SHAPConfig) care generează automat rapoarte JSON pentru fiecare endpoint de inferență.
Google Vertex AI Explainable AI
Similar, Vertex AI permite configurarea explanationSpec în timpul încărcării modelului. Google suportă nativ Sampled Shapley și Integrated Gradients. Avantajul aici este că explicația este returnată direct în răspunsul API împreună cu predicția, reducând latența.
Generarea Automată a „Adverse Action Notices”
Pasul final este traducerea valorilor numerice ale SHAP în limbaj natural pentru clientul final, îndeplinind obligația de notificare.
Să ne imaginăm o funcție Python care procesează rezultatul:
def genera_spiegazione(shap_values, feature_names, threshold=0.1):
spiegazioni = []
for value, name in zip(shap_values, feature_names):
if value > threshold: # Contribuție pozitivă la risc
if name == "num_ritardi_pagamento":
spiegazioni.append("Prezența întârzierilor la plățile recente a influențat negativ.")
elif name == "rapporto_debito_reddito":
spiegazioni.append("Raportul dintre datoriile tale și venit este ridicat.")
return spiegazioniAcest strat de traducere semantică este ceea ce face sistemul conform cu articolul 13 din AI Act, făcând algoritmul transparent pentru utilizatorul non-tehnic.
Depanare și Provocări Comune
În implementarea sistemelor de ai act credit scoring explicabile, se întâlnesc adesea obstacole tehnice:
1. Latența de Inferență
Calculul valorilor SHAP, în special metoda exactă pe arbori de decizie adânci, este costisitor computațional.
Soluție: Utilizați TreeExplainer (optimizat pentru arbori) în loc de KernelExplainer. În producție, calculați explicațiile asincron (procesare batch) dacă nu este necesar un răspuns real-time imediat către utilizator, sau utilizați versiuni aproximate precum FastTreeSHAP.
2. Multicoliniaritate
Dacă două caracteristici sunt puternic corelate (ex. „Venit Anual” și „Venit Lunar”), SHAP ar putea împărți importanța între cele două, făcând explicația confuză.
Soluție: Executați o Selecție a Caracteristicilor riguroasă și eliminarea caracteristicilor redundante înainte de antrenare. Utilizați tehnici de clustering ierarhic pentru a grupa caracteristicile corelate.
Concluzii

Adaptarea la AI Act în sectorul scoringului de credit nu este doar un exercițiu birocratic, ci o provocare inginerească ce ridică calitatea software-ului financiar. Implementând arhitecturi bazate pe XAI precum SHAP și integrându-le în pipeline-uri MLOps robuste pe SageMaker sau Vertex AI, companiile Fintech pot garanta nu doar conformitatea legală, ci și o încredere sporită din partea consumatorilor. Transparența algoritmică este noua monedă a creditului digital.
Întrebări frecvente

Regulamentul AI clasifică sistemele de evaluare a solvabilității ca sisteme cu risc ridicat conform Anexei III. Această definiție impune companiilor Fintech obligații severe de transparență și explicabilitate, forțând abandonarea modelelor de tip cutie neagră. Acum este necesar ca algoritmii să ofere motivații inteligibile pentru fiecare decizie luată, în special în cazul refuzului unui împrumut.
Explicabilitatea globală permite înțelegerea funcționării modelului în ansamblul său, identificând care variabile au cea mai mare greutate în general. Explicabilitatea locală, în schimb, este fundamentală pentru conformitatea normativă deoarece clarifică de ce modelul a luat o decizie specifică pentru un singur client, permițând generarea de notificări precise privind cauzele unui rezultat negativ.
SHAP a devenit standardul industrial deoarece se bazează pe teoria jocurilor cooperative și garantează proprietăți matematice precum consistența, esențială în faza de audit. Spre deosebire de LIME care oferă aproximări locale, SHAP calculează contribuția exactă a fiecărei caracteristici față de medie, oferind o justificare a scorului de credit mai solidă din punct de vedere legal.
Pentru a automatiza conformitatea se pot utiliza servicii gestionate precum AWS SageMaker Clarify sau Google Vertex AI. Aceste instrumente se integrează în ciclul de viață al modelului pentru a calcula metrici de bias și a genera automat rapoarte de explicabilitate SHAP pentru fiecare inferență, garantând o monitorizare continuă fără intervenție manuală excesivă.
Calculul valorilor SHAP poate fi oneros computațional și poate încetini răspunsurile. Pentru a atenua problema se recomandă utilizarea TreeExplainer care este optimizat pentru arborii de decizie, sau mutarea calculului în procese asincrone batch dacă nu este necesar un răspuns imediat. O altă soluție eficientă este utilizarea aproximărilor rapide precum FastTreeSHAP.
Surse și Aprofundare


Ați găsit acest articol util? Există un alt subiect pe care ați dori să-l tratez?
Scrieți-l în comentariile de mai jos! Mă inspir direct din sugestiile voastre.