In Breve (TL;DR)
L’architettura Data Lakehouse unifica dati strutturati e documenti complessi come PDF in un unico ambiente cloud performante ed economico.
BigQuery e Document AI permettono di interrogare file grezzi via SQL, trasformando processi manuali in pipeline automatizzate e intelligenti.
Questa strategia valorizza i Dark Data finanziari, offrendo ai CTO una gestione unificata per analisi predittive e operative in tempo reale.
Il diavolo è nei dettagli. 👇 Continua a leggere per scoprire i passaggi critici e i consigli pratici per non sbagliare.
Nel panorama finanziario odierno, e in particolare nel settore dei mutui, il vero valore non risiede solo nei database strutturati, ma in una miniera d’oro spesso inutilizzata: i documenti non strutturati. Buste paga, perizie immobiliari, rogiti notarili e documenti d’identità costituiscono quello che viene spesso definito Dark Data. La sfida per i CTO e i Data Architect nel 2026 non è più solo archiviare questi file, ma renderli interrogabili in tempo reale insieme ai dati transazionali.
In questo articolo tecnico, esploreremo come progettare e implementare un’architettura data lakehouse google cloud capace di abbattere i silos tra il data lake (dove risiedono i PDF) e il data warehouse (dove risiedono i dati CRM). Utilizzeremo la potenza di BigQuery, l’intelligenza di Document AI e le capacità predittive di Vertex AI per trasformare un processo di istruttoria manuale in una pipeline automatizzata e sicura.

Il Paradigma Data Lakehouse nel Fintech
Tradizionalmente, le banche mantenevano due stack separati: un Data Lake (es. Google Cloud Storage) per i file grezzi e un Data Warehouse (es. database SQL legacy o primi MPP) per la Business Intelligence. Questo approccio comportava duplicazione dei dati, latenza elevata e disallineamento delle informazioni.
Il Data Lakehouse su Google Cloud Platform (GCP) risolve questo problema permettendo di trattare i file archiviati nello storage a oggetti come se fossero tabelle di un database relazionale, mantenendo però i costi bassi dello storage e le performance elevate del warehouse.
Componenti Chiave dell’Architettura
- Google Cloud Storage (GCS): Il livello di storage fisico per i documenti (PDF, JPG, TIFF).
- BigQuery (BQ): Il cuore del Lakehouse. Gestisce sia i dati strutturati (CRM) che i metadati dei file non strutturati tramite Object Tables.
- Document AI: Il servizio di elaborazione intelligente dei documenti (IDP) per estrarre entità chiave.
- Vertex AI: Per l’addestramento di modelli di credit scoring basati sui dati unificati.
Fase 1: Design dell’Architettura e Ingestione
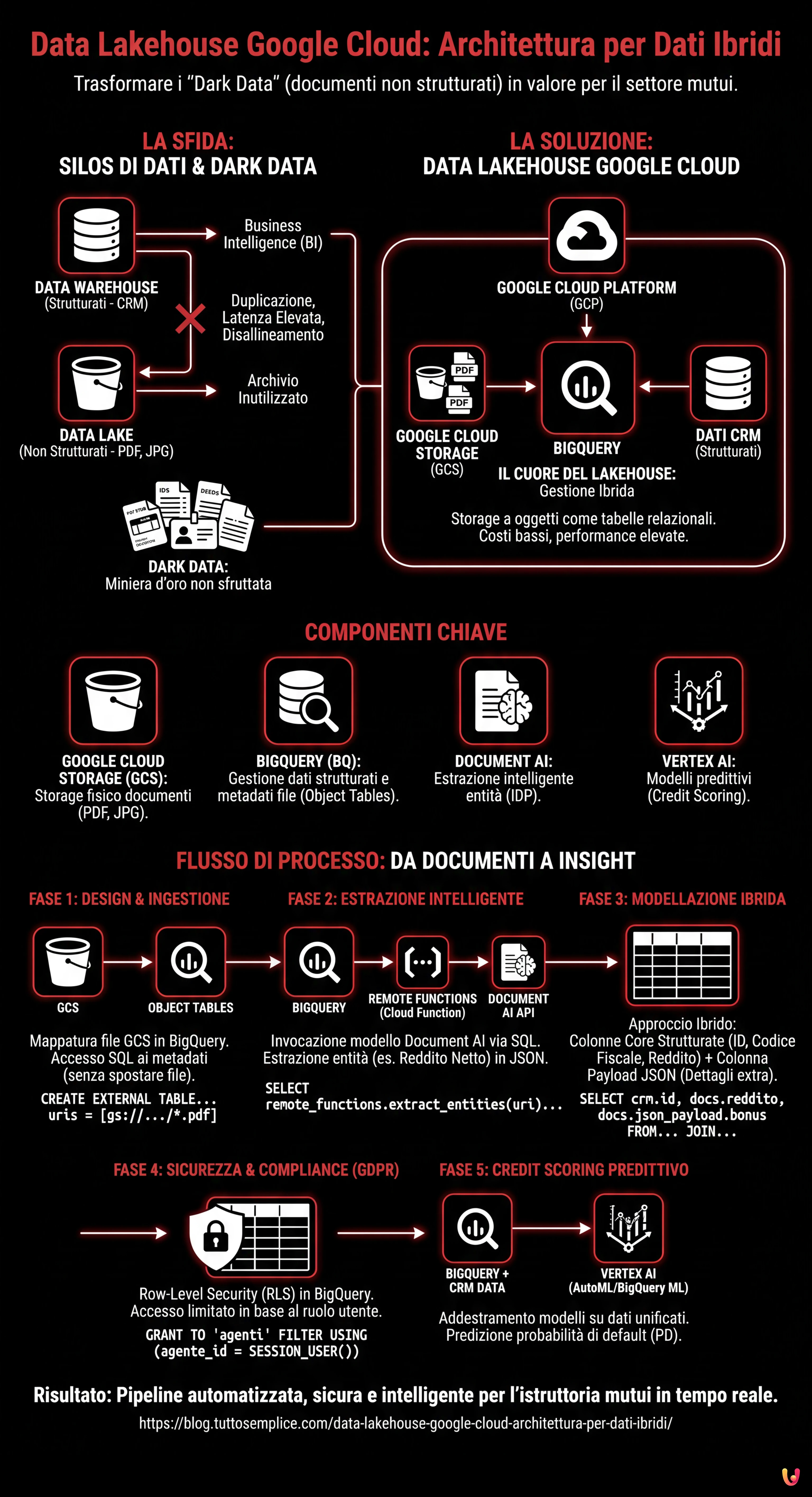
Il primo passo per costruire un data lakehouse google cloud efficace è strutturare correttamente il livello di ingestione. Non stiamo semplicemente caricando file; stiamo preparando il terreno per l’analisi.
Configurazione delle Object Tables in BigQuery
A partire dagli aggiornamenti recenti di GCP, BigQuery permette di creare Object Tables. Queste sono tabelle di sola lettura che mappano i file presenti in un bucket GCS. Questo ci permette di vedere i PDF delle buste paga direttamente dentro BigQuery senza spostarli.
CREATE OR REPLACE EXTERNAL TABLE `fintech_lakehouse.raw_documents`
WITH CONNECTION `us.my-connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://mutui-docs-bucket/*.pdf']
);Con questa singola istruzione SQL, abbiamo reso il nostro archivio documentale accessibile via SQL. Possiamo interrogare i metadati (data creazione, dimensione, nome file) come se fossero colonne strutturate.
Fase 2: Estrazione Intelligente con Document AI e Remote Functions

Avere i file listati in BigQuery non basta. Dobbiamo leggerne il contenuto. Qui entra in gioco l’integrazione tra BigQuery e Document AI tramite le Remote Functions (Funzioni Remote).
Invece di costruire complesse pipeline ETL con Dataflow o script Python esterni, possiamo invocare il modello di estrazione direttamente da una query SQL. Immaginiamo di dover estrarre il “Reddito Netto” e il “Datore di Lavoro” dalle buste paga.
1. Creazione del Processore Document AI
Nella console GCP, configuriamo un processore Lending Document Splitter & Parser (specifico per il settore mutui) o un processore Custom Extractor addestrato sulle specifiche buste paga italiane.
2. Implementazione della Remote Function
Creiamo una Cloud Function (Gen 2) che funge da ponte. Questa funzione riceve l’URI del file da BigQuery, chiama l’API di Document AI e restituisce un oggetto JSON con le entità estratte.
3. Estrazione via SQL
Ora possiamo arricchire i nostri dati grezzi trasformandoli in informazioni strutturate:
CREATE OR REPLACE TABLE `fintech_lakehouse.extracted_income_data` AS
SELECT
uri,
remote_functions.extract_entities(uri) AS json_data
FROM
`fintech_lakehouse.raw_documents`
WHERE
content_type = 'application/pdf';Il risultato è una tabella che contiene il link al documento originale e una colonna JSON con i dati estratti. Questo è il vero potere del data lakehouse google cloud: dati non strutturati convertiti in strutturati on-the-fly.
Fase 3: Modellazione dei Dati e Ottimizzazione Schema
Una volta estratti i dati, come dobbiamo memorizzarli? Nel contesto dei mutui, la flessibilità è fondamentale, ma le performance delle query sono prioritarie.
Approccio Ibrido: Colonne Strutturate + JSON
Sconsigliamo di appiattire completamente ogni singolo campo estratto in una colonna dedicata, poiché i formati documentali cambiano. L’approccio migliore è:
- Colonne Core (Strutturate): ID Pratica, Codice Fiscale, Reddito Mensile, Data Assunzione. Queste colonne devono essere tipizzate (INT64, STRING, DATE) per permettere join veloci con le tabelle del CRM e ottimizzare i costi di storage (BigQuery Capacitor format).
- Colonna Payload (JSON): Tutto il resto dell’estrazione (dettagli minori, note a margine) rimane in una colonna di tipo
JSON. BigQuery supporta nativamente l’accesso ai campi JSON con una sintassi efficiente.
Esempio di query analitica unificata:
SELECT
crm.customer_id,
crm.risk_score_preliminare,
docs.reddito_mensile,
SAFE_CAST(docs.json_payload.dettagli_extra.bonus_produzione AS FLOAT64) as bonus
FROM
`fintech_lakehouse.crm_customers` crm
JOIN
`fintech_lakehouse.extracted_income_data` docs
ON
crm.tax_code = docs.codice_fiscale
WHERE
docs.reddito_mensile > 2000;Fase 4: Sicurezza e Compliance GDPR (Row-Level Security)
Trattando dati sensibili come redditi e perizie, la sicurezza non è opzionale. Il GDPR impone che l’accesso ai dati personali sia limitato al personale strettamente necessario.
In un data lakehouse google cloud, non è necessario creare viste separate per ogni gruppo di utenti. Utilizziamo la Row-Level Security (RLS) di BigQuery.
Implementazione delle Policy di Accesso
Supponiamo di avere due gruppi di utenti: Analisti Rischio (accesso completo) e Agenti Commerciali (accesso limitato solo alle proprie pratiche).
CREATE ROW ACCESS POLICY commercial_filter
ON `fintech_lakehouse.extracted_income_data`
GRANT TO ('group:agenti-commerciali@banca.it')
FILTER USING (agente_id = SESSION_USER());Con questa policy, quando un agente esegue una SELECT *, BigQuery filtrerà automaticamente i risultati, mostrando solo le righe dove l’agente_id corrisponde all’utente loggato. I dati sensibili degli altri clienti rimangono invisibili, garantendo la compliance normativa senza duplicare i dati.
Fase 5: Credit Scoring Predittivo con Vertex AI
L’ultimo miglio del nostro Lakehouse è l’attivazione del dato. Ora che abbiamo unito i dati comportamentali (storico pagamenti dal CRM) con i dati reddituali reali (estratti dalle buste paga), possiamo addestrare modelli di Machine Learning superiori.
Utilizzando Vertex AI integrato con BigQuery, possiamo creare un modello di regressione logistica o una rete neurale per predire la probabilità di default (PD).
- Feature Engineering: Creiamo una vista in BigQuery che unisce le tabelle CRM e Documentali.
- Training: Usiamo
CREATE MODELdirettamente in SQL (BigQuery ML) o esportiamo il dataset su Vertex AI per l’AutoML. - Prediction: Il modello addestrato può essere richiamato in batch ogni notte per ricalcolare il punteggio di rischio di tutte le pratiche aperte, segnalando anomalie tra il reddito dichiarato e quello estratto dai documenti.
Conclusioni

Implementare un data lakehouse google cloud nel settore dei mutui trasforma radicalmente l’operatività. Non si tratta solo di tecnologia, ma di velocità di business: passare da giorni a minuti per la pre-approvazione di un mutuo.
L’architettura presentata, basata sull’integrazione stretta tra BigQuery, GCS e Document AI, offre tre vantaggi competitivi immediati:
- Unificazione: Un’unica fonte di verità per dati strutturati e non.
- Automazione: Riduzione dell’intervento umano nell’estrazione dati (Data Entry).
- Compliance: Controllo granulare degli accessi nativo nel database.
Per le istituzioni finanziarie che guardano al 2026 e oltre, questa convergenza tra gestione documentale e analisi dati rappresenta lo standard de facto per rimanere competitivi in un mercato sempre più guidato dagli algoritmi.
Domande frequenti

Un Data Lakehouse su Google Cloud è un architettura ibrida che combina la flessibilità di archiviazione economica dei Data Lake con le prestazioni di analisi dei Data Warehouse. Nel settore finanziario, questo approccio permette di eliminare i silos tra dati strutturati e documenti non strutturati, come i PDF, consentendo interrogazioni SQL unificate. I vantaggi principali includono la riduzione della duplicazione dei dati, l abbattimento dei costi di storage e la capacità di ottenere insight in tempo reale per processi come l approvazione dei mutui.
L analisi dei PDF in BigQuery avviene tramite l utilizzo delle Object Tables, che mappano i file presenti in Google Cloud Storage come tabelle di sola lettura. Per estrarre i dati contenuti nei documenti, si integrano le Remote Functions che collegano BigQuery ai servizi di Document AI. Questo permette di invocare modelli di estrazione intelligente direttamente tramite query SQL, trasformando informazioni non strutturate, come il reddito netto di una busta paga, in dati strutturati pronti per l analisi.
La sicurezza dei dati sensibili e la conformità al GDPR sono gestite attraverso la Row-Level Security (RLS) nativa di BigQuery. Invece di creare copie multiple dei dati per diversi team, la RLS permette di definire policy di accesso granulari che filtrano le righe visibili in base all utente connesso. Ad esempio, un analista del rischio può vedere tutti i dati, mentre un agente commerciale visualizzerà solo le pratiche dei propri clienti, garantendo la privacy senza duplicazioni.
Vertex AI potenzia il credit scoring utilizzando i dati unificati del Lakehouse per addestrare modelli di Machine Learning avanzati. Unendo lo storico dei pagamenti presente nel CRM con i dati reddituali reali estratti dai documenti tramite Document AI, è possibile creare modelli predittivi più accurati. Questi algoritmi possono calcolare la probabilità di default e rilevare anomalie tra il reddito dichiarato e quello effettivo, automatizzando e rendendo più sicura la valutazione del rischio.
I pilastri di questa architettura includono Google Cloud Storage per l archiviazione fisica dei file grezzi e BigQuery come motore centrale per l analisi di dati strutturati e metadati. A questi si aggiungono Document AI per l elaborazione intelligente dei documenti (IDP) e l estrazione delle entità, e Vertex AI per l applicazione di modelli predittivi sui dati consolidati. Questa combinazione trasforma un semplice archivio in una piattaforma analitica attiva e automatizzata.
Fonti e Approfondimenti

- Wikipedia – Definizione e architettura del Data Lakehouse
- Wikipedia – Definizione di Dark Data (Dati oscuri)
- Banca d’Italia – Fintech e innovazione nel sistema finanziario
- Commissione Europea – L’approccio europeo all’Intelligenza Artificiale
- Garante per la protezione dei dati personali – Privacy nel settore bancario

Hai trovato utile questo articolo? C'è un altro argomento che vorresti vedermi affrontare?
Scrivilo nei commenti qui sotto! Prendo ispirazione direttamente dai vostri suggerimenti.