In Brief (TL;DR)
The RAG architecture revolutionizes financial analysis by transforming complex policies into immediate knowledge, reducing verification times from hours to seconds.
A robust pipeline requires advanced semantic chunking to handle tables and legal structures typical of unstructured banking documents.
Answer precision is ensured by prompts that prevent hallucinations and enforce verifiable references to original regulatory sources.
The devil is in the details. 👇 Keep reading to discover the critical steps and practical tips to avoid mistakes.
In today’s financial landscape, information processing speed has become a crucial competitive advantage. For credit brokerage firms and banks, the main challenge is not a lack of data, but its fragmentation across unstructured documents. Implementing a fintech RAG architecture (Retrieval-Augmented Generation) represents the ultimate solution for transforming operating manuals and mortgage origination policies into actionable knowledge.
Imagine a common scenario: a broker needs to verify mortgage feasibility for a client with foreign income by consulting the policies of 20 different institutions. Manually, this takes hours. With a well-designed RAG system, as demonstrated by the evolution of advanced CRM platforms like BOMA, the time is reduced to a few seconds. However, the financial sector does not tolerate errors: a Large Language Model (LLM) hallucination can lead to an incorrect decision and compliance risks.
This technical guide explores how to build a robust RAG pipeline, focusing on the specificities of the banking domain: from managing complex PDFs to rigorous source citation.

Ingestion Pipeline: From PDF to Vector
The heart of an effective fintech RAG architecture lies in the quality of input data. Banking policies are often distributed in PDF format, rich in tables (e.g., LTV/Income grids), footnotes, and interdependent legal clauses. A simple text parser would fail to preserve the necessary logical structure.
Semantic Chunking Strategies
Dividing text into segments (chunking) is a critical step. In the credit context, cutting a paragraph in half can alter the meaning of an exclusion rule. According to current best practices for document processing:
- Hierarchical Chunking: Instead of dividing by a fixed number of tokens, it is essential to respect the document structure (Title, Article, Subsection). Using libraries like LangChain or LlamaIndex allows configuring splitters that recognize legal document headers.
- Contextual Overlap: It is advisable to maintain a 15-20% overlap between chunks to ensure context is not lost at the cut margins.
- Table Management: Tables must be extracted, linearized into markdown or JSON format, and embedded as unique semantic units. If a table is broken up, the model will not be able to correctly associate rows and columns during the retrieval phase.
Choosing the Vector Database: Pinecone vs pgvector
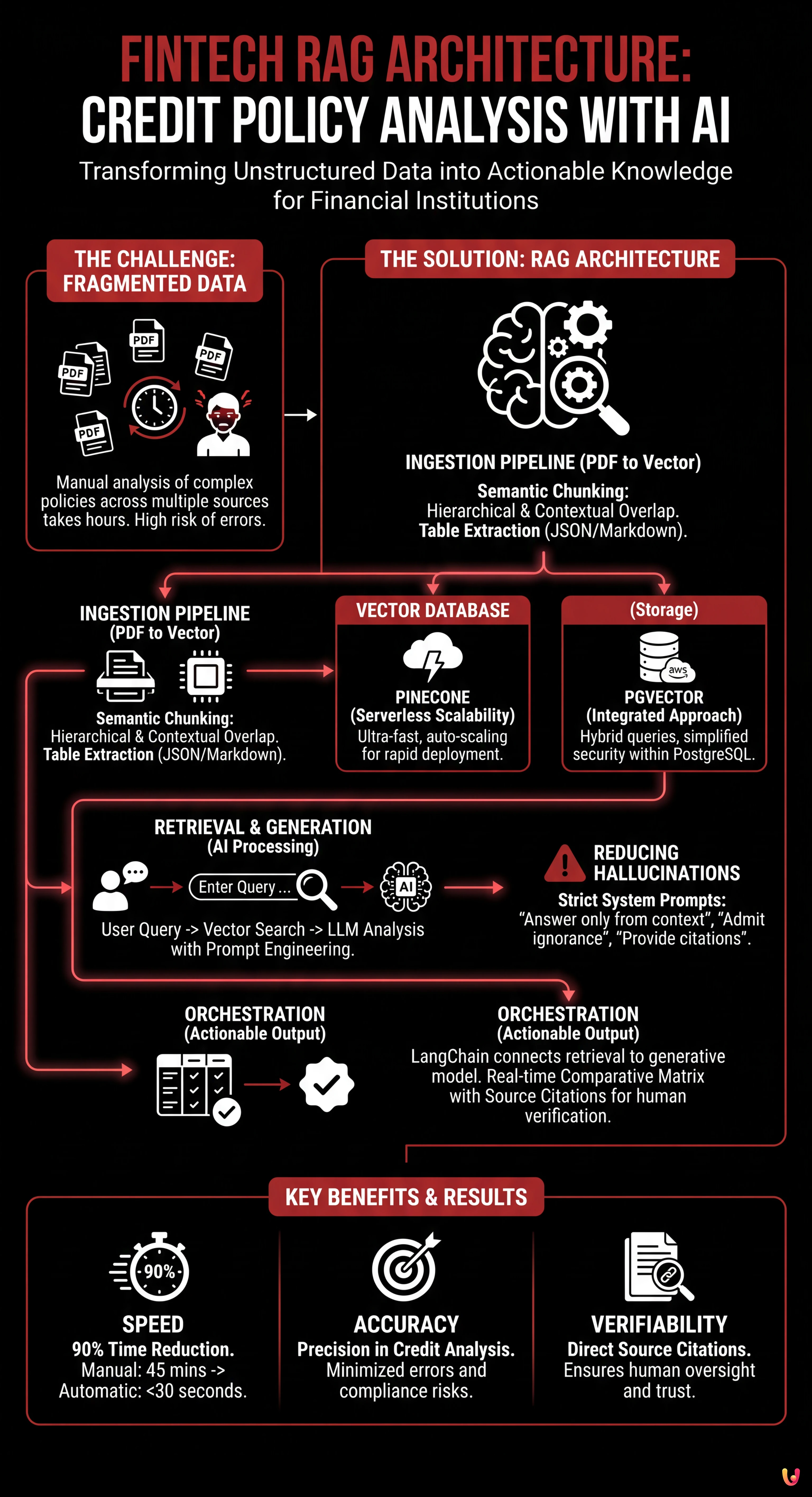
Once chunks are transformed into numerical vectors (embeddings), they need to be stored in a vector database. The choice of infrastructure impacts latency and costs.
Pinecone: Serverless Scalability
For projects requiring rapid deployment and automatic scalability, Pinecone remains a reference standard. Its serverless architecture automatically handles indexing and offers response times in the order of milliseconds, essential for a fluid user experience in a CRM.
pgvector on AWS RDS: The Integrated Approach
However, for financial institutions already using PostgreSQL on AWS RDS for transactional data, the pgvector extension offers significant advantages. Keeping vectors in the same database as customer data simplifies security management and allows for hybrid queries (e.g., filtering vectors not only by semantic similarity but also by relational metadata like “Bank ID” or “Policy Validity Date”). This reduces infrastructure complexity and data egress costs.
Reducing Hallucinations: Prompt Engineering and Citations

In the fintech sector, precision is non-negotiable. A fintech RAG architecture must be designed to admit ignorance rather than inventing an answer. Prompt engineering plays a fundamental role here.
It is necessary to implement a rigorous System Prompt that instructs the model to:
- Answer exclusively based on the provided context (the retrieved chunks).
- State “I do not have sufficient information” if the policy does not cover the specific case.
- Provide the exact citation (e.g., “Page 12, Article 4.2”).
Technically, this is achieved by structuring the LLM output not as free text, but as a structured object (JSON) that must contain separate fields for the answer and for source references. This allows the application frontend to show the operator the direct link to the original PDF, ensuring human verifiability of the data.
Orchestration with LangChain: The Practical Use Case
Final orchestration occurs via frameworks like LangChain, which connect retrieval to the generative model. In a real-world use case for mortgage pre-qualification, the operational flow is as follows:
The user enters customer data (e.g., “Self-employed, flat-rate tax scheme, 80% LTV”). The system converts this query into a vector and simultaneously queries the vector indices of 20 credit institutions. The system retrieves the top-3 most relevant chunks for each bank.
Subsequently, the LLM analyzes the retrieved chunks to determine eligibility. The result is a comparative matrix generated in real-time, highlighting which banks would accept the application and with what limitations. According to data collected during the development of similar solutions, this approach reduces pre-qualification times by 90%, moving from a manual analysis of 45 minutes to an automatic output in less than 30 seconds.
Conclusions

Implementing a fintech RAG architecture for credit policy analysis is not just a technological exercise, but a strategic lever for operational efficiency. The key to success lies not in the most powerful language model, but in the care taken with the data ingestion pipeline and rigorous context management. By using semantic chunking strategies and optimized vector databases, it is possible to create virtual assistants that not only understand banking language but act as compliance guarantors, offering precise, verified, and traceable answers.
Frequently Asked Questions

A fintech RAG architecture, standing for Retrieval-Augmented Generation, is a technology that combines information retrieval in document databases with the generative capability of artificial intelligence. In the financial sector, it serves to transform unstructured documents, such as operating manuals and credit policies in PDF format, into immediately accessible knowledge. This allows banks and brokers to rapidly query huge amounts of data to verify the feasibility of mortgages and loans, reducing manual analysis times from hours to a few seconds.
To ensure the necessary precision in banking and avoid answers invented by the model, it is fundamental to implement a rigorous System Prompt. This instructs the artificial intelligence to answer exclusively based on text segments retrieved from official documents and to admit ignorance if the information is missing. Furthermore, the system must be configured to provide exact citations of sources, allowing human operators to directly verify the article or page of the original document from which the information comes.
Effective management of documents rich in tables and legal notes requires the use of semantic chunking strategies rather than simple division by character count. It is essential to respect the hierarchical structure of the document, keeping articles and subsections intact, and to use contextual overlap between segments. Tables, particularly those with LTV or income grids, must be extracted and linearized into structured formats like JSON or markdown so that the model can correctly interpret data relationships during retrieval.
The choice of vector database depends on the infrastructure priorities of the financial institution. Pinecone is often the best choice for those needing immediate serverless scalability and minimal latency without complex management. Conversely, pgvector on AWS RDS is ideal for entities already using PostgreSQL for transactional data, as it allows for hybrid queries by filtering results by both semantic similarity and relational metadata, simplifying security and reducing data movement costs.
Implementing a well-designed RAG pipeline can drastically reduce operational times. According to data collected during the development of similar solutions, the time required for application pre-qualification can decrease by 90 percent. In fact, it moves from a manual analysis that could take about 45 minutes to consult various banking policies, to an automatic and comparative output generated in less than 30 seconds, significantly improving efficiency and responsiveness to the end customer.
Sources and Further Reading


Did you find this article helpful? Is there another topic you'd like to see me cover?
Write it in the comments below! I take inspiration directly from your suggestions.