En Bref (TL;DR)
Le Règlement Européen sur l’Intelligence Artificielle classe le credit scoring comme système à haut risque, imposant des obligations strictes de transparence et d’explicabilité.
Les Data Scientists doivent abandonner les modèles black-box en adoptant des bibliothèques d’Explainable AI comme SHAP pour garantir des décisions interprétables et mathématiquement cohérentes.
L’intégration d’outils comme AWS SageMaker Clarify dans les pipelines MLOps permet d’automatiser la conformité réglementaire en surveillant les biais et l’explicabilité en production.
Le diable est dans les détails. 👇 Continuez à lire pour découvrir les étapes critiques et les conseils pratiques pour ne pas vous tromper.
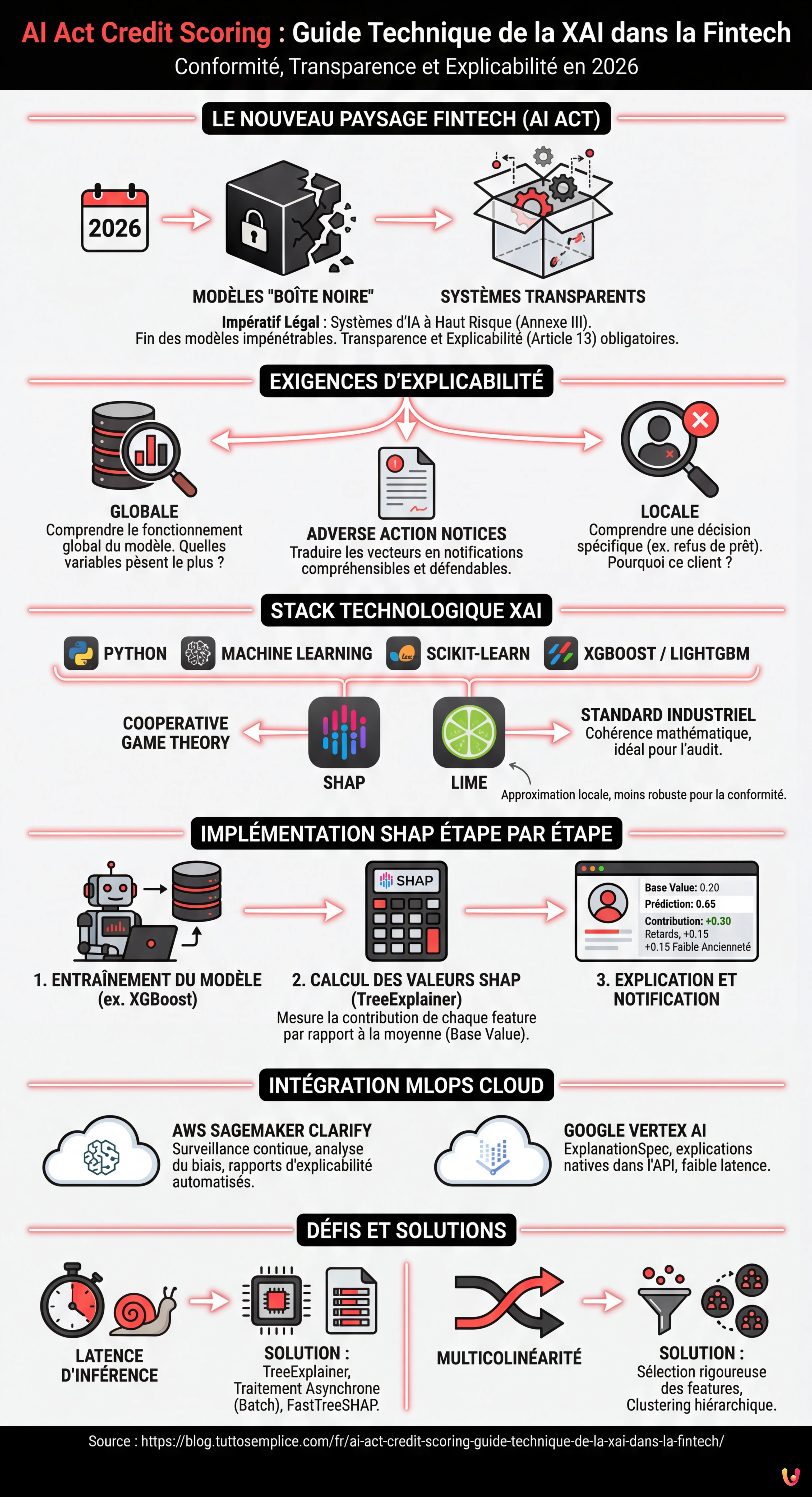
Nous sommes en 2026 et le paysage de la Fintech européenne a radicalement changé. Avec la pleine entrée en vigueur du Règlement Européen sur l’Intelligence Artificielle, l’adaptation des systèmes d’ai act credit scoring n’est plus un avantage concurrentiel, mais un impératif légal. Les systèmes d’évaluation du mérite de crédit sont classés comme High-Risk AI Systems (Systèmes d’IA à Haut Risque) selon l’Annexe III de l’AI Act. Cela impose des obligations strictes en termes de transparence et d’explicabilité (Article 13).
Pour les CTO, les Data Scientists et les ingénieurs MLOps, cela signifie la fin des modèles « boîte noire » (black-box) impénétrables. Il ne suffit plus qu’un modèle XGBoost ou qu’un Réseau de Neurones ait une AUC (Area Under Curve) de 0.95 ; ils doivent être capables d’expliquer pourquoi un prêt a été refusé à un client spécifique. Ce guide technique explore l’implémentation de l’Explainable AI (XAI) dans les pipelines de production, comblant le fossé entre la conformité réglementaire et l’ingénierie logicielle.

L’Exigence de Transparence dans l’AI Act pour la Fintech
L’AI Act stipule que les systèmes à haut risque doivent être conçus de manière à ce que leur fonctionnement soit suffisamment transparent pour permettre aux utilisateurs d’interpréter la sortie du système. Dans le contexte du credit scoring, cela se traduit par deux niveaux d’explicabilité :
- Explicabilité Globale : Comprendre comment le modèle fonctionne dans son ensemble (quelles variables pèsent le plus en général).
- Explicabilité Locale : Comprendre pourquoi le modèle a pris une décision spécifique pour un individu donné (ex. « Le prêt a été refusé car le ratio dette/revenu dépasse 40% »).
L’objectif technique est de transformer des vecteurs mathématiques complexes en notifications d’action défavorable (Adverse Action Notices) compréhensibles et juridiquement défendables.
Prérequis et Stack Technologique
Pour suivre ce guide d’implémentation, une connaissance de Python et des principes de base du Machine Learning est présumée. La stack de référence comprend :
- Bibliothèques ML : Scikit-learn, XGBoost ou LightGBM (standards de facto pour les données tabulaires dans le credit scoring).
- Bibliothèques XAI : SHAP (SHapley Additive exPlanations) et LIME.
- Fournisseurs Cloud : AWS SageMaker ou Google Vertex AI (pour l’orchestration MLOps).
Abandonner la Boîte Noire : SHAP vs LIME

Bien qu’il existe des modèles intrinsèquement interprétables (comme les régressions logistiques ou les arbres de décision peu profonds), ceux-ci sacrifient souvent la précision prédictive. La solution moderne est l’utilisation de modèles complexes (méthodes d’ensemble) combinés à des méthodes d’interprétation model-agnostic.
Pourquoi choisir SHAP pour le Credit Scoring
Parmi les différentes options, SHAP est devenu le standard industriel pour le secteur bancaire. Contrairement à LIME, qui approxime le modèle localement, SHAP se base sur la théorie des jeux coopératifs et garantit trois propriétés mathématiques fondamentales : local accuracy, missingness et consistency. Dans un contexte réglementé comme celui de l’ai act credit scoring, la cohérence mathématique de SHAP offre une garantie supérieure en cas d’audit.
Implémentation Étape par Étape : De XGBoost à SHAP
Ci-dessous, un exemple pratique de la manière d’intégrer SHAP dans un modèle de scoring de risque.
1. Entraînement du Modèle
Supposons que nous ayons entraîné un classificateur XGBoost sur un jeu de données de demandes de prêt.
import xgboost as xgb
import shap
import pandas as pd
# Chargement des données et entraînement (simplifié)
X, y = shap.datasets.adult() # Jeu de données exemple
model = xgb.XGBClassifier().fit(X, y)2. Calcul des Valeurs SHAP
Au lieu de nous limiter à la prédiction, nous calculons les valeurs de Shapley pour chaque instance. Ces valeurs indiquent dans quelle mesure chaque feature a contribué à déplacer la prédiction par rapport à la moyenne du jeu de données (base value).
# Initialisation de l'explainer
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
# Exemple : Explication pour le client ID 0
print(f"Base Value: {explainer.expected_value}")
print(f"SHAP Values Client 0: {shap_values[0]}")Si la Base Value (probabilité moyenne de défaut) est de 0.20 et la prédiction pour le client est de 0.65, les valeurs SHAP nous diront exactement quelles variables ont ajouté ce +0.45 de risque (ex. +0.30 pour des retards passés, +0.15 pour une faible ancienneté professionnelle).
Intégration MLOps sur le Cloud : Automatiser la Conformité
Exécuter SHAP dans un notebook est simple, mais l’AI Act exige une surveillance continue et des processus évolutifs. Voici comment intégrer la XAI dans des pipelines cloud.
AWS SageMaker Clarify
AWS propose SageMaker Clarify, un service natif qui s’intègre au cycle de vie du modèle. Pour le configurer :
- Configuration du Processeur : Lors de la définition du job d’entraînement, on configure un
SageMakerClarifyProcessor. - Analyse du Biais : Clarify calcule des métriques de biais pré-entraînement (ex. déséquilibres de classe) et post-entraînement (ex. disparités de précision entre groupes démographiques), essentiel pour l’équité requise par l’AI Act.
- Rapport d’Explicabilité : On définit une configuration SHAP (ex.
SHAPConfig) qui génère automatiquement des rapports JSON pour chaque endpoint d’inférence.
Google Vertex AI Explainable AI
De manière similaire, Vertex AI permet de configurer l’explanationSpec lors du chargement du modèle. Google supporte nativement Sampled Shapley et Integrated Gradients. L’avantage ici est que l’explication est renvoyée directement dans la réponse API avec la prédiction, réduisant la latence.
Génération Automatique des « Adverse Action Notices »
L’étape finale consiste à traduire les valeurs numériques de SHAP en langage naturel pour le client final, satisfaisant ainsi l’obligation de notification.
Imaginons une fonction Python qui traite la sortie :
def generer_explication(shap_values, feature_names, threshold=0.1):
explications = []
for value, name in zip(shap_values, feature_names):
if value > threshold: # Contribution positive au risque
if name == "nb_retards_paiement":
explications.append("La présence de retards dans les paiements récents a influé négativement.")
elif name == "ratio_dette_revenu":
explications.append("Le ratio entre vos dettes et vos revenus est élevé.")
return explicationsCette couche de traduction sémantique est ce qui rend le système conforme à l’article 13 de l’AI Act, rendant l’algorithme transparent pour l’utilisateur non technique.
Dépannage et Défis Courants
Lors de l’implémentation de systèmes d’ai act credit scoring explicables, on rencontre souvent des obstacles techniques :
1. Latence d’Inférence
Le calcul des valeurs SHAP, en particulier la méthode exacte sur des arbres de décision profonds, est coûteux en calcul.
Solution : Utiliser TreeExplainer (optimisé pour les arbres) au lieu de KernelExplainer. En production, calculer les explications de manière asynchrone (traitement par lots) si une réponse en temps réel immédiate n’est pas requise pour l’utilisateur, ou utiliser des versions approximées comme FastTreeSHAP.
2. Multicolinéarité
Si deux features sont fortement corrélées (ex. « Revenu Annuel » et « Revenu Mensuel »), SHAP pourrait diviser l’importance entre les deux, rendant l’explication confuse.
Solution : Exécuter une sélection rigoureuse des features et supprimer les features redondantes avant l’entraînement. Utiliser des techniques de clustering hiérarchique pour regrouper les features corrélées.
Conclusions

L’adaptation à l’AI Act dans le secteur du credit scoring n’est pas seulement un exercice bureaucratique, mais un défi d’ingénierie qui élève la qualité du logiciel financier. En implémentant des architectures basées sur la XAI comme SHAP et en les intégrant dans des pipelines MLOps robustes sur SageMaker ou Vertex AI, les entreprises Fintech peuvent garantir non seulement la conformité légale, mais aussi une plus grande confiance de la part des consommateurs. La transparence algorithmique est la nouvelle monnaie du crédit numérique.
Foire aux questions

Le règlement IA classe les systèmes d évaluation du mérite de crédit comme des systèmes à haut risque selon l Annexe III. Cette définition impose aux entreprises Fintech des obligations sévères de transparence et d explicabilité, obligeant à abandonner les modèles à boîte noire. Il est désormais nécessaire que les algorithmes fournissent des motivations compréhensibles pour chaque décision prise, particulièrement en cas de refus d un prêt.
L explicabilité globale permet de comprendre le fonctionnement du modèle dans son ensemble, en identifiant quelles variables ont le plus de poids en général. L explicabilité locale, en revanche, est fondamentale pour la conformité réglementaire car elle clarifie pourquoi le modèle a pris une décision spécifique pour un client unique, permettant de générer des notifications précises sur les causes d un résultat négatif.
SHAP est devenu le standard industriel car il se base sur la théorie des jeux coopératifs et garantit des propriétés mathématiques comme la cohérence, essentielle en phase d audit. Contrairement à LIME qui fournit des approximations locales, SHAP calcule la contribution exacte de chaque caractéristique par rapport à la moyenne, offrant une justification du score de crédit juridiquement plus solide.
Pour automatiser la conformité, il est possible d utiliser des services gérés comme AWS SageMaker Clarify ou Google Vertex AI. Ces outils s intègrent dans le cycle de vie du modèle pour calculer des métriques de biais et générer automatiquement des rapports d explicabilité SHAP pour chaque inférence, garantissant une surveillance continue sans intervention manuelle excessive.
Le calcul des valeurs SHAP peut être coûteux en calcul et ralentir les réponses. Pour atténuer le problème, il est conseillé d utiliser TreeExplainer qui est optimisé pour les arbres de décision, ou de déplacer le calcul vers des processus asynchrones par lots si une réponse immédiate n est pas nécessaire. Une autre solution efficace est l utilisation d approximations rapides comme FastTreeSHAP.
Sources et Approfondissements

- Texte officiel du Règlement (UE) 2024/1689 (AI Act) sur EUR-Lex
- ACPR (Banque de France) : Gouvernance des algorithmes d’IA dans le secteur financier
- CNIL : Dossier thématique sur l’Intelligence Artificielle et la conformité
- Commission Européenne : Le cadre réglementaire de l’UE sur l’IA
- Wikipedia : Introduction à l’Intelligence Artificielle Explicable (XAI)

Avez-vous trouvé cet article utile ? Y a-t-il un autre sujet que vous aimeriez que je traite ?
Écrivez-le dans les commentaires ci-dessous ! Je m'inspire directement de vos suggestions.