En Bref (TL;DR)
Le paradigme Data Lakehouse modernise le credit scoring en unifiant la gestion des données structurées et non structurées dans une infrastructure unique et évolutive.
L’extraction de valeur à partir de sources hétérogènes comme les documents et les logs se fait via des pipelines NLP avancés qui transforment les informations brutes en features prédictives.
L’architecture en couches intégrée avec Feature Store garantit la gouvernance des données et l’alignement entre l’entraînement des modèles et l’inférence en temps réel.
Le diable est dans les détails. 👇 Continuez à lire pour découvrir les étapes critiques et les conseils pratiques pour ne pas vous tromper.
Dans le paysage fintech de 2026, la capacité à évaluer le risque de crédit ne dépend plus seulement de l’historique des paiements ou du solde du compte courant. La frontière moderne est le data lakehouse credit scoring, une approche architecturale qui dépasse la dichotomie entre Data Warehouse (excellents pour les données structurées) et Data Lake (nécessaires pour les données non structurées). Ce guide technique explore comment concevoir une infrastructure capable d’ingérer, de traiter et de servir des données hétérogènes pour alimenter des modèles de Machine Learning de nouvelle génération.

L’Évolution du Credit Scoring : Au-delà des Données Tabulaires
Traditionnellement, le credit scoring reposait sur des modèles de régression logistique alimentés par des données rigidement structurées provenant des Core Banking Systems. Cependant, cette approche ignore une mine d’or d’informations : les données non structurées. Les e-mails de support, les logs de chat, les documents PDF de bilan et même les métadonnées de navigation offrent des signaux prédictifs cruciaux sur la stabilité financière d’un client ou sa propension au départ (churn).
Le paradigme du Data Lakehouse émerge comme la solution définitive. En unissant la flexibilité du stockage à faible coût (comme Amazon S3 ou Google Cloud Storage) aux capacités transactionnelles et de gestion des métadonnées typiques des Warehouses (via des technologies comme Delta Lake, Apache Iceberg ou Apache Hudi), il est possible de créer une Single Source of Truth pour le credit scoring avancé.
Architecture de Référence pour le Credit Scoring 2.0
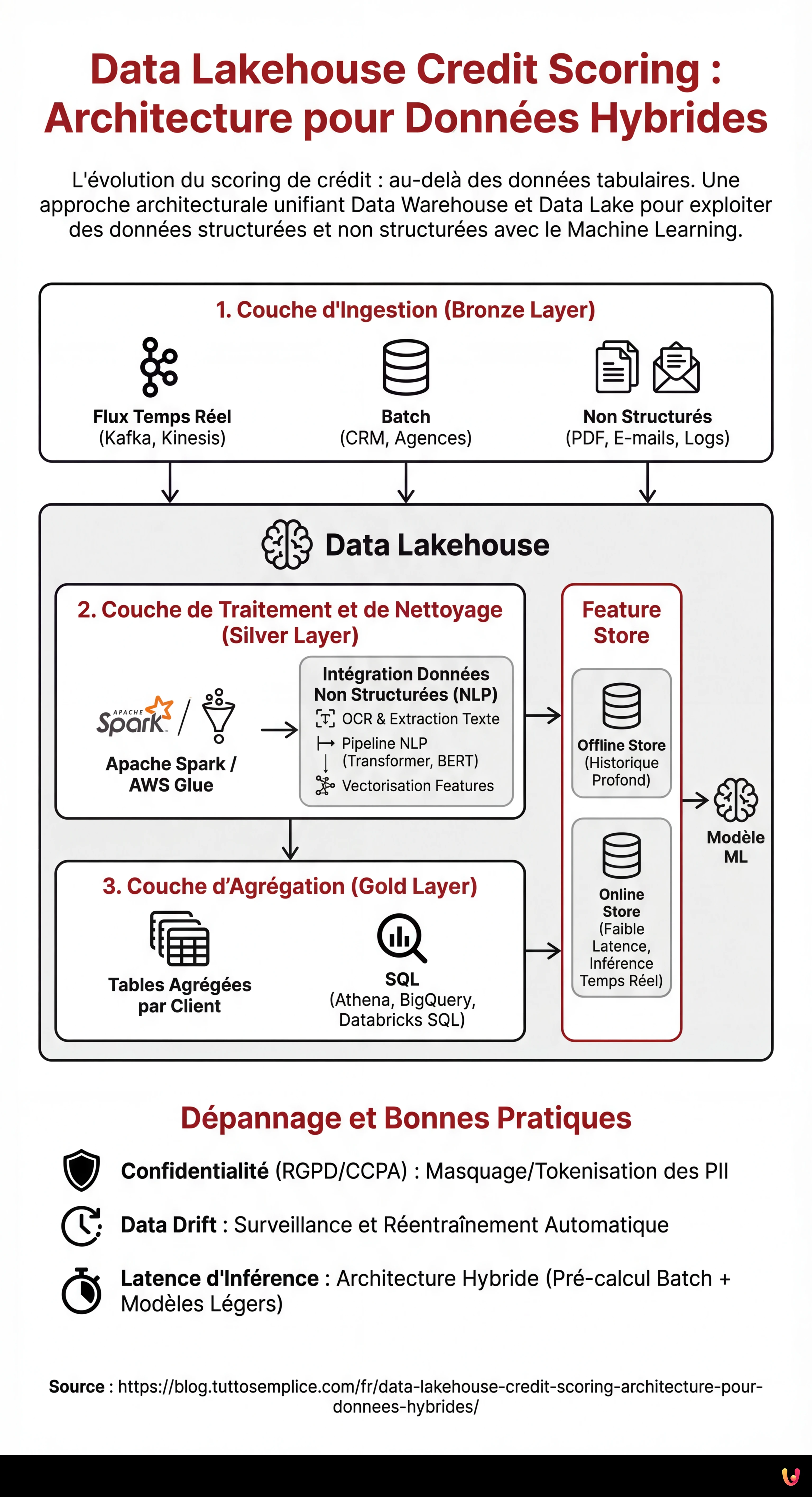
Pour construire un système efficace, nous devons définir une architecture en couches garantissant l’évolutivité et la gouvernance. Voici les composants fondamentaux :
1. Couche d’Ingestion (Bronze Layer)
Les données atterrissent dans le Lakehouse dans leur format natif. Dans un scénario de credit scoring, nous aurons :
- Flux en temps réel : Transactions TPE, clickstream de l’application mobile (via Apache Kafka ou Amazon Kinesis).
- Batch : Dumps quotidiens du CRM, rapports d’agences de crédit externes.
- Non Structurés : PDF de fiches de paie, e-mails, enregistrements de centres d’appels.
2. Couche de Traitement et de Nettoyage (Silver Layer)
C’est ici que la magie de l’ETL/ELT opère. En utilisant des moteurs distribués comme Apache Spark ou des services gérés comme AWS Glue, les données sont nettoyées, dédupliquées et normalisées. C’est à cette étape que les données non structurées sont transformées en features exploitables.
3. Couche d’Agrégation (Gold Layer)
Les données sont prêtes pour la consommation business et l’analyse, organisées en tables agrégées par client, prêtes à être interrogées via SQL (ex. Athena, BigQuery ou Databricks SQL).
Intégration des Données Non Structurées : Le Défi NLP
La véritable innovation dans le data lakehouse credit scoring réside dans l’extraction de features à partir de textes et d’images. Nous ne pouvons pas insérer un PDF dans un modèle XGBoost, nous devons donc le traiter dans le Silver Layer.
Supposons que nous voulions analyser les e-mails échangés avec le service client pour détecter des signes de stress financier. Le processus prévoit :
- OCR et Extraction de Texte : Utilisation de bibliothèques comme Tesseract ou de services cloud (AWS Textract) pour convertir PDF/Images en texte.
- Pipeline NLP : Application de modèles Transformer (ex. BERT finetuned pour le domaine financier) pour extraire des entités (NER) ou analyser le sentiment.
- Vectorisation des Features : Conversion du résultat en vecteurs numériques ou scores catégoriels (ex. “Sentiment_Score_Last_30_Days”).
Le Rôle Crucial du Feature Store
L’un des problèmes les plus courants en MLOps est le training-serving skew : les features calculées lors de l’entraînement du modèle diffèrent de celles calculées en temps réel lors de l’inférence (lorsque le client demande un prêt depuis l’application). Pour résoudre ce problème, l’architecture Lakehouse doit intégrer un Feature Store (comme Feast, Hopsworks ou SageMaker Feature Store).
Le Feature Store gère deux vues :
- Offline Store : Basé sur le Data Lakehouse, il contient l’historique profond pour l’entraînement des modèles.
- Online Store : Une base de données à faible latence (ex. Redis ou DynamoDB) qui sert la dernière valeur connue des features pour l’inférence en temps réel.
Exemple Pratique : Pipeline ETL avec PySpark
Ci-dessous un exemple conceptuel de la façon dont un job Spark pourrait unir des données transactionnelles structurées avec des scores de sentiment dérivés de données non structurées au sein d’une architecture Delta Lake.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, current_timestamp
# Initialisation Spark avec support Delta Lake
spark = SparkSession.builder
.appName("CreditScoringETL")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
# 1. Chargement Données Structurées (Transactions)
df_transactions = spark.read.format("delta").load("s3://datalake/silver/transactions")
# Feature Engineering : Moyenne des transactions des 30 derniers jours
feat_avg_spend = df_transactions.groupBy("customer_id")
.agg(avg("amount").alias("avg_monthly_spend"))
# 2. Chargement Données Non Structurées Traitées (Logs Chat/Email)
# Supposons qu'une pipeline NLP précédente ait sauvegardé les scores de sentiment
df_sentiment = spark.read.format("delta").load("s3://datalake/silver/customer_sentiment")
# Feature Engineering : Sentiment moyen
feat_sentiment = df_sentiment.groupBy("customer_id")
.agg(avg("sentiment_score").alias("avg_sentiment_risk"))
# 3. Jointure pour créer le Feature Set Unifié
final_features = feat_avg_spend.join(feat_sentiment, "customer_id", "left_outer")
.fillna({"avg_sentiment_risk": 0.5}) # Gestion des nuls
# 4. Écriture dans le Feature Store (Offline Layer)
final_features.write.format("delta")
.mode("overwrite")
.save("s3://datalake/gold/credit_scoring_features")
print("Pipeline terminée : Feature Store mis à jour.")
Dépannage et Bonnes Pratiques
Lors de la mise en œuvre d’un système de data lakehouse credit scoring, il est courant de rencontrer des obstacles spécifiques. Voici comment les atténuer :
Gestion de la Confidentialité (RGPD/CCPA)
Les données non structurées contiennent souvent des PII (Informations Personnellement Identifiables) sensibles. Il est impératif de mettre en œuvre des techniques de masquage ou de tokenisation dans le Bronze Layer, avant que les données ne deviennent accessibles aux Data Scientists. Des outils comme Presidio de Microsoft peuvent automatiser l’anonymisation du texte.
Data Drift (Dérive des données)
Le comportement des clients change. Un modèle entraîné sur les données de 2024 pourrait ne pas être valide en 2026. Surveiller la distribution statistique des features dans le Feature Store est essentiel pour déclencher le réentraînement automatique des modèles.
Latence dans l’Inférence
Si le calcul des features non structurées (ex. analyse d’un PDF téléchargé à l’instant) est trop lent, l’expérience utilisateur en pâtit. Dans ces cas, une architecture hybride est recommandée : pré-calculer tout ce qui est possible en batch (historique) et utiliser des modèles NLP légers et optimisés (ex. DistilBERT sur ONNX) pour le traitement en temps réel.
Conclusions

Adopter une approche Data Lakehouse pour le credit scoring n’est pas seulement une mise à jour technologique, mais un avantage concurrentiel stratégique. En centralisant les données structurées et non structurées et en garantissant leur cohérence via un Feature Store, les institutions financières peuvent construire des profils de risque holistiques, réduisant les défauts de paiement et personnalisant l’offre pour le client. La clé du succès réside dans la qualité de la pipeline d’ingénierie des données : un modèle IA ne vaut que ce que valent les données qui l’alimentent.
Foire aux questions

Le Data Lakehouse Credit Scoring est un modèle architectural hybride qui dépasse les limites des Data Warehouses traditionnels en unissant la gestion des données structurées à la flexibilité des Data Lakes. Cette approche permet aux fintechs d’exploiter des sources non structurées, comme les e-mails et les documents, pour calculer le risque de crédit avec une plus grande précision, réduisant ainsi la dépendance aux seuls historiques de paiement.
Les données non structurées, comme les PDF ou les logs de chat, sont traitées dans le Silver Layer via des pipelines de NLP et d’OCR. Ces technologies convertissent le texte et les images en vecteurs numériques ou en scores de sentiment, transformant des informations qualitatives en features quantitatives que les modèles prédictifs peuvent analyser pour évaluer la fiabilité du client.
Le Feature Store agit comme un système central pour garantir la cohérence des données entre la phase d’entraînement et celle d’inférence. Il élimine le désalignement connu sous le nom de training-serving skew en maintenant deux vues synchronisées : un Offline Store pour l’historique profond et un Online Store à faible latence pour fournir des données mises à jour en temps réel lors des demandes de crédit.
L’infrastructure s’organise en trois stades principaux : le Bronze Layer pour l’ingestion des données brutes, le Silver Layer pour le nettoyage et l’enrichissement via des algorithmes de traitement, et le Gold Layer où les données sont agrégées et prêtes pour l’usage business. Cette structure en couches assure l’évolutivité, la gouvernance et la qualité de la donnée tout au long du cycle de vie.
La protection des informations personnelles se fait en mettant en œuvre des techniques de masquage et de tokenisation directement au niveau de l’ingestion, le Bronze Layer. En utilisant des outils spécifiques pour l’anonymisation automatique, il est possible d’analyser les comportements et les tendances à partir des données non structurées sans exposer les identités des clients ni violer des réglementations comme le RGPD.

Avez-vous trouvé cet article utile ? Y a-t-il un autre sujet que vous aimeriez que je traite ?
Écrivez-le dans les commentaires ci-dessous ! Je m'inspire directement de vos suggestions.