Em Resumo (TL;DR)
A automação através de NLP transforma a qualificação de leads imobiliários, superando os formulários estáticos para extrair dados precisos de conversas naturais.
O fine-tuning de modelos BERT permite criar sistemas NER personalizados capazes de identificar montantes, profissões e tipologias imobiliárias.
A normalização dos dados extraídos e a integração direta no CRM BOMA otimizam o cálculo do rating de crédito e a gestão comercial.
O diabo está nos detalhes. 👇 Continue lendo para descobrir os passos críticos e as dicas práticas para não errar.
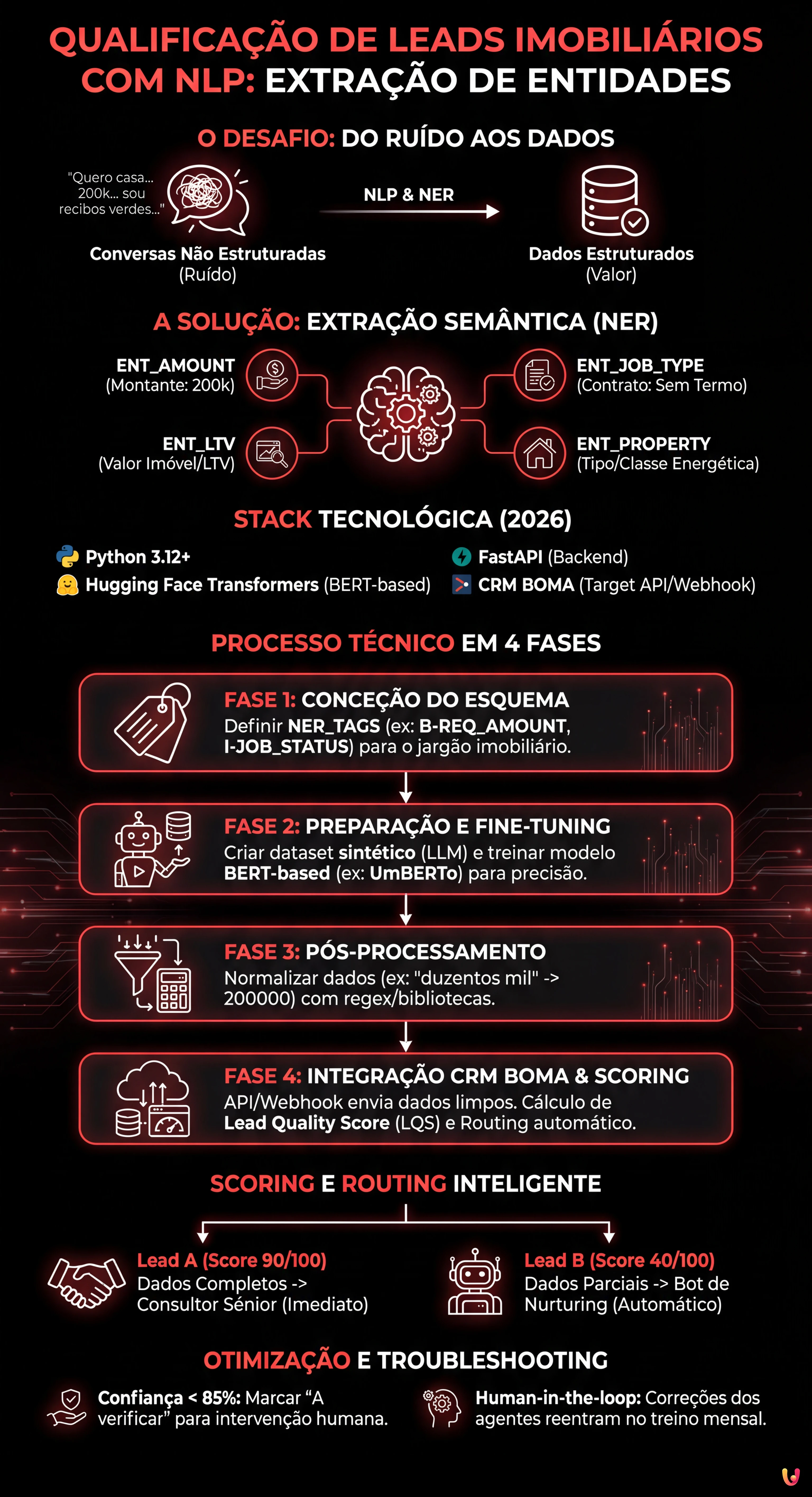
No panorama competitivo de 2026, a velocidade de resposta já não é o único fator determinante no setor do crédito e do imobiliário. O verdadeiro desafio reside na precisão e na capacidade de filtrar o ruído. A qualificação de leads imobiliários passou de uma tarefa manual realizada por call centers para um processo automatizado guiado por algoritmos de Processamento de Linguagem Natural (NLP). Neste guia técnico, exploraremos como construir um sistema de Named Entity Recognition (NER) personalizado para extrair dados estruturados de conversas não estruturadas e integrá-los diretamente no CRM BOMA.

Porque é que a Extração de Entidades muda a Qualificação de Leads Imobiliários
Os formulários estáticos nos websites (Nome, Apelido, Telefone) têm taxas de conversão cada vez mais baixas. Os utilizadores preferem interagir através de chats naturais ou mensagens de voz. No entanto, isto gera dados não estruturados difíceis de processar. É aqui que entra a Extração de Entidades Semântica.
O objetivo não é apenas entender a intenção (ex: “quero um crédito habitação”), mas extrair slots específicos de informação necessários para o cálculo do rating de crédito ou a viabilidade da compra. Um sistema bem concebido deve identificar:
- ENT_AMOUNT: O montante solicitado (ex: “preciso de 200k”).
- ENT_LTV: O Loan-to-Value implícito ou o valor do imóvel.
- ENT_JOB_TYPE: A tipologia contratual (ex: “sem termo”, “recibos verdes”).
- ENT_PROPERTY: Tipologia do imóvel e classe energética.
Pré-requisitos e Stack Tecnológica
Para seguir este guia, é necessário um conhecimento intermédio de Python e dos princípios de Machine Learning. Utilizaremos a seguinte stack, padronizada para 2026:
- Linguagem: Python 3.12+
- Framework NLP: Hugging Face Transformers, spaCy 4.x
- Modelos Base:
UmBERTo(para italiano) ou versões quantizadas doLlama-3-8B-Instructpara tarefas generativas. - Backend: FastAPI para a exposição do modelo.
- Target CRM: BOMA (via API REST/Webhook).
Fase 1: Conceção do Esquema das Entidades

Antes de escrever código, devemos definir o que o nosso modelo deve procurar. No contexto do crédito habitação, o jargão é específico. Um modelo genérico falharia em distinguir entre “entrada” e “prestação”.
Definimos as etiquetas para o nosso dataset de treino:
NER_TAGS = [
"O", # Outside (nenhuma entidade)
"B-REQ_AMOUNT", # Início montante solicitado
"I-REQ_AMOUNT", # Interno montante solicitado
"B-JOB_STATUS", # Início estado laboral
"I-JOB_STATUS", # Interno estado laboral
"B-PROPERTY_VAL", # Valor do imóvel
"B-INTENT_TIME" # Prazo desejado (ex: "escritura até março")
]
Fase 2: Preparação do Dataset e Fine-Tuning
Para obter uma qualificação de leads imobiliários precisa, não podemos confiar em modelos generalistas zero-shot para a extração massiva, pois são dispendiosos e lentos. A melhor solução é o fine-tuning de um modelo BERT-based.
1. Criação do Dataset Sintético
Se não dispuserem de históricos de chat compatíveis com o RGPD, podem gerar um dataset sintético utilizando um LLM (como o Meta AI Llama 3) para criar milhares de variações de frases típicas:
“Sou funcionário público e procuro um crédito para uma casa de 250.000 euros, tenho 50k de entrada.”
Anotem estas frases no formato JSONL padrão para o treino (formato BIO).
2. Fine-Tuning com Hugging Face
Utilizaremos o dbmdz/bert-base-italian-xxl-cased como base, sendo um dos modelos com melhor desempenho na sintaxe italiana (adaptável para modelos portugueses equivalentes). Eis um snippet simplificado para o loop de treino:
from transformers import AutoTokenizer, AutoModelForTokenClassification, TrainingArguments, Trainer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=len(NER_TAGS))
args = TrainingArguments(
output_dir="./boma-ner-v1",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
num_train_epochs=5,
weight_decay=0.01,
)
# Assumindo que 'tokenized_datasets' já está preparado
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
)
trainer.train()
Este processo adapta os pesos do modelo para reconhecer especificamente termos como “transferência”, “taxa fixa” ou “consultor” no contexto da frase.
Fase 3: Pós-Processamento e Normalização
O modelo NER devolve tokens e etiquetas. Para a qualificação de leads imobiliários, devemos transformar "duzentos mil euros" em 200000 (Integer). Esta fase de normalização é crítica para povoar a base de dados.
Utilizamos bibliotecas como word2number ou regex personalizadas para limpar o output do modelo antes do envio para o CRM.
Fase 4: Integração no CRM BOMA
Uma vez que o modelo esteja exposto via API (ex: num contentor Docker), devemos ligá-lo ao fluxo de entrada dos leads. A integração com o BOMA ocorre geralmente através de webhooks que disparam na receção de uma nova mensagem.
Lógica de Scoring e Routing
Nem todos os leads são iguais. Utilizando os dados extraídos, podemos calcular um Lead Quality Score (LQS) em tempo real:
- Lead A (Score 90/100): Dados completos (Trabalho, Montante, Imóvel), LTV Encaminhamento imediato para o Consultor Sénior.
- Lead B (Score 40/100): Dados parciais, LTV > 95%, Contrato a Termo. -> Encaminhamento para o Bot de Nurturing automático.
Eis um exemplo de payload JSON para enviar às APIs do BOMA:
{
"lead_source": "Whatsapp_Business",
"message_body": "Olá, queria info para crédito primeira habitação, sou enfermeiro",
"extracted_data": {
"job_type": "enfermeiro",
"job_category": "funcao_publica",
"intent": "compra_primeira_habitacao"
},
"ai_score": 75,
"routing_action": "assign_to_human"
}
Troubleshooting: Gestão de Alucinações e Ambiguidade
Mesmo os melhores modelos podem falhar. Eis como mitigar os riscos:
- Confidence Threshold: Se o modelo extrair uma entidade com uma confiança inferior a 85%, o sistema deve marcar o campo como “A verificar” no CRM BOMA, exigindo a intervenção humana.
- Human-in-the-loop: Implementar um mecanismo de feedback onde os agentes imobiliários possam corrigir a etiquetagem no CRM. Estes dados corrigidos devem reentrar no dataset de treino para o re-treino mensal do modelo.
- Gestão de Dialetos: Treinar o modelo em datasets que incluam expressões coloquiais regionais frequentemente usadas nos chats informais.
Conclusões

A implementação de um sistema de Extração de Entidades para a qualificação de leads imobiliários já não é um exercício académico, mas uma necessidade operacional. Ao automatizar a extração dos dados críticos (LTV, trabalho, orçamento) e integrá-los diretamente no BOMA, as agências podem reduzir o tempo de primeiro contacto de horas para segundos, atribuindo os processos mais complexos aos melhores consultores e deixando para a IA a gestão da triagem inicial.
Perguntas frequentes

Trata-se de um processo baseado em NLP que identifica e extrai dados específicos, como o montante do crédito ou o tipo de contrato, a partir de conversas naturais e não estruturadas. Ao contrário dos formulários estáticos, esta tecnologia permite compreender a intenção do utilizador e preencher automaticamente os campos necessários para o cálculo do rating de crédito diretamente no CRM.
Para obter um elevado desempenho na sintaxe (seja italiana ou portuguesa), a melhor escolha recai sobre o fine-tuning de modelos BERT-based como o UmBERTo ou equivalentes. Estes modelos são superiores às soluções generalistas zero-shot porque podem ser treinados para reconhecer o jargão específico do setor do crédito, distinguindo termos técnicos como «prestação», «entrada» ou «transferência de crédito».
Ao integrar um modelo de extração de entidades via API ou Webhook, o BOMA pode receber dados já limpos e normalizados. Isto permite atribuir uma pontuação de qualidade ao lead em tempo real e encaminhar automaticamente os contactos: os perfis completos vão para os consultores seniores, enquanto os parciais são geridos por bots de nurturing, otimizando o tempo da equipa de vendas.
Um sistema bem concebido extrai entidades críticas como o montante solicitado, o valor do imóvel para o cálculo do Loan-to-Value, a tipologia contratual laboral e a classe energética da casa. Estes dados, definidos como slots informativos, são essenciais para determinar imediatamente a viabilidade do processo sem longas entrevistas preliminares.
É necessário implementar um limiar de confiança, por exemplo de 85 por cento, abaixo do qual o sistema sinaliza o dado como «A verificar» manualmente. Além disso, adota-se uma abordagem human-in-the-loop onde as correções efetuadas pelos agentes imobiliários são guardadas e reutilizadas para o re-treino periódico do modelo, melhorando a sua precisão ao longo do tempo.
Fontes e Aprofundamento


Achou este artigo útil? Há outro assunto que gostaria de me ver abordar?
Escreva nos comentários aqui em baixo! Inspiro-me diretamente nas vossas sugestões.