Em Resumo (TL;DR)
A arquitetura RAG potencia os CRMs financeiros consultando regulamentações e dados de clientes em tempo real para gerar respostas precisas e livres de alucinações.
A pipeline técnica integra ingestion semântica, bases de dados vetoriais e prompt engineering para transformar documentos complexos em consultorias financeiras seguras e totalmente rastreáveis.
O uso estratégico de pgvector e chunking avançado permite construir assistentes virtuais capazes de pré-qualificar leads e gerir créditos habitação garantindo a compliance.
O diabo está nos detalhes. 👇 Continue lendo para descobrir os passos críticos e as dicas práticas para não errar.
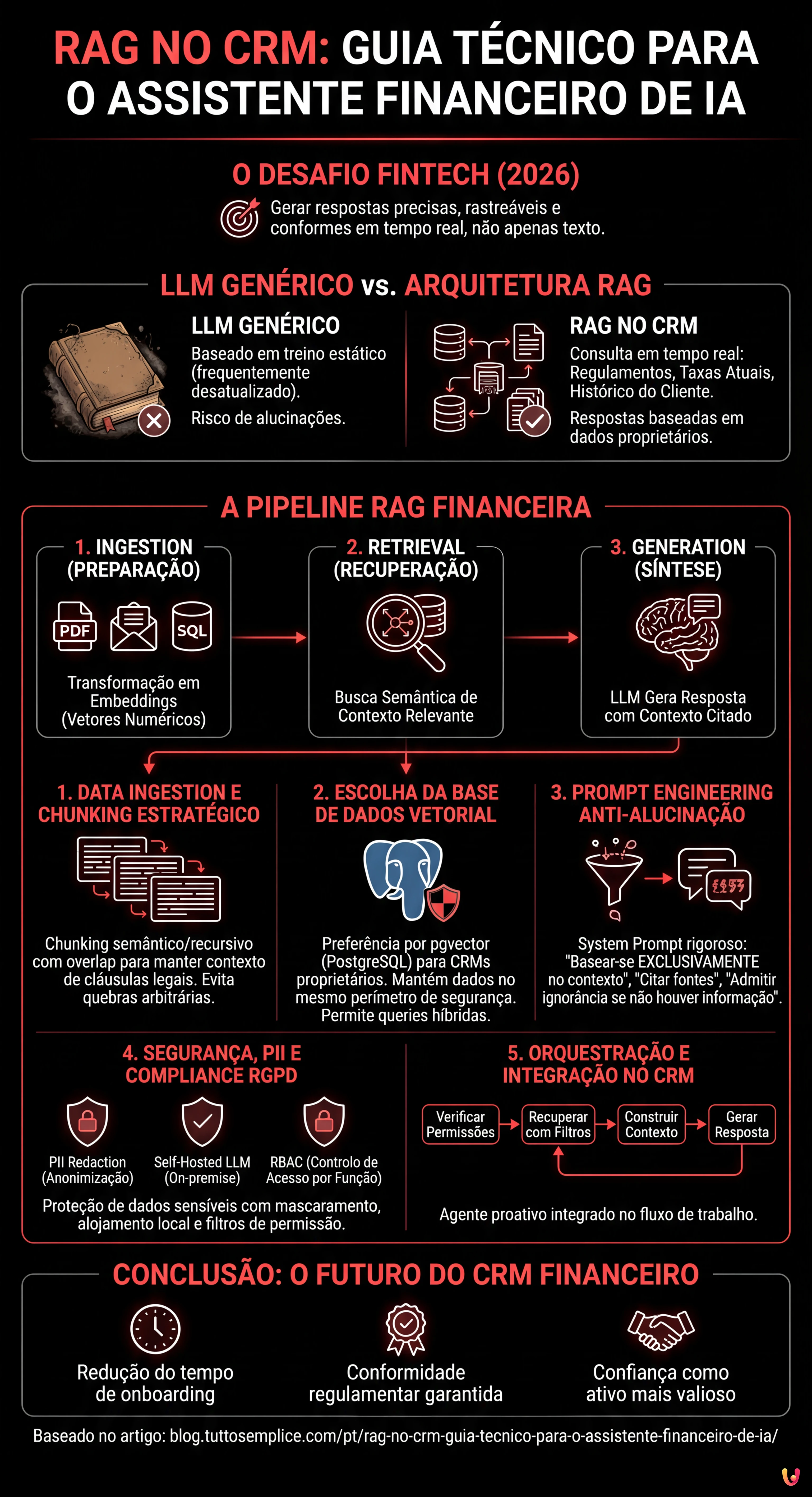
Estamos em 2026 e a integração da Inteligência Artificial nos sistemas empresariais já não é uma novidade, mas um padrão operacional. No entanto, no setor fintech e imobiliário, o desafio não é apenas gerar texto, mas gerar respostas precisas, rastreáveis e conformes. É aqui que entra a arquitetura RAG no CRM (Retrieval-Augmented Generation). Ao contrário de um LLM genérico que se baseia apenas no seu conjunto de treino (muitas vezes desatualizado), um sistema RAG permite que o vosso CRM proprietário (como o BOMA ou soluções personalizadas) consulte em tempo real a documentação regulamentar, as taxas de juro atuais e o histórico do cliente antes de formular uma resposta.
Neste deep dive técnico, exploraremos como construir um assistente financeiro inteligente capaz de pré-qualificar leads e fornecer consultoria sobre crédito habitação, minimizando as alucinações e garantindo a máxima segurança dos dados.

A Arquitetura RAG no Contexto Financeiro
A implementação da RAG no CRM requer uma pipeline robusta composta por três fases principais: Ingestion (preparação dos dados), Retrieval (recuperação semântica) e Generation (síntese da resposta). No contexto de um CRM financeiro, os dados não são apenas texto livre, mas uma combinação de:
- Dados Não Estruturados: PDF de regulamentações bancárias, políticas de crédito, transcrições de emails.
- Dados Estruturados: Registos de clientes, scoring de crédito, rácios LTV (Loan-to-Value) presentes na base de dados SQL.
O objetivo é transformar estes dados em vetores numéricos (embedding) que o LLM possa “compreender” e interrogar.
Passo 1: Data Ingestion e Chunking Estratégico
O primeiro passo é a transformação da documentação (ex: “Guia de Crédito Habitação 2026.pdf”) em fragmentos geríveis. Não podemos passar um manual inteiro de 500 páginas na janela de contexto do LLM. Devemos dividir o texto em chunks.
Para documentos financeiros, um chunking baseado puramente nos caracteres é arriscado porque pode partir uma cláusula legal a meio. Utilizamos uma abordagem semântica ou recursiva.
Exemplo de Código: Pipeline de Ingestion com LangChain
Eis como implementar uma função Python para processar os documentos e criar embeddings utilizando OpenAI (ou modelos open-source equivalentes).
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
import os
# Configuração da API Key (gerida via variáveis de ambiente para segurança)
os.environ["OPENAI_API_KEY"] = "sk-..."
def process_financial_docs(file_path):
# 1. Carregamento do documento
loader = PyPDFLoader(file_path)
docs = loader.load()
# 2. Chunking Estratégico
# Chunk size de 1000 tokens com overlap de 200 para manter o contexto entre os fragmentos
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["nn", "n", " ", ""]
)
splits = text_splitter.split_documents(docs)
# 3. Criação dos Embeddings
# Utilizamos text-embedding-3-small para um bom equilíbrio custo/performance
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
return splits, embeddingsPasso 2: Escolha e Gestão da Base de Dados Vetorial

Uma vez criados os embeddings, onde os arquivamos? A escolha da base de dados vetorial é crítica para o desempenho da RAG no CRM.
- Pinecone: Solução gerida (SaaS). Ótima para escalabilidade e velocidade, mas os dados residem em clouds de terceiros. Ideal se a política da empresa o permitir.
- pgvector (PostgreSQL): A escolha preferida para os CRMs proprietários que já usam Postgres. Permite executar queries híbridas (ex: “encontra documentos semanticamente semelhantes” AND “pertencentes ao cliente ID=123”).
Se estivermos a construir um assistente financeiro interno, o pgvector oferece a vantagem de manter os dados vetoriais no mesmo perímetro de segurança dos dados financeiros estruturados.
Passo 3: Retrieval e Prompt Engineering Anti-Alucinação
O coração do sistema é a recuperação das informações pertinentes. Quando um operador pergunta ao CRM: “O cliente Silva pode aceder ao Crédito Jovem com um ISEE de 35k?”, o sistema deve recuperar as políticas relativas ao “Crédito Jovem” e os limites de rendimento.
No entanto, recuperar os dados não basta. Devemos instruir o LLM a não inventar. Isto obtém-se através de um System Prompt rigoroso.
Exemplo de Prompt Engineering Avançado
Utilizamos um template que força o modelo a citar as fontes ou a admitir a ignorância.
SYSTEM_PROMPT = """
És um Assistente Financeiro Sénior integrado no CRM BOMA.
A tua tarefa é responder às perguntas baseando-te EXCLUSIVAMENTE no contexto fornecido abaixo.
REGRAS OPERACIONAIS:
1. Se a resposta não estiver presente no contexto, deves responder: "Lamento, as políticas atuais não cobrem este caso específico."
2. Não inventes taxas de juro ou regras não escritas.
3. Cita sempre o documento de referência (ex: [Política Crédito v2.4]).
4. Mantém um tom profissional e formal.
CONTEXTO:
{context}
PERGUNTA UTILIZADOR:
{question}
"""Passo 4: Segurança, PII e Compliance RGPD
Integrar a RAG no CRM financeiro acarreta riscos enormes ligados à privacidade. Não podemos enviar dados sensíveis (PII – Personally Identifiable Information) como Números de Contribuinte, nomes completos ou saldos bancários diretamente para as APIs da OpenAI ou Anthropic sem precauções, especialmente sob o RGPD.
Estratégias de Proteção (Guardrails)
- PII Redaction (Anonimização): Antes de enviar o prompt ao LLM, utilizar bibliotecas como Microsoft Presidio para identificar e mascarar os dados sensíveis. “Mário Silva” torna-se “<PERSON>”.
- Self-Hosted LLM: Para a máxima segurança, avaliar o uso de modelos open-source como Llama 3 ou Mistral, alojados em servidores proprietários (on-premise ou VPC privada). Isto garante que nenhum dado deixe a infraestrutura da empresa.
- Role-Based Access Control (RBAC): O sistema RAG deve respeitar as permissões do CRM. Um agente júnior não deve poder interrogar vetores relativos a documentos reservados da direção. Este filtro é aplicado ao nível da query na base de dados vetorial (Metadata Filtering).
Passo 5: Orquestração e Integração no CRM
A última peça é a integração no frontend do CRM. O assistente não deve ser apenas um chat, mas um agente proativo. Eis um exemplo lógico de como estruturar a chamada:
def get_crm_answer(user_query, user_id):
# 1. Verificação de permissões do utilizador
user_permissions = db.get_permissions(user_id)
# 2. Recuperação de documentos pertinentes (Retrieval) com filtros de segurança
docs = vector_store.similarity_search(
user_query,
k=3,
filter={"access_level": {"$in": user_permissions}}
)
# 3. Construção do contexto
context_text = "nn".join([d.page_content for d in docs])
# 4. Geração da Resposta (Generation)
response = llm_chain.invoke({"context": context_text, "question": user_query})
return responseConclusões: O Futuro do CRM Financeiro
Implementar a RAG no CRM transforma uma base de dados estática num consultor dinâmico. Para as instituições financeiras, isto significa reduzir os tempos de onboarding dos novos colaboradores (que têm acesso instantâneo a toda a knowledge base da empresa) e garantir que cada resposta dada ao cliente esteja em conformidade com as últimas regulamentações vigentes.
A chave do sucesso não reside no modelo mais potente, mas na qualidade da pipeline de dados e na rigidez dos protocolos de segurança. Em 2026, a confiança é o ativo mais valioso, e uma arquitetura RAG bem desenhada é a melhor ferramenta para a preservar.
Perguntas frequentes

Enquanto um LLM genérico se baseia em dados de treino estáticos e muitas vezes desatualizados, uma arquitetura RAG (Retrieval-Augmented Generation) integrada no CRM permite consultar em tempo real documentos da empresa, taxas de juro atuais e histórico de clientes. Esta abordagem garante respostas baseadas em dados proprietários atualizados, reduzindo o risco de informações obsoletas e melhorando a conformidade regulamentar nas consultorias financeiras.
A proteção dos dados pessoais ocorre através de várias estratégias defensivas. É essencial aplicar técnicas de PII Redaction para anonimizar nomes e números fiscais antes que cheguem ao modelo de IA. Além disso, o uso de modelos open-source alojados em servidores proprietários e a implementação de controlos de acesso baseados em funções (RBAC) asseguram que as informações sensíveis não deixem a infraestrutura da empresa e sejam acessíveis apenas ao pessoal autorizado.
Para documentos legais e financeiros, a divisão do texto baseada puramente nos caracteres é desaconselhada, pois corre o risco de partir cláusulas importantes. A estratégia ideal prevê um chunking semântico ou recursivo, que mantém unidos os parágrafos lógicos e utiliza um sistema de sobreposição (overlap) entre os fragmentos. Este método preserva o contexto necessário para que a inteligência artificial possa interpretar corretamente as regulamentações durante a fase de recuperação.
A utilização do pgvector no PostgreSQL é frequentemente preferível para os CRMs proprietários porque permite manter os dados vetoriais (embedding) no mesmo perímetro de segurança dos dados estruturados dos clientes. Ao contrário das soluções SaaS externas, esta configuração facilita a execução de queries híbridas que combinam a pesquisa semântica com filtros SQL tradicionais, oferecendo um maior controlo sobre a privacidade e reduzindo a latência de rede.
O Prompt Engineering avançado atua como um filtro de segurança, instruindo o modelo a basear-se exclusivamente no contexto fornecido. Através de um System Prompt rigoroso, impõe-se ao assistente que cite as fontes documentais específicas para cada afirmação e que admita explicitamente a ignorância se a resposta não estiver presente nas políticas da empresa, impedindo assim a geração de taxas ou regras financeiras inexistentes.
Fontes e Aprofundamento


Achou este artigo útil? Há outro assunto que gostaria de me ver abordar?
Escreva nos comentários aqui em baixo! Inspiro-me diretamente nas vossas sugestões.