In Brief (TL;DR)
The European AI Act classifies credit scoring as a high-risk system, imposing strict transparency and explainability obligations.
Data Scientists must abandon black-box models by adopting Explainable AI libraries like SHAP to ensure interpretable and mathematically consistent decisions.
Integrating tools like AWS SageMaker Clarify into MLOps pipelines allows for automating regulatory compliance by monitoring bias and explainability in production.
The devil is in the details. 👇 Keep reading to discover the critical steps and practical tips to avoid mistakes.
It is 2026 and the European Fintech landscape has radically changed. With the full implementation of the European Artificial Intelligence Act, adapting ai act credit scoring systems is no longer a competitive differentiator, but a legal imperative. Creditworthiness assessment systems are classified as High-Risk AI Systems under Annex III of the AI Act. This imposes strict obligations regarding transparency and explainability (Article 13).
For CTOs, Data Scientists, and MLOps engineers, this means the end of inscrutable “black-box” models. It is no longer enough for an XGBoost model or a Neural Network to have an AUC (Area Under Curve) of 0.95; they must be able to explain why a mortgage was refused to a specific client. This technical guide explores the implementation of Explainable AI (XAI) in production pipelines, bridging the gap between regulatory compliance and software engineering.

The Transparency Requirement in the AI Act for Fintech
The AI Act establishes that high-risk systems must be designed so that their operation is sufficiently transparent to allow users to interpret the system’s output. In the context of credit scoring, this translates into two levels of explainability:
- Global Explainability: Understanding how the model works as a whole (which features carry the most weight overall).
- Local Explainability: Understanding why the model made a specific decision for a single individual (e.g., “The mortgage was refused because the debt-to-income ratio exceeds 40%”).
The technical goal is to transform complex mathematical vectors into understandable and legally defensible Adverse Action Notices.
Prerequisites and Tech Stack
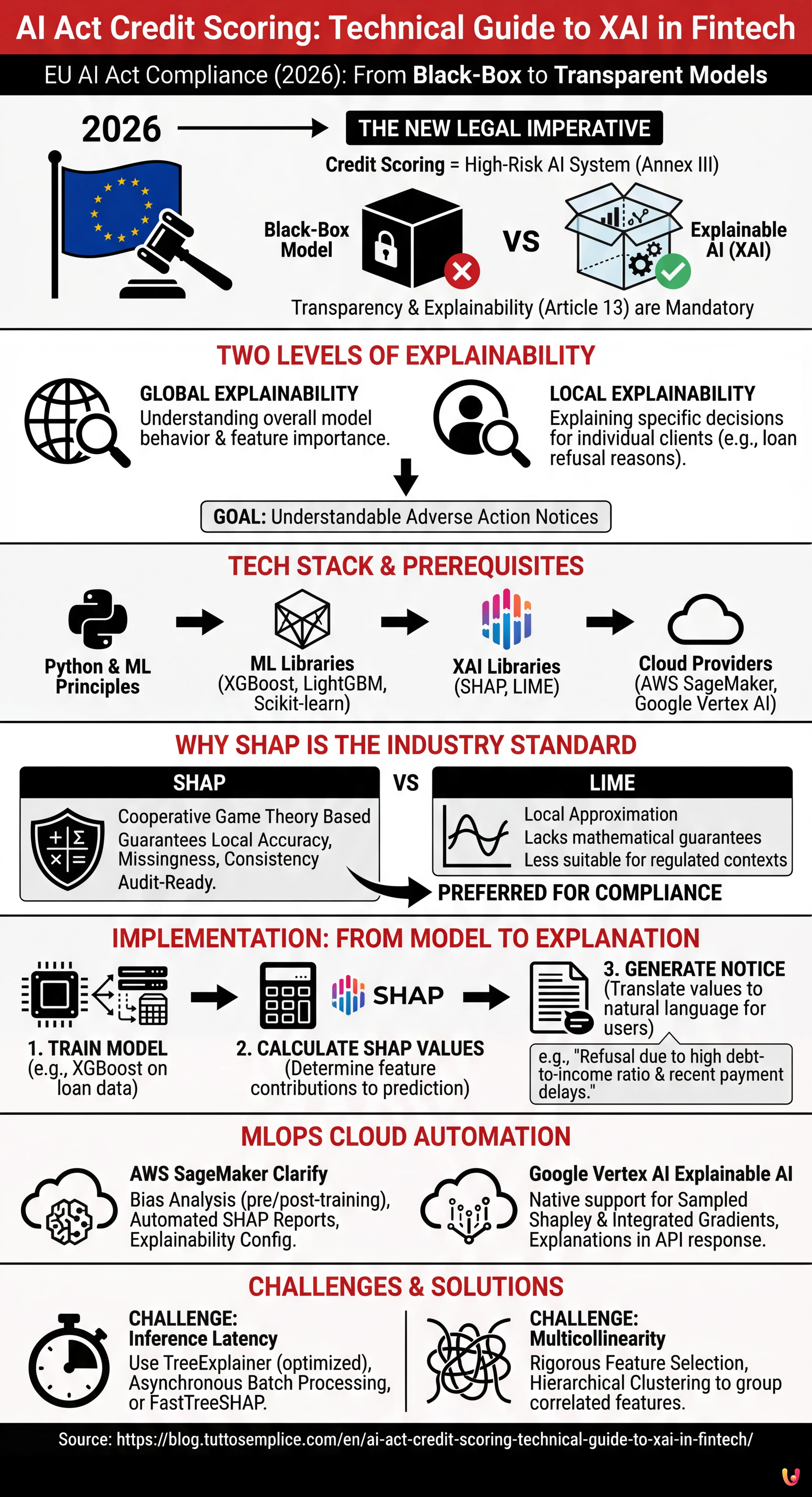
To follow this implementation guide, knowledge of Python and basic Machine Learning principles is assumed. The reference stack includes:
- ML Libraries: Scikit-learn, XGBoost, or LightGBM (de facto standards for tabular data in credit scoring).
- XAI Libraries: SHAP (SHapley Additive exPlanations) and LIME.
- Cloud Providers: AWS SageMaker or Google Vertex AI (for MLOps orchestration).
Abandoning the Black-Box: SHAP vs LIME

Although inherently interpretable models exist (such as logistic regressions or shallow Decision Trees), they often sacrifice predictive accuracy. The modern solution is the use of complex models (ensemble methods) combined with model-agnostic interpretation methods.
Why Choose SHAP for Credit Scoring
Among various options, SHAP has become the industry standard for the banking sector. Unlike LIME, which approximates the model locally, SHAP is based on cooperative game theory and guarantees three fundamental mathematical properties: local accuracy, missingness, and consistency. In a regulated context like ai act credit scoring, the mathematical consistency of SHAP offers greater assurance in the event of an audit.
Step-by-Step Implementation: From XGBoost to SHAP
Below is a practical example of how to integrate SHAP into a risk scoring model.
1. Model Training
Let’s assume we have trained an XGBoost classifier on a loan application dataset.
import xgboost as xgb
import shap
import pandas as pd
# Data loading and training (simplified)
X, y = shap.datasets.adult() # Example dataset
model = xgb.XGBClassifier().fit(X, y)2. Calculating SHAP Values
Instead of limiting ourselves to the prediction, we calculate the Shapley values for each instance. These values indicate how much each feature contributed to shifting the prediction relative to the dataset average (base value).
# Explainer initialization
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
# Example: Explanation for client ID 0
print(f"Base Value: {explainer.expected_value}")
print(f"SHAP Values Client 0: {shap_values[0]}")If the Base Value (average default probability) is 0.20 and the prediction for the client is 0.65, the SHAP values will tell us exactly which variables added that +0.45 risk (e.g., +0.30 for past delays, +0.15 for low job seniority).
MLOps Cloud Integration: Automating Compliance
Running SHAP in a notebook is simple, but the AI Act requires continuous monitoring and scalable processes. Here is how to integrate XAI into cloud pipelines.
AWS SageMaker Clarify
AWS offers SageMaker Clarify, a native service that integrates into the model lifecycle. To configure it:
- Processor Configuration: During the definition of the training job, a
SageMakerClarifyProcessoris configured. - Bias Analysis: Clarify calculates pre-training bias metrics (e.g., class imbalances) and post-training metrics (e.g., accuracy disparities between demographic groups), essential for the fairness required by the AI Act.
- Explainability Report: A SHAP configuration (e.g.,
SHAPConfig) is defined, which automatically generates JSON reports for each inference endpoint.
Google Vertex AI Explainable AI
Similarly, Vertex AI allows configuring the explanationSpec during model uploading. Google natively supports Sampled Shapley and Integrated Gradients. The advantage here is that the explanation is returned directly in the API response along with the prediction, reducing latency.
Automatic Generation of Adverse Action Notices
The final step is translating the numerical SHAP values into natural language for the end customer, satisfying the notification obligation.
Let’s imagine a Python function that processes the output:
def generate_explanation(shap_values, feature_names, threshold=0.1):
explanations = []
for value, name in zip(shap_values, feature_names):
if value > threshold: # Positive contribution to risk
if name == "num_payment_delays":
explanations.append("Recent payment delays negatively impacted the score.")
elif name == "debt_to_income_ratio":
explanations.append("Your debt-to-income ratio is high.")
return explanationsThis semantic translation layer is what makes the system compliant with Article 13 of the AI Act, making the algorithm transparent to the non-technical user.
Troubleshooting and Common Challenges
When implementing explainable ai act credit scoring systems, technical obstacles are often encountered:
1. Inference Latency
Calculating SHAP values, especially the exact method on deep decision trees, is computationally expensive.
Solution: Use TreeExplainer (optimized for trees) instead of KernelExplainer. In production, calculate explanations asynchronously (batch processing) if an immediate real-time response to the user is not required, or use approximate versions like FastTreeSHAP.
2. Multicollinearity
If two features are highly correlated (e.g., “Annual Income” and “Monthly Income”), SHAP might split the importance between the two, making the explanation confusing.
Solution: Perform rigorous Feature Selection and removal of redundant features before training. Use hierarchical clustering techniques to group correlated features.
Conclusions

Adapting to the AI Act in the credit scoring sector is not just a bureaucratic exercise, but an engineering challenge that elevates the quality of financial software. By implementing XAI-based architectures like SHAP and integrating them into robust MLOps pipelines on SageMaker or Vertex AI, Fintech companies can ensure not only legal compliance but also greater consumer trust. Algorithmic transparency is the new currency of digital credit.
Frequently Asked Questions

The AI regulation classifies creditworthiness assessment systems as high-risk systems according to Annex III. This definition imposes strict transparency and explainability obligations on Fintech companies, forcing the abandonment of black-box models. It is now necessary for algorithms to provide understandable reasons for every decision made, especially in the case of a loan refusal.
Global explainability allows understanding the functioning of the model as a whole, identifying which variables carry the most weight in general. Local explainability, on the other hand, is fundamental for regulatory compliance as it clarifies why the model made a specific decision for a single customer, allowing for the generation of precise notifications regarding the causes of a negative outcome.
SHAP has become the industry standard because it is based on cooperative game theory and guarantees mathematical properties such as consistency, which is essential during an audit. Unlike LIME, which provides local approximations, SHAP calculates the exact contribution of each feature relative to the average, offering a legally more solid justification for the credit score.
To automate compliance, managed services like AWS SageMaker Clarify or Google Vertex AI can be used. These tools integrate into the model lifecycle to calculate bias metrics and automatically generate SHAP explainability reports for each inference, ensuring continuous monitoring without excessive manual intervention.
Calculating SHAP values can be computationally expensive and slow down responses. To mitigate the problem, it is recommended to use TreeExplainer which is optimized for decision trees, or to move the calculation to asynchronous batch processes if an immediate response is not needed. Another effective solution is the use of fast approximations like FastTreeSHAP.
Sources and Further Reading


Did you find this article helpful? Is there another topic you'd like to see me cover?
Write it in the comments below! I take inspiration directly from your suggestions.